Apache SparkDataFrame API提供一组丰富的函数(选择列、筛选、连接、聚合等),使您能够有效地解决常见的数据分析问题。dataframe还允许您将操作与自定义Python、R、Scala和SQL代码无缝混合。在本教程模块中,您将学习如何:
我们也提供样的笔记本您可以导入它来访问和运行模块中包含的所有代码示例。
开始使用dataframe的最简单方法是使用/ databricks-datasets在Databricks工作区中可访问的文件夹。要访问比较城市人口与房屋销售价格中位数的文件,请加载该文件/ databricks-datasets /样本/ population-vs-price / data_geo.csv。
# -自动推断数据的模式data = Spark .read.format(" CSV ") .option("header", "true") .option(" interschema ", "true") .load("/ databrickks -datasets/samples/population-vs-price/data_geo.csv") data. Cache() #缓存数据以便更快地重用data = data.dropna() #删除缺少值的行
现在您已经创建了数据您可以使用标准的Spark命令快速访问数据,例如带()。例如,您可以使用命令data.take (10)的前十行数据DataFrame。因为这是一个SQL笔记本,所以接下来的几个命令使用% python神奇的命令。
% python data.take (10)
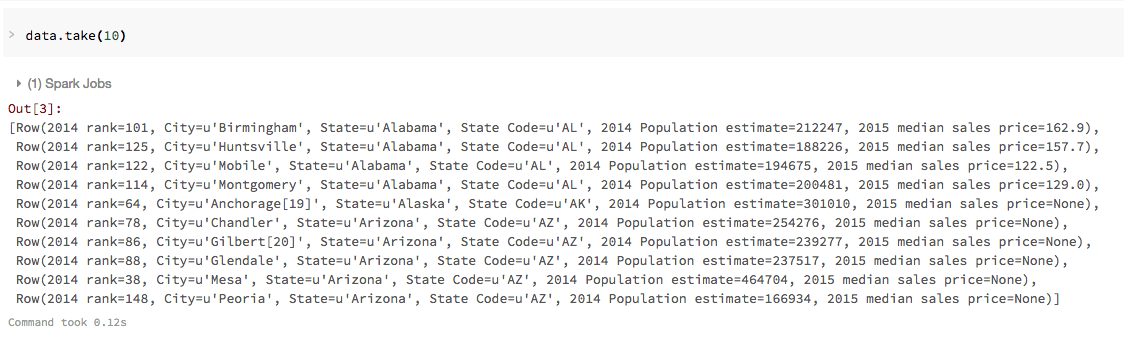
要以表格格式查看这些数据,可以使用Databricks显示()命令,而不是将数据导出到第三方工具。
% python展示(数据)
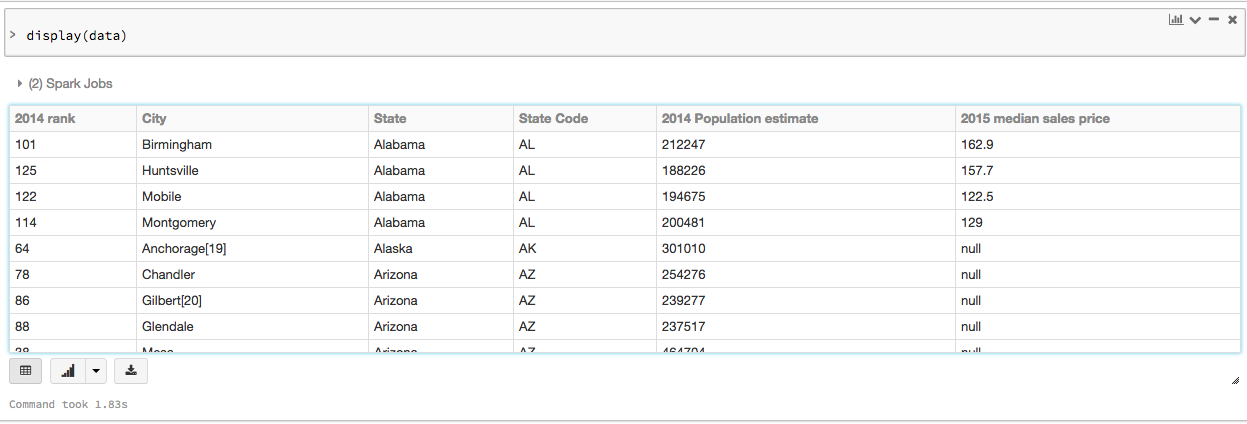
在发出SQL查询之前,必须保存数据DataFrame作为临时表:
注册表,以便通过SQL Context data.createOrReplaceTempView("data_geo")访问
然后,在一个新的单元格中,指定一个SQL查询来按州列出2015年的销售价格中位数:
从data_geo中选择“州代码”,“2015年销售价格中位数”

或者,查询华盛顿州的人口估计:
select City, ' 2014 Population estimate ' from data_geo where ' State Code ' = 'WA';

使用Databricks的另一个好处显示()命令,您可以使用许多嵌入的可视化工具快速查看此数据。按钮旁边的向下箭头 显示可视化类型的列表。
显示可视化类型的列表。

然后,选择Map图标来创建前一节中销售价格SQL查询的地图可视化:

我们也提供样的笔记本您可以导入它来访问和运行模块中包含的所有代码示例。
