









Lakehouse进化数据
这是一个客人在森林边缘数据团队撰写文章的技术。我们感谢Bill Inmon,首席执行官,首席…和玛丽莱文
2021年5月19日, 在数据策略
这是一个客人在森林边缘数据团队撰写文章的技术。我们感谢Bill Inmon, CEO,玛丽·莱文,数据策略总监,森林边缘技术的贡献。
深入研究数据的进化Lakehouse &阅读数据Lakehouse上升通过数据仓库的父亲,Bill Inmon。
随着应用程序的数据完整性的问题。大量应用程序的出现的问题是,相同的数据出现在许多地方与不同的值。为了做出决定,用户必须找到哪个版本的数据是正确的使用在许多应用程序中。如果用户没有发现和使用正确的版本的数据,可能会做出错误的决定。
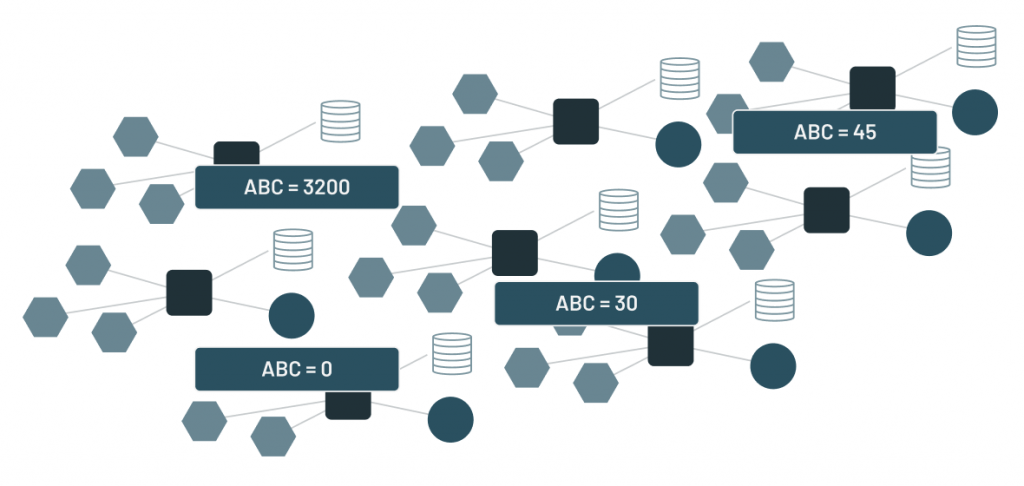
人们发现,他们需要一个不同的体系结构方法来找到正确的数据用于决策。因此,数据仓库诞生了。
数据仓库导致完全不同的应用程序数据被放置在一个单独的物理位置。设计师必须围绕数据仓库构建一个全新的基础设施。
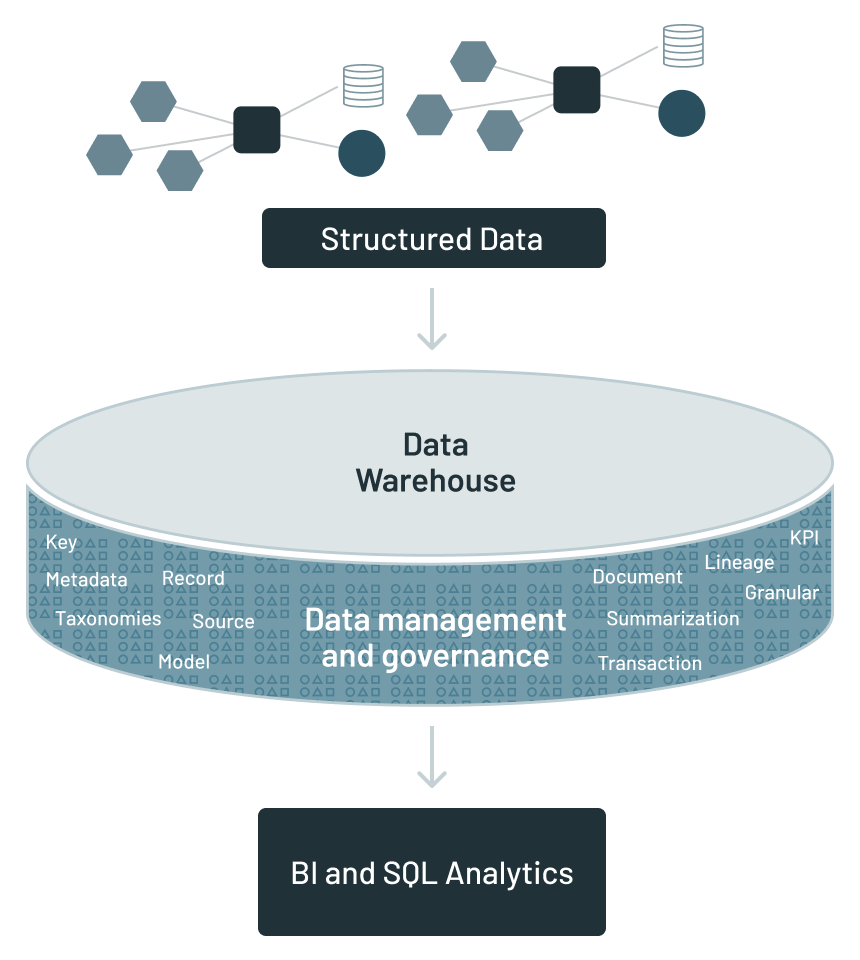
围绕数据仓库的分析基础设施包含诸如:
数据仓库的局限性成为明显的增加各种数据(文本、物联网、图像、音频、视频等)的企业。此外,机器学习(ML)的兴起和AI引入迭代算法,需要直接的数据访问和没有基于SQL。
重要的和有用的数据仓库,在大多数情况下,数据仓库集中在结构化数据。但是现在有许多其他数据类型的公司。为了看看数据驻留在一个公司,考虑一个简单的图:

结构化数据通常是基于事务的数据是由一个组织开展日常业务活动。文本数据是数据所生成的信件、电子邮件和谈话发生在公司内部。其他非结构化数据是有其他来源的数据,如物联网数据、图像、视频和analog-based数据。
数据湖是一个融合的所有不同类型的数据中发现的公司。它已成为企业的地方出售他们所有的数据,鉴于其低成本与文件存储系统API,通用的,打开的文件格式的数据,例如Apache拼花和兽人。使用开放格式也使得湖数据直接访问一个广泛的其他分析引擎,如机器学习系统。
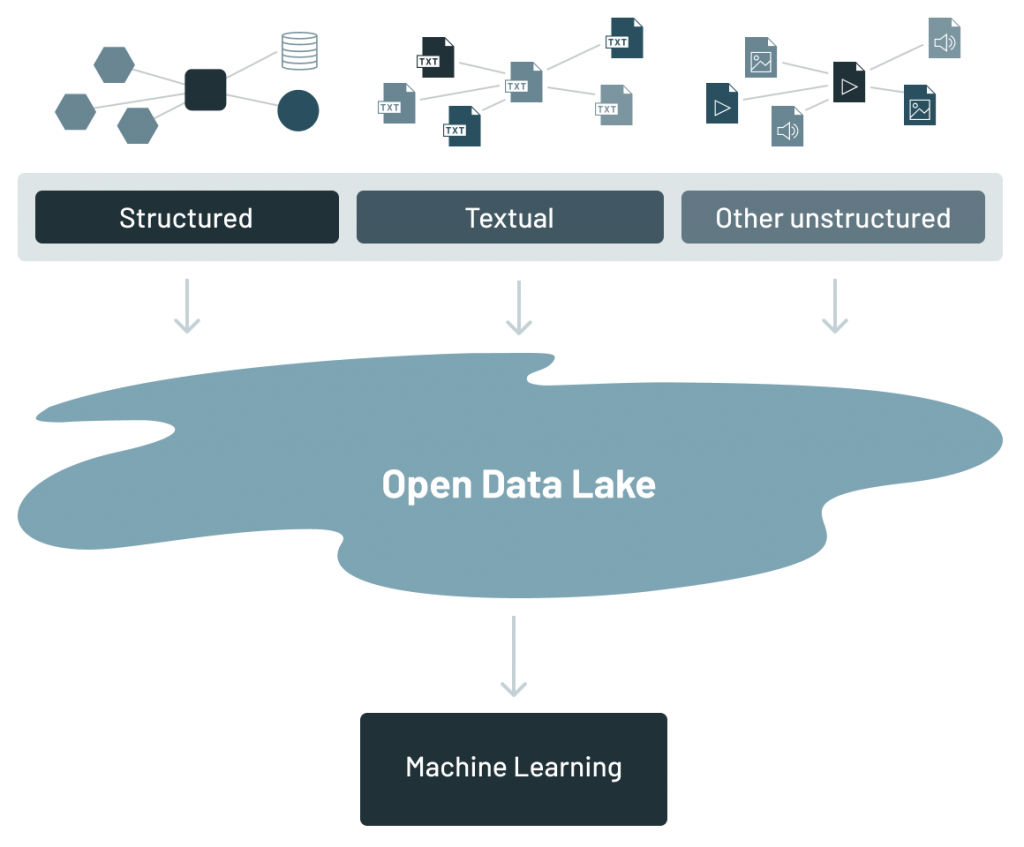
当数据湖是第一次怀了胎,就被认为是必需的,数据应该提取并放置在湖的数据。一旦数据中湖,最终用户可以潜水,发现数据做分析。然而,公司很快发现,使用数据中的数据湖是一个完全不同的故事不仅仅是数据放置在湖里。
许多数据的承诺湖泊没有意识到由于缺少一些关键功能:不支持事务,没有执行数据质量和治理和可怜的性能优化。因此,大多数的数据在企业已经成为湖泊数据沼泽。
由于湖泊和仓库数据的局限性,一个常见的方法是使用多个系统——数据湖,几个数据仓库和其他专业系统,导致三个常见的问题:
1。缺乏开放:数据仓库数据锁定在专有格式,增加的成本数据或工作负载迁移到其他系统。考虑到数据仓库主要提供SQL-only访问,很难运行任何其他分析引擎,如机器学习系统。此外,它是非常昂贵和缓慢直接访问数据仓库与SQL,使集成与其他技术困难。
2。有限的支持机器学习:尽管许多研究毫升和数据管理的融合,没有领先的机器学习系统,如TensorFlow PyTorch XGBoost,做好仓库。与BI提取少量的数据,毫升系统处理大型数据集使用复杂的非sql代码。这些用例,仓库供应商推荐导出数据文件,进而增加复杂性和过时。
3所示。迫使湖泊和数据仓库之间的权衡:超过90%的企业数据存储在数据湖泊从开放直接访问文件由于其灵活性和低成本,它使用廉价的存储。克服缺乏数据的性能和质量问题的湖,企业etl的一小部分数据湖下游数据仓库中的数据最重要的决策支持和BI应用程序。这种双重系统架构需要连续工程ETL数据之间的湖和仓库。每个ETL步骤风险导致失败或引入bug,减少数据质量,同时保持数据湖和仓库一致是困难和昂贵的。除了支付连续ETL,用户支付两数据复制到仓库的仓储成本。
我们看到出现的一个新类的数据架构数据lakehouse,这是通过一个新的开放和标准化系统设计:实现类似的数据结构和数据管理功能在数据仓库中,直接在低成本存储用于数据的湖泊。
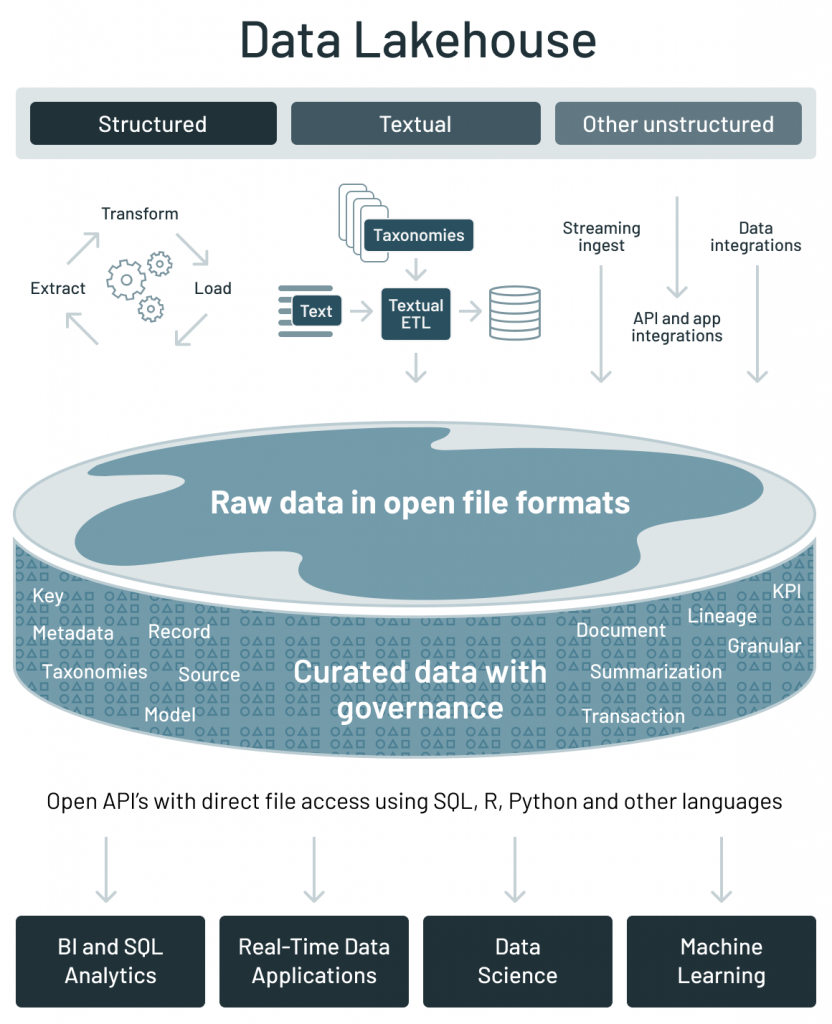
数据lakehouse架构地址当前数据架构的关键挑战在前一节中讨论的:
这里有各种功能,使lakehouse架构的主要优点:
开放:
机器学习支持:
以低成本最佳性能和可靠性:
| 数据仓库 | 数据湖 | 数据lakehouse | |
| 数据格式 | 关闭,专有格式 | 开放格式 | 开放格式 |
| 类型的数据 | 有限的结构化数据,支持半结构化数据 | 所有类型:结构化数据、半结构化数据、文本数据、非结构化(生的)数据 | 所有类型:结构化数据、半结构化数据、文本数据、非结构化(生的)数据 |
| 数据访问 | SQL-only,没有直接访问文件 | 开放api直接访问文件和SQL, R, Python和其他语言 | 开放api直接访问文件和SQL, R, Python和其他语言 |
| 可靠性 | 高品质,可靠的数据与ACID事务 | 低质量数据沼泽 | 高品质,可靠的数据与ACID事务 |
| 治理和安全 | 细粒度的安全性和治理行/柱状水平表 | 可怜的治理作为安全需要应用到文件 | 细粒度的安全性和治理行/柱状水平表 |
| 性能 | 高 | 低 | 高 |
| 可伸缩性 | 扩展成为指数更加昂贵 | 尺度持有任何以低成本的数据量,无论类型 | 尺度持有任何以低成本的数据量,无论类型 |
| 用例支持 | 限于BI、SQL应用程序和决策支持 | 限于机器学习 | 一个数据BI架构,SQL和机器学习 |
我们相信数据lakehouse架构提供了一个机会与我们看到的在早期的数据仓库市场。lakehouse的独特的能力来管理数据在一个开放的环境中,混合所有品种的数据来自企业的各个组成部分和把数据的数据科学重点湖与最终用户分析数据仓库会释放令人难以置信的价值的组织。
想了解更多吗?BOB低频彩加入数据+人工智能峰会,全球事件的数据社区,Bill Inmon和砖的炉边谈话阿里Ghodsi联合创始人和首席执行官。这个免费的虚拟事件特征数据+人工智能有远见,思想领袖和专家——查看完整的演讲者阵容在这里。
森林边缘技术是由Bill Inmon和是世界领导人在将文本非结构化数据转换为结构化数据库进行更深入的见解和有意义的决策。