公共数据科学物联网(物联网)用例涉及培训机器学习模型实时数据来自军队的物联网传感器。一些用例要求每个连接的设备都有自己的个人模型由于许多基本的机器学习算法通常比一个复杂的模型。我们看到在供应链优化、预测性维护,电动汽车充电时,智能家居管理,或任何其他的用例。问题是这样的:
- 整个物联网数据是如此巨大,以至于不适合在任何一台机器
- 每个设备数据并在单个机器上
- 一个单独的模型需要为每一台设备
- 数据科学团队实现使用单节点库sklearn和熊猫一样,所以他们需要低摩擦分发他们的单机的概念
在这个博客中,我们展示如何解决这个问题有两个不同的方案,每一个物联网设备:模型训练和模型得分。
毫升Multi-IoT设备的解决方案
这是一个规范的大数据问题。物联网设备如天气传感器和车辆产生一个令人惊叹的数据点的数量。单机解决方案不会扩展到这种复杂性的问题,通常不也集成到生产环境中。和数据科学团队不想担心DataFrame是否他们使用是一个单机熊猫对象或分布Apache火花。还有一件事:我们需要日志模型及其性能的地方再现性,监测,和部署。
这里有两个模式,我们需要解决这个问题:
- 模型训练:创建一个函数,接受一个设备的数据作为输入。火车模型。使用日志生成的模型和评价指标MLflow,一个开源bob下载地址平台的机器学习生命周期bob体育客户端下载
- 模型评分:创建第二个函数,把训练模型从MLflow设备,应用它,并返回预测
有了这些抽象,我们只需要把我们的功能熊猫UDF为了分发的火花。熊猫UDF允许任意Python代码的效率分布在一个火花工作,允许否则串行操作的分布。我们将会有一个单节点的解决方案,使其高度平行。
物联网模型训练
现在,让我们仔细看看模型训练。从一些假数据。我们有一个连接设备,为每个样本,一些功能,我们想要预测一个标签。这是常有的事与物联网设备,可以用火花featurization步骤利用其可伸缩性。
进口pyspark.sql.functions作为fdf =(火花。范围(10000年*1000年).select (f.col (“id”).alias (“record_id”),(f.col (“id”)%10).alias (“device_id”)).withColumn (“feature_1”f.rand () *1).withColumn (“feature_2”f.rand () *2).withColumn (“feature_3”f.rand () *3).withColumn (“标签”,(f.col (“feature_1”)+ f.col (“feature_2”)+ f.col (“feature_3”)+ f.rand ()))
接下来,我们需要定义的模式,我们的训练函数将返回。我们想要返回设备ID,用于培训的记录数量,路径模型和评价指标。
进口pyspark.sql.types作为t
trainReturnSchema = t.StructType ([t.StructField (“device_id”t.IntegerType ()),#唯一的设备标识t.StructField (“n_used”t.IntegerType ()),#用于培训的记录数量t.StructField (“model_path”t.StringType ()),#路径模型对于一个给定的设备t.StructField (mse的t.FloatType ())#度量模型性能])
需要定义一个熊猫UDF熊猫DataFrame一组数据作为输入,并返回模型元数据作为输出。
进口mlflow进口mlflow.sklearn进口熊猫作为pd从sklearn.ensemble进口RandomForestRegressor从sklearn.metrics进口mean_squared_error@f.pandas_udf (trainReturnSchema functionType = f.PandasUDFType.GROUPED_MAP)deftrain_model(df_pandas):“‘火车一个分组sklearn模型实例“‘#把元数据device_id = df_pandas [“device_id”].iloc [0]n_used = df_pandas.shape [0]run_id = df_pandas [“run_id”].iloc [0]#把ID进行嵌套跑#火车模型X = df_pandas [[“feature_1”,“feature_2”,“feature_3”]]y = df_pandas [“标签”]射频= RandomForestRegressor ()射频。fit(X, y)#评估模型预测= rf.predict (X)mse = mean_squared_error (y,预测)#注意我们可以添加一列火车/测试#恢复高层培训与mlflow.start_run (run_id = run_id):#创建一个嵌套运行特定的设备与mlflow.start_run (run_name =str(device_id),嵌套的=真正的)作为运行:mlflow.sklearn.log_model (rf,str(device_id))mlflow.log_metric (“mse”mse)artifact_uri =f: /{run.info.run_id}/{device_id}”#创建一个返回熊猫DataFrame相匹配的模式returnDF = pd。DataFrame ([[device_id, n_used artifact_uri, mse]],列= [“device_id”,“n_used”,“model_path”,“mse”])返回returnDF
物联网设备模型和嵌套在MLflow运行日志
的MLflow跟踪方案允许我们开发过程日志机器学习的不同方面。在我们的例子中,我们将创建一个运行(或一个机器学习的执行代码)为每一个我们的设备。我们将聚合这些运行使用一个父母一起运行。
这也让我们看到如果任何个人的模型的性能不如别人。我们只需要添加日志逻辑大熊猫UDF,如上图所示。虽然这段代码将执行工作的节点集群上,如果我们开始父母在我们开始嵌套跑,我们还是可以一起日志这些模型。
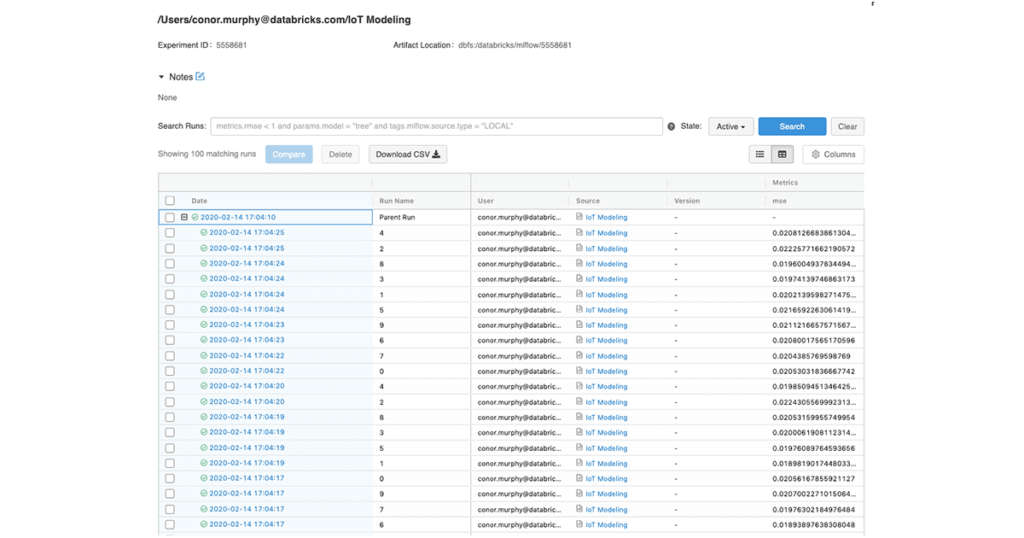
我们可以查询MLflow拿回URI的为每个模型。从熊猫UDF返回URI而不是只是让整个管道有点容易缝合在一起。
并行训练
现在我们只需要应用分组地图熊猫UDF。只要数据对于任何给定的设备将安装在一个节点的集群的火花,我们可以分发培训。首先使MLflow父运行,然后应用熊猫UDF使用groupby然后一个应用。
与mlflow.start_run (run_name =“所有设备训练”)作为运行:run_id = run.info.run_uuid
modelDirectoriesDF = (df.withColumn (“run_id”f.lit (run_id))#添加run_id.groupby (“device_id”)苹果(train_model))
combinedDF = (df. join (modelDirectoriesDF =“device_id”,=“左”))
你走吧!一个模型为每个设备已被训练和记录。
物联网模型得分
现在的得分。优化技巧在于确保我们只获取模型一次对每一个设备,限制了通信开销。然后我们应用模型在一个机器上下文并返回一个熊猫DataFrame记录id和他们的预测。
applyReturnSchema = t.StructType ([t.StructField (“record_id”t.IntegerType ()),t.StructField (“预测”t.FloatType ())])@f.pandas_udf (applyReturnSchema functionType = f.PandasUDFType.GROUPED_MAP)defapply_model(df_pandas):“‘模型适用于特定设备,数据表示为熊猫DataFrame“‘model_path = df_pandas [“model_path”].iloc [0]input_columns = [“feature_1”,“feature_2”,“feature_3”]X = df_pandas [input_columns]
模型= mlflow.sklearn.load_model (model_path)预测= model.predict (X)
returnDF = pd.DataFrame ({“record_id”:df_pandas (“record_id”),“预测”:预测})返回returnDFpredictionDF = combinedDF.groupby (“device_id”苹果(apply_model)
注意,在每种情况下我们使用分组地图熊猫UDF。在第一种情况下,我们采取作为输入并返回一组一行每一个设备(多对一映射)。在这种情况下,我们需要一组作为输入并返回一个预测每一行(一对一的映射)。分组地图熊猫UDF允许这两种方法。
结论
所以你有个性化模型训练整个军队的物联网设备。这支持许多基本模型通常比一个更复杂的模型。即使这是一般的情况,可能会有个别模型执行低于平均水平部分原因是有限的或缺失数据的设备。这里有一些建议如何更进一步:
- 使用的数量记录在培训和评估指标,你可以很容易地描述个体模型与模型,表现不佳表现良好。您可以使用此信息之间切换种每设备模型和模型训练整个舰队。
- 你也可以训练一个整体模型,以预测从种每设备模型,预测提供从机舱模型和元数据评价指标和每个设备的记录数。这将创建一个最终改善不佳的单个模型的预测。
为物联网设备开始使用MLflow
准备试一试自己吗?你可以看到这篇博客中使用的完整的示例在runnable笔记本AWS或Azure。
如果您是MLflow,阅读最新的MLflow快速入门MLflow释放。生产用例,读到管理MLflow砖上。