

利用XGBoost和Databricks Runtime进行贷款风险分析




对于那些从客户贷款利息中赚钱的公司来说,这总是关于增加底线。能够评估贷款申请的风险可以为贷款人节省持有过多风险资产的成本。数据科学家的工作是对客户数据进行分析,并制定将直接影响贷款批准的业务规则。
花时间构建这些机器学习模型的数据科学家是一种稀缺资源,他们经常被孤立在一个沙盒里:
- 尽管他们每天都在处理数据,但他们依赖于数据工程师来获得最新的表。
- 随着数据以指数级速度增长,他们依赖于基础设施团队提供计算资源。
- 一旦模型构建过程完成,他们必须相信软件开发人员能够正确地将模型代码转换为可用于生产的代码。
这就是数据库的位置bob体育亚洲版统一分析平台bob体育客户端下载可以帮助弥合工作流链不同部分之间的差距,并减少数据科学家、数据工程师和软件工程师之间的摩擦。
除了减少操作摩擦,Databricks还是运行最新机器学习模型的中心位置。用户可以使用原生Spark MLLib包或下载任何开源Python或R ML包。bob下载地址与Databricks运行时机器学习Databricks集群预先配置了XGBoost, scikit-learn和numpy以及流行的深度学习框架,如TensorFlow, Keras, Horovod及其依赖项。
在这篇博客中,我们将探讨如何:
- 导入示例数据源以创建Databricks表
- 使用Databricks Visualizations探索您的数据
- 针对数据执行ETL代码
- 执行ML管道,包括模型调优XGBoost逻辑回归
导入数据
对于我们的实验,我们将使用公开的Lending Club贷款数据。它包括2012年至2017年的所有融资贷款。每笔贷款都包括申请人提供的申请人信息,以及当前的贷款状态(当前、逾期、全额支付等)和最新的付款信息。有关更多信息,请参阅Lending Club Data模式。
在本地下载数据之后,就可以在Databricks工作区中创建数据库和表来加载这个数据集。要了解更多信息,请参见《数据库文档>用户指南>数据库和表>创建表》AWS或Azure.
在本例中,我们创建了Databricks数据库艾米和表loanstats_2012_2017.下面的代码片段允许您通过PySpark访问Databricks笔记本中的这个表。
#导入贷款统计表Loan_stats = spark.table(“amy.loanstats_2012_2017”)探索你的数据
和数据库一起显示命令时,您可以使用Databricks本机可视化。
查看我们数据的条形图显示器(loan_stats)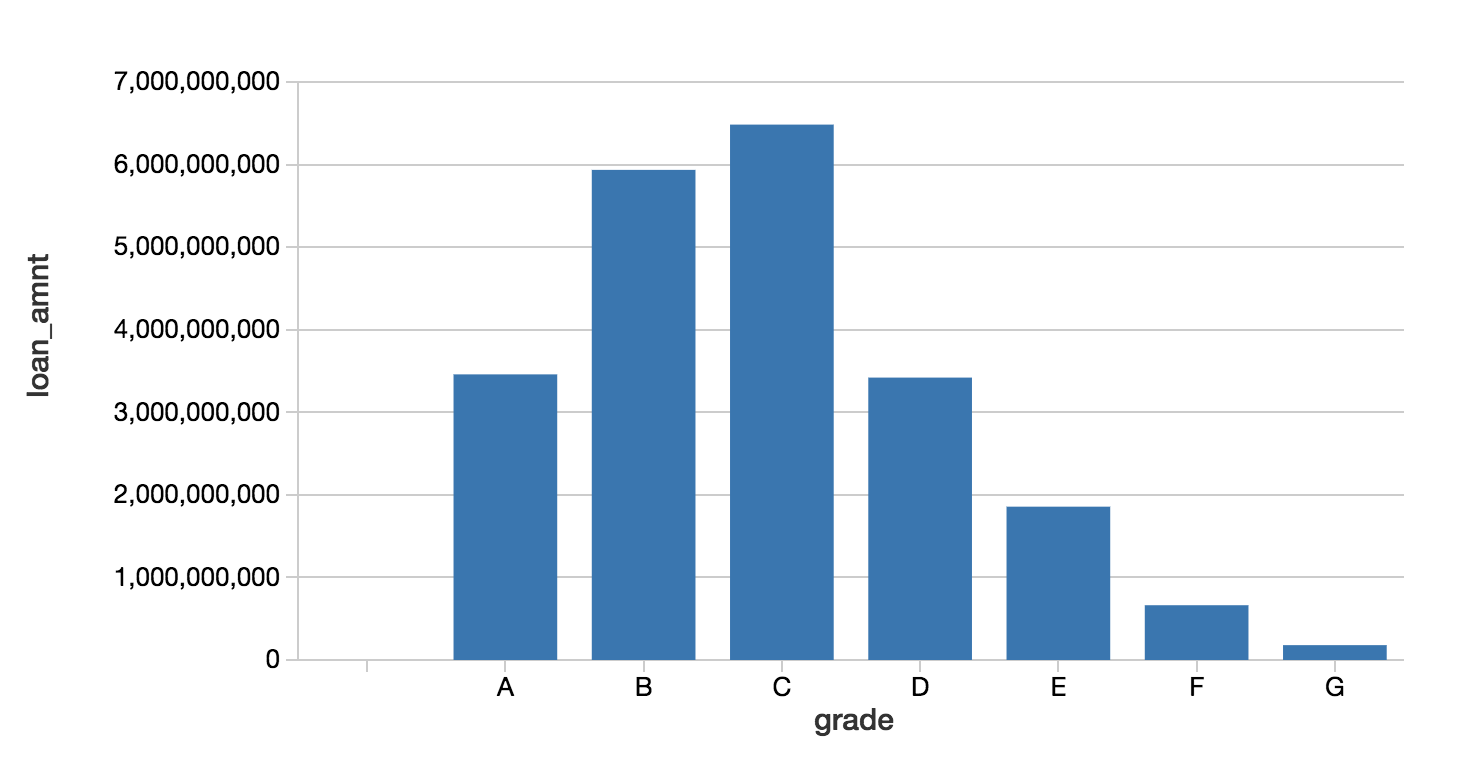
在本例中,我们可以通过查看贷款等级和贷款金额来查看资产配置。
使用PySpark DataFrame API修改数据
如在清洁大数据(福布斯)在美国,数据科学家80%的工作是数据准备,这通常是工作中最不愉快的方面。但是使用PySpark,您可以编写Spark SQL语句或使用PySpark DataFrame API来简化数据准备任务。下面是简化数据过滤的代码片段。
#进口贷款统计表格loan_stats=loan_stats。过滤器(\loan_stats.loan_status。型号(\[“违约”、“冲销”、“已付清”]) \) .withColumn (“bad_loan”,(~(loan_stats.loan_status==“全部付讫”)).投(“字符串”))完成此ETL过程后,您可以使用显示再次命令以查看散点图中已清理的数据。
查看我们数据的条形图显示器(loan_stats)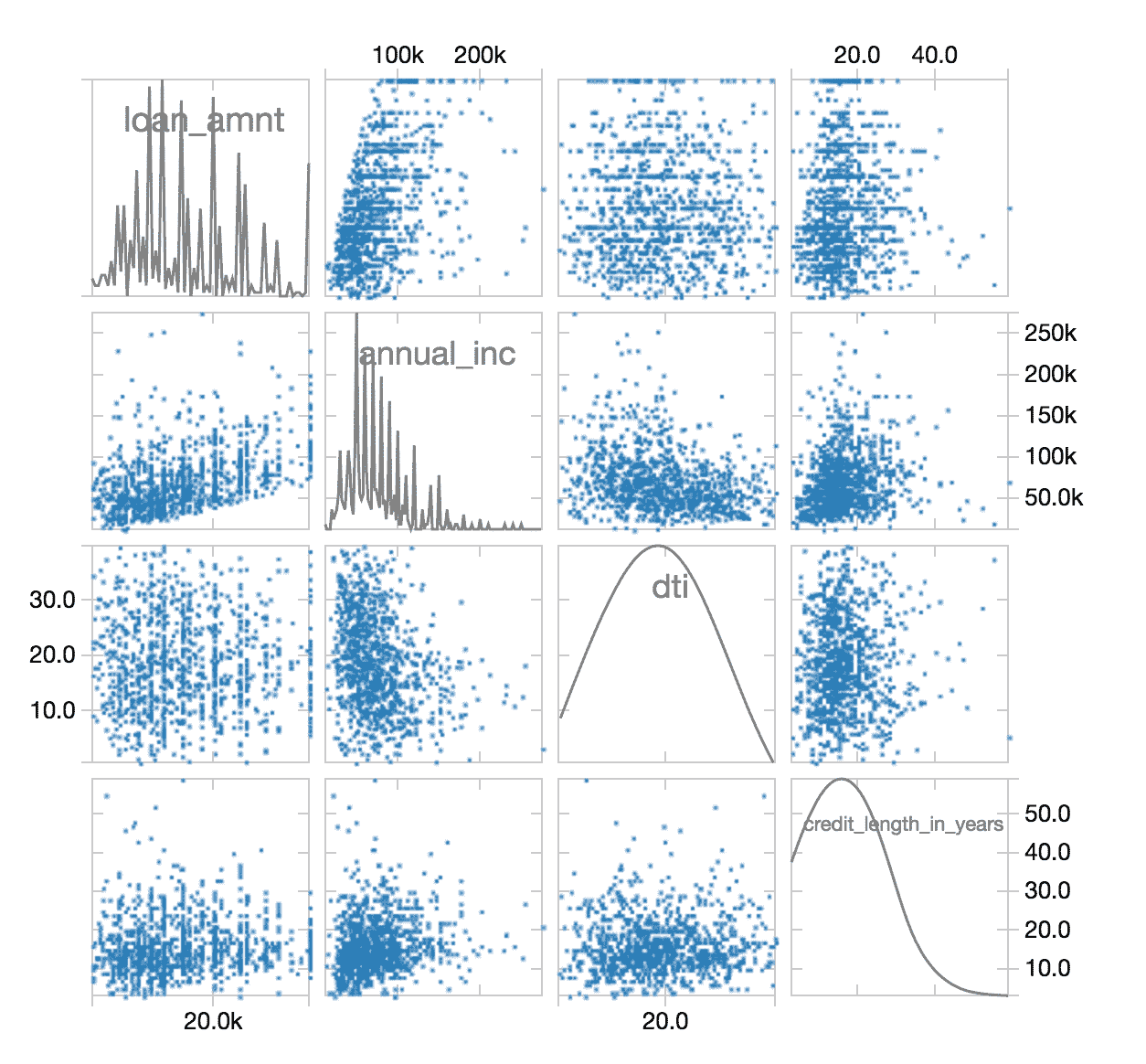
要在地图可视化中查看按州划分的相同资产数据,可以使用显示命令结合了PySpark DataFrame API使用集团语句与gg(聚合),例如下面的代码片段。
#视图地图的我们的资产数据显示器(loan_stats.groupBy(“addr_state”).agg ((数(坳(“annual_inc”))).alias(比率)))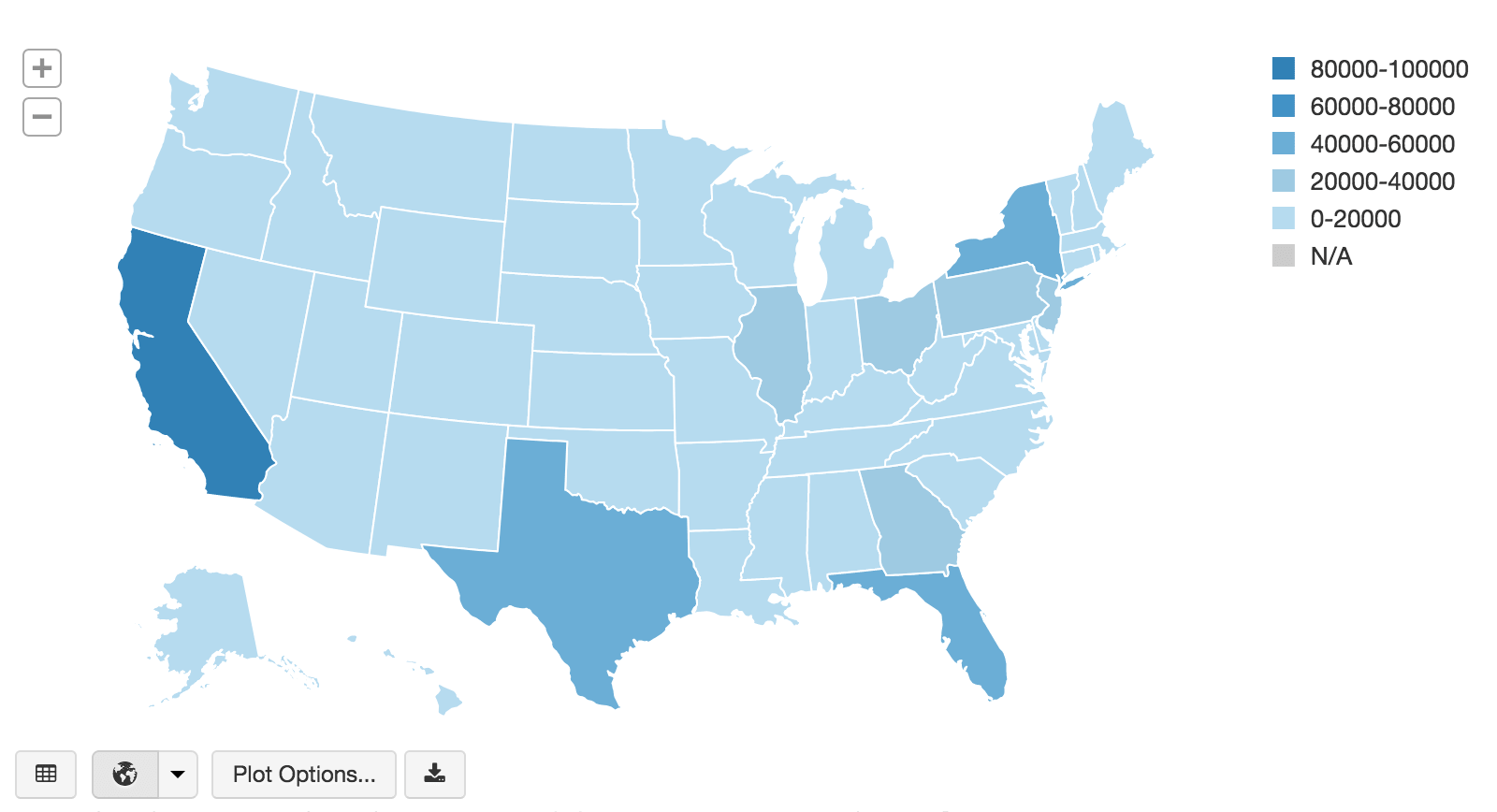
使用XGBoost训练我们的ML模型
虽然我们可以快速可视化我们的资产数据,但我们想看看是否可以创建一个机器学习模型,使我们能够根据可用参数预测贷款是好是坏。正如下面的代码片段所指出的,我们将预测bad_loan(定义为标签)通过构建我们的ML管道,如下所示:
- 执行一个
输入方法中填充缺失的值数字组成属性(输出为numerics_out) - 使用
索引器来处理分类值,然后使用OneHotEncoder通过将它们转换为向量oneHotEncoders(输出categoricals_class). - 的
特性为我们的ML管道定义categorical_class而且numerics_out. - 接下来,我们将通过执行
VectorAssembler. - 如前所述,我们将建立我们的
标签(即我们将要尝试预测的内容)作为bad_loan列。 - 在确定应用哪种算法之前,应用标准的缩放器来构建我们的管道数组(
pipelineAry).
虽然前面的代码片段是用Python编写的,但下面的代码示例是用Scala编写的,以允许我们利用XGBoost4J-Spark。的笔记本系列包含在Parquet中保存数据并随后在Scala中读取数据的Python代码。
//填充缺失值的估算器Val numerics_out =数字。地图(_ +“找到”)Val imputers =新输入().setInputCols(数字).setOutputCols (numerics_out)//为我们的分类数据应用StringIndexerVal categoricals_idx = categoricals。地图(_ +“_idx”)Val索引器= categories .map(x= >新StringIndexer () .setInputCol (x)。setOutputCol (x +“_idx”) .setHandleInvalid (“保持”))//为StringIndexed分类数据应用OHEVal categoricals_class = categoricals。地图(_ +“_class”)val oneHotEncoders =新OneHotEncoderEstimator ().setInputCols (categoricals_idx).setOutputCols (categoricals_class)//设置特征列val featureCols = categoricals_class ++ numerics_out//为我们的数字列创建汇编程序(包括标签)Val汇编程序=新VectorAssembler ().setInputCols (featureCols).setOutputCol (“特征”)//建立标签val labelIndexer =新StringIndexer ().setInputCol (“bad_loan”).setOutputCol (“标签”)//应用StandardScalerVal标量=新StandardScaler ().setInputCol (“特征”).setOutputCol (“scaledFeatures”).setWithMean (真正的).setWithStd (真正的)//构建管道数组val pipelineAry = indexers ++数组(oneHotEncoders, imputers,汇编器,labelIndexer, scaler)现在我们已经建立了我们的管道,让我们创建XGBoost管道并将其应用到我们的训练数据集中。
//创建XGBoostEstimatorval xgBoostEstimator =新XGBoostEstimator (地图[字符串,任何)(“num_round”->5,“客观”->“二进制:物流”,“nworkers”->16,“nthreads”->4)).setFeaturesCol (“scaledFeatures”).setLabelCol (“标签”)//创建XGBoost管道val xgBoostPipeline =新管道()。setStages (pipelineAry + +数组(xgBoostEstimator))//基于训练数据集创建XGBoost模型val xgBoostModel = xgBoostPipeline.fit(dataset_train)//根据验证数据集测试我们的模型val预测= xgBoostModel.transform(dataset_valid)显示器(predictions.select (“概率”,“标签”))注意,"nworkers" -> 16, "nthreads" -> 4配置为使用的实例为16个虚拟机,每个虚拟机有4个vcpu和大约30gb的内存。
现在我们有了我们的模型,我们可以根据验证数据集测试我们的模型预测包含结果。
模型有效性评估
现在我们已经构建并训练了XGBoost模型,让我们通过使用BinaryClassficationEvaluator.
//包含BinaryClassificationEvaluator进口org.apache.spark.ml.evaluation.BinaryClassificationEvaluator/ /评估Val评估器=新BinaryClassificationEvaluator ().setRawPredictionCol (“概率”)//计算验证AUCVal accuracy = evaluator.evaluate(预测)经计算,XGBoost验证数据曲线下面积(AUC)为:~0.6520。
使用MLlib交叉验证优化模型
我们可以尝试使用MLlib交叉验证来调优我们的模型CrossValidator如下面的代码片段所示。我们首先建立参数网格,这样就可以使用包含不同参数值的网格执行多次运行。使用相同的BinaryClassificationEvaluator我们用来测试模型有效性的方法,我们在更大的范围内使用不同的参数组合通过结合BinaryClassificationEvaluator而且ParamGridBuilder并应用到我们的CrossValidator ().
//构建参数网格val paramGrid =新ParamGridBuilder ().addGrid (xgBoostEstimator.maxDepth数组(4,7)).addGrid (xgBoostEstimator.eta数组(0.1,0.6)).addGrid (xgBoostEstimator.round数组(5,10)).build ()//将evaluator设置为BinaryClassificationEvaluatorVal评估器=新BinaryClassificationEvaluator ().setRawPredictionCol (“概率”)//建立交叉验证器()Val CV =新CrossValidator ().setEstimator (xgBoostPipeline).setEvaluator(评估者).setEstimatorParamMaps (paramGrid).setNumFolds (4)//运行交叉验证,并选择最佳参数集。val cvModel = cv.fit(dataset_train)注意,对于XGBoostEstimator的初始配置,我们使用num_round,但我们使用round (num_round不是估计器中的属性)
此代码片段将运行交叉验证并选择最佳参数集。然后我们可以重新运行我们的预测并重新计算准确性。
//根据cvModel和验证数据集测试我们的模型val predictions_cv = cvModel.transform(dataset_valid)显示器(predictions_cv.select (“概率”,“标签”))//计算cvModel验证AUCVal accuracy = evaluator.evaluate(predictions_cv)我们的精度略有提高,值为~0.6734。
您还可以通过运行下面的代码片段查看bestModel参数。
//查看bestModel参数cvModel.bestModel.asInstanceOf [PipelineModel] .stages (11) .extractParamMap量化业务价值
快速理解该模型的业务价值的一个好方法是创建一个混淆矩阵。我们的矩阵定义如下:
- 预测=1,标签=1(蓝色):正确发现不良贷款。Sum_net =避免的损失。
- 预测=1,标签=0(橙色):错误标记的不良贷款。Sum_net =丧失利润。
- 预测=0,标签=1(绿色):错误标记的良好贷款。Sum_net =仍然发生的损失。
- 预测=0,标签=0(红色):正确发现好的贷款。Sum_net =留存利润。
下面的代码段计算以下混淆矩阵。
显示器(predictions_cv。groupBy(“标签”,“预测”).agg ((总和(坳(“净”))/(1 e6) .alias(“sum_net_mill”)))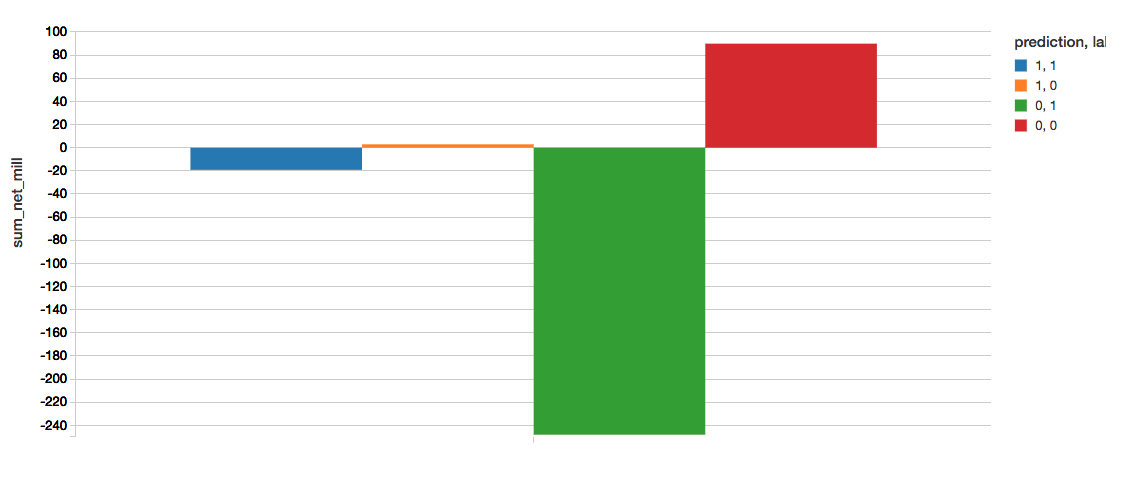
为了确定从实现模型中获得的价值,我们可以计算为
价值= -(避免损失-丧失利润)我们当前的XGBoost模型AUC = ~0.6734,这些值说明了实现XGBoost模型的显著值增益。
- value (XGBoost): 22.076
注意,这里引用的值是指从防止坏账损失中节省的数百万美元。
总结
方法快速执行贷款风险分析Databricks统bob体育亚洲版一分析平台(UAP)bob体育客户端下载其中包括Databricks机器学习运行时。与Databricks运行时机器学习Databricks集群预先配置了XGBoost, scikit-learn和numpy以及流行的深度学习框架,如TensorFlow, Keras, Horovod及其依赖项。
通过消除通常与此类数据管道相关的数据工程复杂性,我们可以快速地将数据源导入Databricks表,使用Databricks Visualizations查看数据,针对数据执行ETL代码,并使用XGBoost逻辑回归构建、训练和优化ML管道。试试这个笔记本系列今天在Databricks !