Apache Spark란?
Apache Spark는빅데이터워크로드에쓰이는오픈소스분석엔진입니다。배치는물론실시간분석과데이터처리워크로드도처리할수있습니다。Apache火花는2009년캘리포니아대학교버클리캠퍼스에서연구프로젝트로시작되었습니다。연구진은하둡시스템에서처리작업의속도를높일방법을강구하고있었습니다。이엔진은하둡MapReduce기반이었으며MapReduce모델을확장하여더많은연산유형에이를효율적으로이용하고자하였는데,인터랙티브쿼리와스트림처리등이대표적인예입니다。火花는Java, Scala, Python과R프로그래밍언어에네이티브바인딩을제공합니다。또한여러개의라이브러리를포함하여머신러닝빌드애플리케이션을지원하고(MLlib)스트림처리(火花流)및그래프처리(GraphX)도지원합니다。Apache Spark는Spark Core와일련의라이브러리로구성되어있습니다。火花核心는Apache火花의핵심이며분산형작업전송,일정예약I / O과기능제공을담당합니다。火花核心엔진은抽样(弹性分布式数据集)개념을기본데이터유형으로사용합니다。Rdd는사용자에게대부분의연산복잡성을숨기도록고되어있습니다。火花는데이터에작용하는방식이지능적이라데이터와파티션이서버클러스터하나를가로질러집계된다음컴퓨팅을거쳐다른데이터스토어로이동하거나분석모델을거쳐가게됩니다。사용자에게는파일을저장하거나검색하기위해파일목적지를지정하거나어느연산리소스를사용할지지정하라는요청을하지않습니다。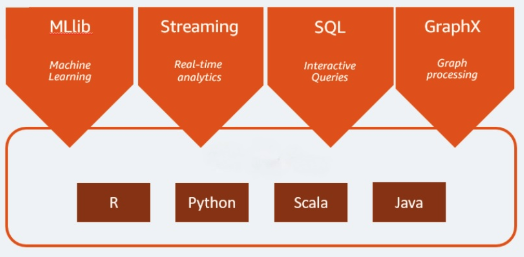
Apache Spark의장점은무엇입니까?
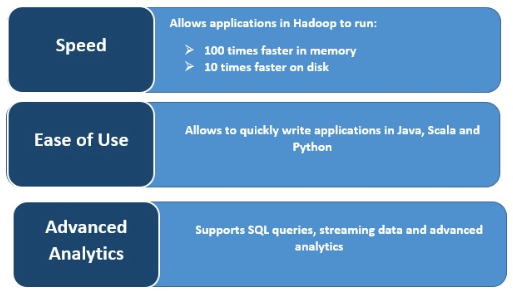
속도
火花는여러개의병렬작업에걸쳐데이터를메모리에캐시하여무척빠른실행속도를자랑합니다。火花의주된특징은메모리내(内存)엔진으로서처리속도를높여대규모데이터처리에관한한메모리내에서처리MapReduce시대비최고100배빠르고디스크에서처리시10배빠르다는점입니다。火花는디스크작업을대상으로하는읽기/쓰기작업의수를줄여이런결과를달성합니다。
실시간스트림처리
Apache火花는실시간스트리밍을처리하기도하고,다른프레임워크와통합할수도있습니다。火花는미니배치형태로데이터를수집하여그러한데이터미니배치에抽样변환을수행합니다。
여러워크로드지원
Apache Spark는여러개의워크로드를실행할수있습니다。터랙티브쿼리,실시간분석,머신러닝과그래프처리등이모두포함됩니다。한개의애플리케이션이여러워크로드를원활하게조합할수있습니다。
사용편리성가
Spark는여러가지프로그래밍언어를지원할수있기때문에동적입니다。즉Java, Scala, Python및R로신속하게애플리케이션을작성할수있는등,애플리케이션을빌드할때다양한언어선택권을부여합니다。
고급 분석
Spark는SQL쿼리,머신러닝,스트림처리와그래프처리를지원합니다。