









更快的SQL查询与动态文件修剪三角洲湖
有两个历史悠久的优化技术进行查询以更快的速度运行,数据系统:处理数据速度或简单的过程…
2020年4月30日 在工程的博客
有两个历史悠久的优化技术进行查询以更快的速度运行,数据系统:处理数据速度或者只是过程较少的数据通过跳过无关的数据。这篇文章介绍了动态文件修剪(DFP),一个新的data-skipping技术,可以显著提高查询与选择性连接在三角洲湖non-partition列在表上,现在在砖默认启用运行时。”
在我们的实验中使用TPC-DS数据和查询与动态文件修剪,我们观察到一个8 x加速查询性能和36查询2 x或更大的加速。
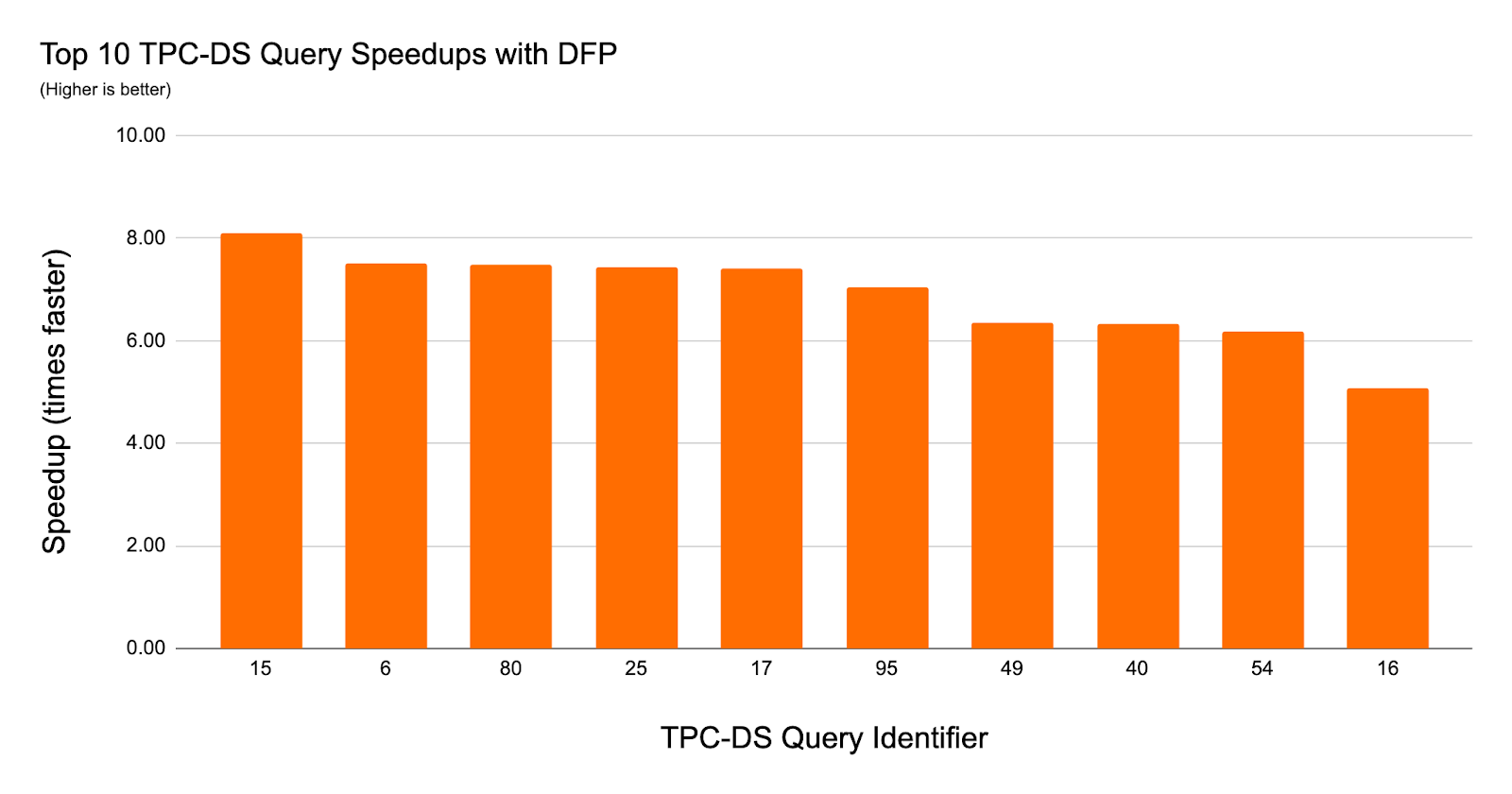
数据工程师经常选择一个划分策略对于大型三角洲湖表允许查询和跳过大量工作访问这些表的数据从而大大加快查询的执行时间。分区修剪可以发生在查询编译时查询包括一个显式的文字谓词的分区键列也可以在运行时通过举行动态分区修剪。
除了消除数据分区的粒度,三角洲湖上动态砖跳过不必要的文件在可能的情况下。这可以实现,因为三角洲湖自动收集关于数据文件元数据由三角洲湖因此,数据可以跳过没有数据文件访问。修剪修剪之前动态文件,文件只发生在查询中包含一个文本值谓词,但现在这工作文字过滤器以及加入过滤器。这意味着动态文件修剪现在允许星型模式查询利用粒度数据跳过文件。
| 每个分区 | 每个文件(仅三角洲湖在砖) | |
| 静态(基于过滤器) | 分区修剪 | 文件修剪 |
| 动态(基于连接) | 动态分区修剪 | 动态文件修剪(新!) |
在我们深入的细节动态文件修剪是如何工作的,让我们简要介绍文件如何修剪与文字谓词。
为简单起见,让我们考虑以下查询来自TPC-DS模式来解释文件修剪可以减少的大小扫描操作。
——第一季度选择总和(ss_quantity)从store_sales在哪里ss_item_sk在(40,41,42)三角洲湖店的最大和最小值每一列在每个文件的基础上。因此,文件的过滤值(40、41、42)秋季min-max范围以外的ss_item_sk列完全可以跳过。我们可以减少值的长度范围使用数据集群技术,如每个文件z值。这是很有吸引力的动态文件修剪因为有更严格的范围每个文件导致跳过效果更好。因此,我们有z值ss_item_sk store_sales表的列。
在查询Q1谓词下推发生,因此文件作为metadata-operation部分发生的修剪扫描运营商也紧随其后过滤器操作来删除任何剩余的不匹配的行。
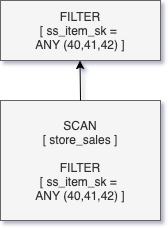
当过滤谓词包含文字,查询编译器可以嵌入这些文字值的查询计划。然而,当谓词指定作为一个连接的一部分,通常是发现在大多数数据仓库的查询(例如,星型模式加入),需要不同的方法。在这种情况下,加入过滤事实表查询编译时间未知。
下面是一个例子,与典型的星型连接查询。
——第二季度选择总和(ss_quantity)从store_sales加入项在ss_item_sk=i_item_sk在哪里i_item_id=“AAAAAAAAICAAAAAA”查询Q1 Q2返回相同的结果,不过,它指定维度表上的谓词(项),不是事实表(store_sales)。这意味着过滤的行store_sales通常做的一部分加入操作之前并不知道自ss_item_sk值后扫描和过滤器操作发生在项目表。
下面是一个逻辑Q2的查询执行计划。
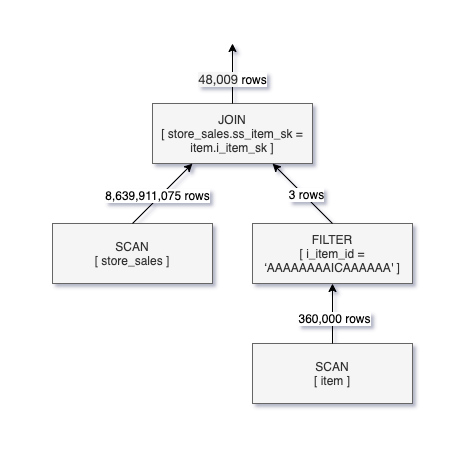
正如你所看到的在Q2的查询计划,只有48 k行满足加入标准未超过8.6 b必须从store_sales表读取记录。这意味着查询运行时可以显著减少以及扫描的数据量是否有推动下的一种方式加入过滤器进扫描store_sales。
如果我们把Q2和启用动态文件修剪我们可以看到,一个动态创建过滤器从构建的连接和传递到扫描store_sales操作。以下逻辑图代表了这种优化计划。
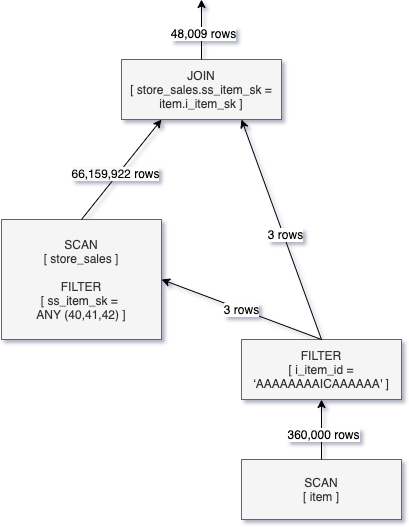
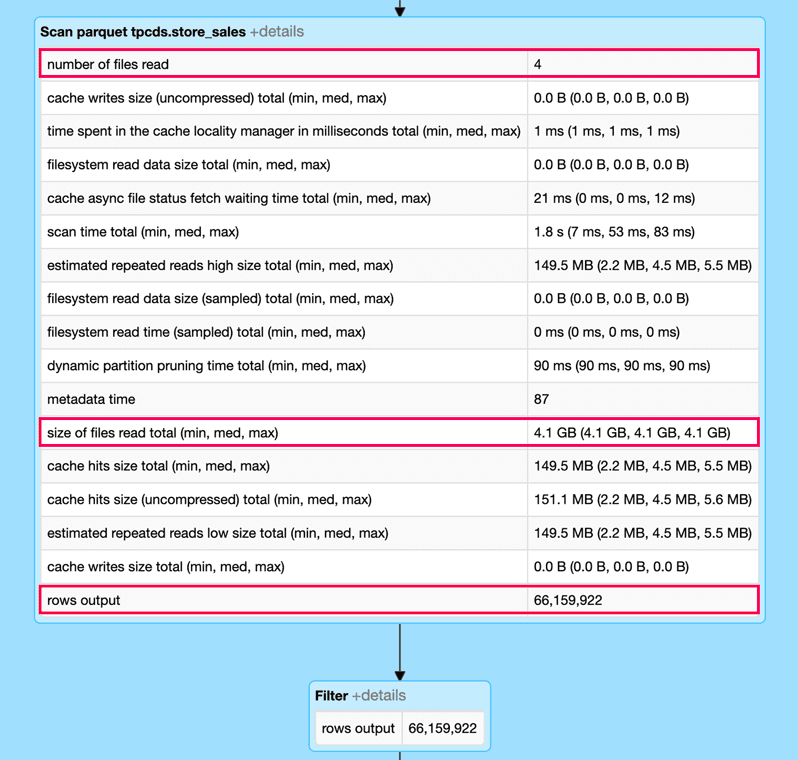
应用动态文件修剪的结果扫描操作store_sales是扫描的行数从86亿减少到6600万行。而改进是重要的,我们仍然阅读比需要更多的数据,因为DFP操作粒度的文件而不是行。
我们可以观察到的影响动态文件修剪通过观察火花的DAG UI(片段)查询和扩大扫描操作store_sales表。特别是,使用动态文件修剪这个查询中消除超过99%的输入数据,提高了查询运行时从10年代小于1。

没有动态文件修剪
与动态文件修剪
DFP在砖自动启用运行时6.1和更高版本,并应用如果查询符合下列标准:
DFP可以由下列配置参数:
注意:在本文中的实验报告我们spark.databricks.optimizer.deltaTableFilesThreshold设置为100,以触发DFP因为store_sales表有不到1000文件
理解动态文件修剪SQL工作负载的影响我们比较TPC-DS查询的性能1 tb的数据集的分区模式。我们使用z值集群与事实表的日期和项目键列。几乎每一个查询中DFP提供良好的性能。36个103查询我们观察到加速超过2 x的最大加速实现大约8 x的一个查询。下面的图表突出的影响DFP通过展示十大最改进查询。
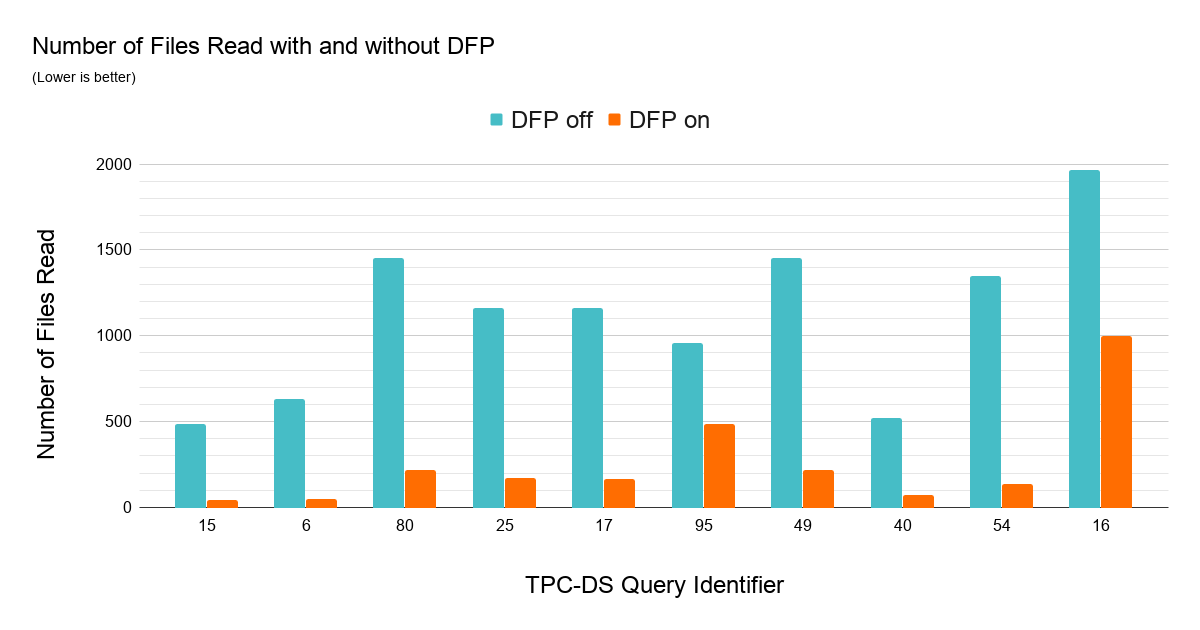
许多TPC-DS查询使用一个典型的星型模式加入日期维度表和事实表(或多个事实表)来过滤日期范围使其成为一个了不起的工作负载展示DFP的影响。在上面的图表给出的数据解释了为什么DFP如此有效的这组查询,他们现在能够减少大量的数据读取。每个查询都有加入过滤事实表的时间限制在一个范围30至90天(事实表存储5年的数据)。DFP对这个工作负载非常有吸引力的查询可以访问三个事实表。
动态文件修剪(DFP),现在在砖运行时的默认启用一个新特性,可以显著提高查询的性能在三角洲湖。DFP非分区表上运行连接查询时尤其有效。DFP提供的更好的性能通常是集群的相关数据,因此,用户可能会考虑使用z值DFP效益的最大化。利用这些最新的性能优化,注册一个今天砖账户!