
使用AWS Glue作为Databricks的目录
为了在所有服务中发现数据,您需要一个强大的目录来查找和访问数据。AWS Glue服务是一个与apache兼容的Hive无服务器metastore,允许您轻松地跨AWS服务、应用程序或AWS帐户共享表元数据。Databricks和Delta Lake与AWS Glue集成,用于发现组织中的数据、在Delta Lake中注册数据以及在Databricks实例之间发现数据。
장점
Databricks与AWS Glue预集成
![]()
심플
通过跨多个Databricks工作区使用相同的AWS Glue目录,简化了可管理性。
![]()
협업
更方便地访问跨Amazon服务的元数据,以及访问在AWS Glue中编目的数据。
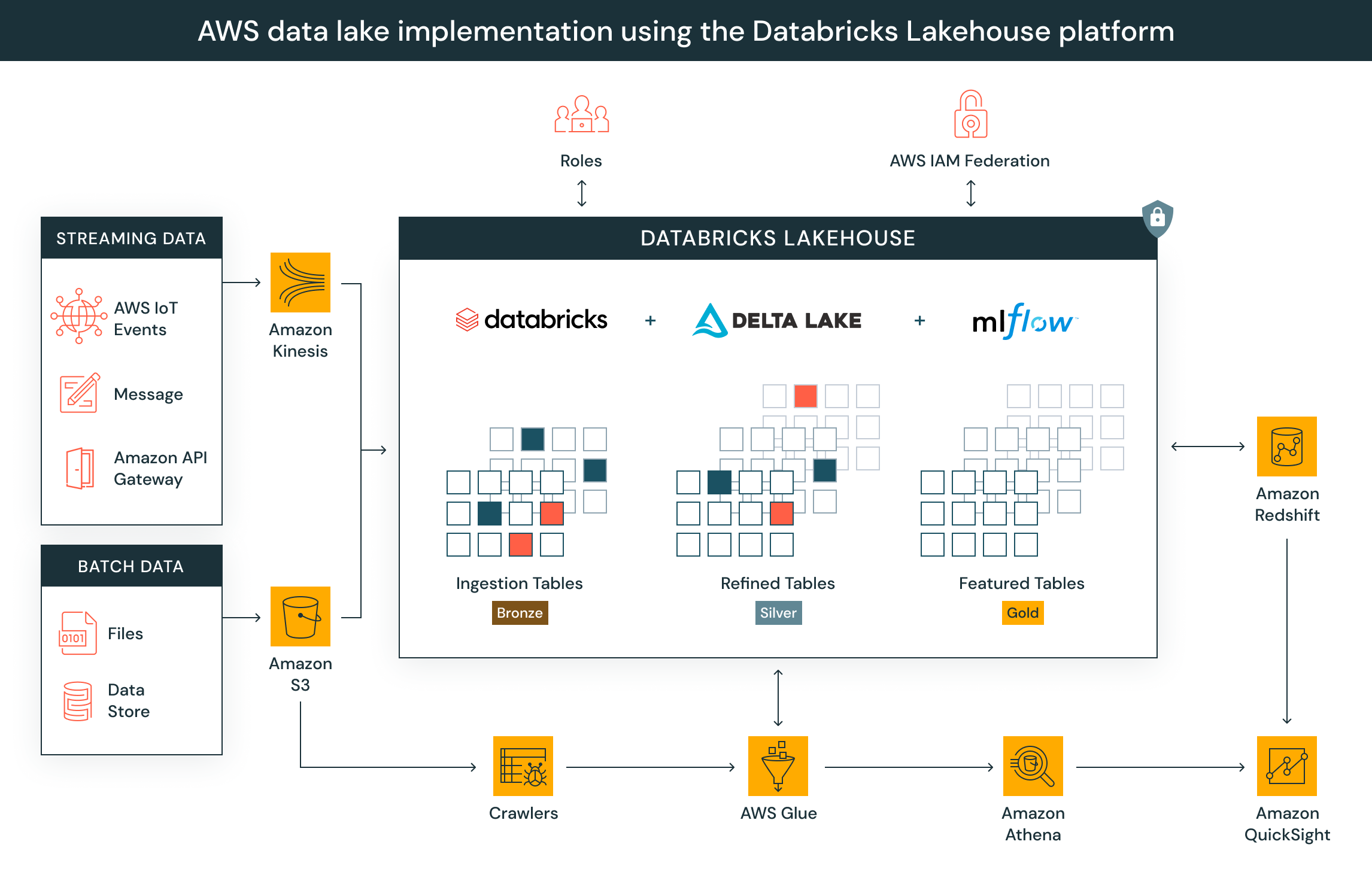
Databricks Delta Lake与AWS核心服务集成
此参考实现说明了Databricks Delta Lake与AWS核心服务的独特定位集成,以帮助您解决最复杂的数据湖挑战。Delta Lake运行在S3之上,它与Amazon Kinesis、AWS Glue、Amazon Athena、Amazon Redshift和Amazon QuickSight等集成在一起。
如果你是第一次来三角洲湖,你可以BOB低频彩点击这里了解更多.

将Databricks与AWS Glue集成
步骤1
如何配置Databricks集群以访问AWS Glue Catalog
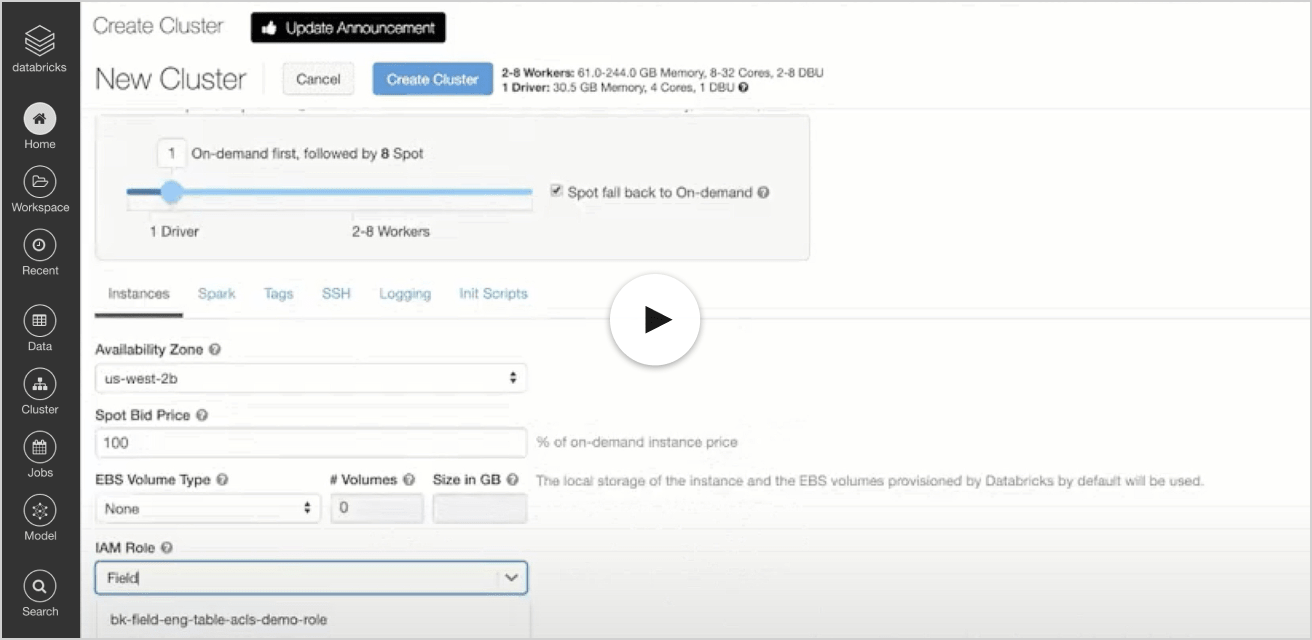
发射
首先启动数据计算集群使用必要的AWS Glue Catalog IAM角色。IAM角色和策略需求在Databricks AWS Glue作为Metastore文档.
在本例中,创建一个名为Field_Glue_Role的AWS IAM角色,该角色还将访问权限委托给我的S3桶。将角色附加到集群配置,如演示视频中所述。
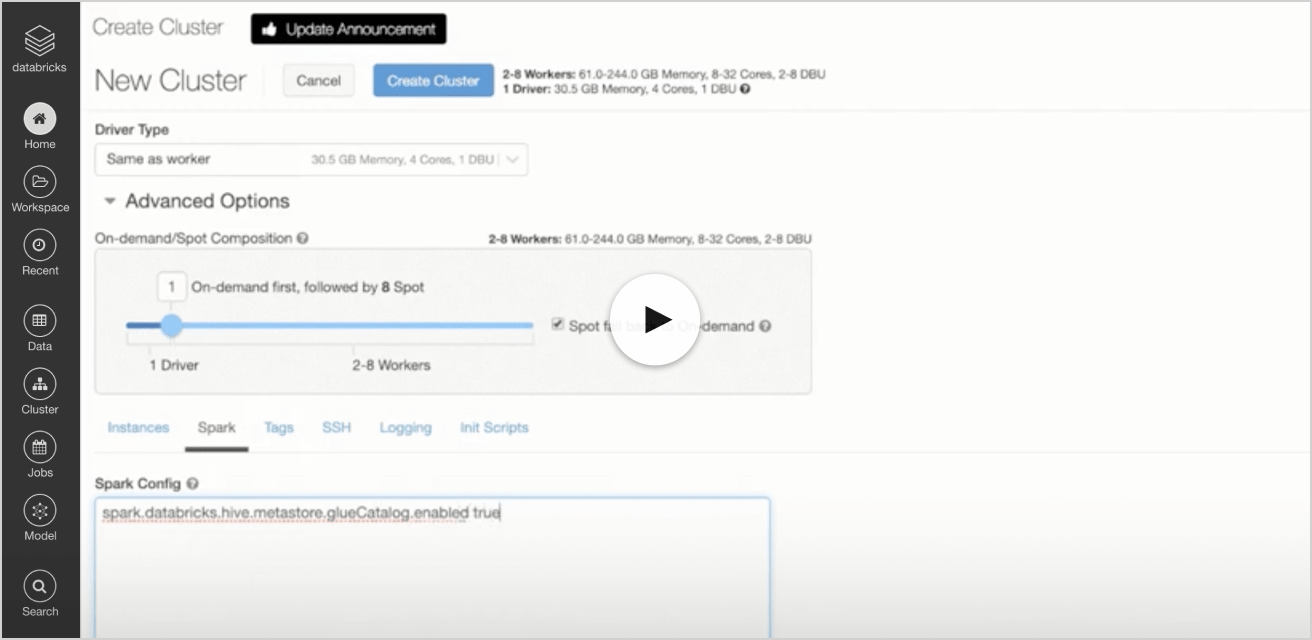
更新
接下来,Spark配置属性的集群配置必须在集群启动之前设置,如如何更新视频所示。
步骤2
使用Databricks笔记本建立AWS Glue数据库

附加
在创建AWS Glue数据库之前,将集群附加到上一步创建的笔记本上,并使用下面所示的命令测试设置。
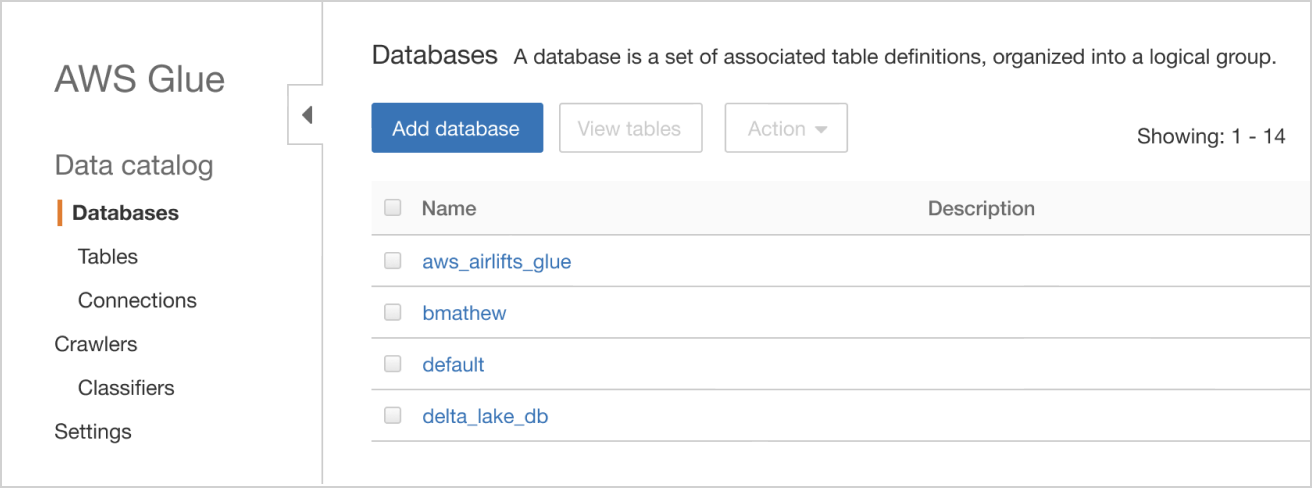
验证
然后验证使用AWS Glue控制台显示相同的数据库列表,并列出这些数据库。

验证
直接从笔记本中创建一个新的AWS Glue数据库,并通过重新发布SHOW DATABASES验证新的AWS Glue数据库已经成功创建。AWS Glue数据库也可以通过数据窗格查看。
步骤3
使用相同的metastore创建Delta Lake表和清单文件

创建和编目
直接从笔记本创建表并将其编入AWS Glue数据目录。指填充AWS Glue数据目录用于使用爬虫程序创建和编目表。
这里的演示数据集来自一个电影推荐网站MovieLens,由电影评分组成。使用以下python代码创建一个DataFrame。

注册
然后将DataFrame注册为临时表,并使用此SQL命令访问它。



为Amazon Athena生成一个清单
现在,使用以下步骤生成Amazon Athena所需的清单文件。
1.通过运行这个Scala方法生成清单。记住在单元格前加上% scala如果你 创建了一个python, SQL或R笔记本。
2.在Hive metastore中创建一个表,使用特殊格式 连接到 AthenaSymlinkTextInputFormat以及清单文件的位置。
在样例代码中,清单文件是在s3a: / / aws-airlifts / movies_delta _symlink_format_ 清单/文件的位置。
步骤4
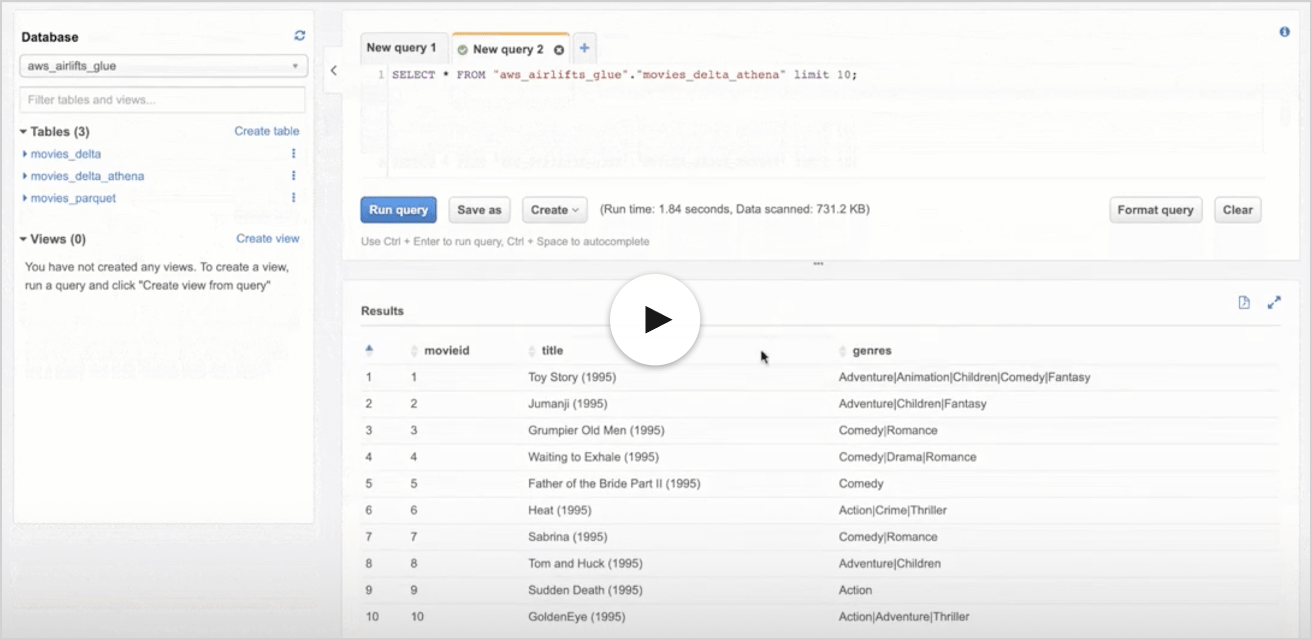
使用Amazon Athena查询Delta Lake表
亚马逊雅典娜
Athena是一种无服务器服务,不需要任何基础设施来管理和维护。因此,您可以查询Delta表,而不需要Databricks集群运行。
从Amazon Athena控制台选择数据库,然后像视频中显示的那样预览表。
结论
集成AWS Glue为所有使用AWS生态系统的企业提供了强大的无服务器metastore策略。通过Delta Lake提升数据湖的可靠性,并通过与Amazon Athena集成提供无缝、无服务器的数据访问。Databricks Lakehouse平台支持Abob体育客户端下载WS上的数据湖策略,使数据分析师、数据工程师和数据科学家能够获得高性能和可靠的数据访问。


