
머신러닝모델이란무엇입니까?
머신러닝모델이란이전에접한적없는데이터세트에서패턴을찾거나이를근거로결정을내릴수있는프로그램입니다。예를들어자연어처리의경우,머신러닝모델은파싱을통해이전에접한적없는문장이나단어조합의배후의도를올바로인식할수있습니다。이미지인식의경우,머신러닝모델이자동차나개등사물을인식하도록교육할수있습니다。머신러닝모델은대규모데이터세트로”교육”하면이러한작업을수행할수있게됩니다。교육을하면서머신러닝알고리즘이데이터세트에서특정패턴이나출력(작업종류에따라)을찾아내게최적화합니다。이프로세스의출력물은대개특정규칙과데이터구조를포함한컴퓨터프로그램의형태를띠는데,이것을머신러닝모델이라고합니다。
머신러닝알고리즘이란무엇입니까?
머신러닝알고리즘은일련의데이터에서패턴을찾기위한수학적방식입니다。머신러닝알고리즘은대개통계,미적분,선형대수에서도출합니다。머신러닝의보편적인예를들자면선형회귀,결정트리,랜덤포레스트와XGBoost등이있습니다。
머신러닝에서모델훈련이란무엇입니까?
어느데이터세트(이를교육데이터라함)에서머신러닝알고리즘을수행하고이알고리즘을특정패턴이나출력을찾게최적화하는프로세스를모델훈련이라고합니다。그결과로도출된,규칙과데이터구조를포함한함수를훈련된머신러닝모델이라고합니다。
머신러닝의여러가지유형으로는어떤것이있습니까?
,대전반적으로부분의머신러닝기법은지도학습,비지도학습과강화학습으로분류할수있습니다。
지도학습머신러닝이란무엇입니까?
지도학습머신러닝의경우,알고리즘에입력데이터세트가제공되며특정출력세트에부합하도록보상이주어지거나최적화됩니다。예를들어지도학습머신러닝은이미지인식에광범위하게활용되는데,이경우분류라는기법을활용합니다。지도학습머신러닝은인구성장이나건강지표와같은인구통계예측에도쓰이며,이경우회귀라는기법을활용합니다。
비지도학습머신러닝이란무엇입니까?
지도학습머신러닝의경우,알고리즘에입력데이터세트는제공하지만특정출력으로보상되거나최적화되지는않고,그대신공통된특징에따라개체를그룹으로묶도록교육합니다。예컨대온라인매장의추천엔진은비지도학습머신러닝,그중에서도특히클러스터링이라는기법을주로이용합니다。
강화학습머신러닝이란무엇입니까?
강화학습(强化学习)의경우,알고리즘이수많은시행착오실험을통해자체적으로훈련하도록설정됩니다。강화학습은알고리즘이훈련데이터에의존하는것이아니라주변환경과계속상호작용을주고받을때일어납니다。강화학습의가장보편적예시가바로자율주행입니다。
여러가지머신러닝모델의예를들면어떤것이있습니까?
머신러닝모델에도여러가지종류가있으며,거의전부가특정머신러닝알고리즘기반입니다。보편적인분류와회귀알고리즘은지도학습(监督)머신러닝에속하며,클러스터링알고리즘은대개비지도학습(无监督)머신러닝시나리오로배포됩니다。
지도학습머신러닝
- 로지스틱회귀:로지스틱회귀(逻辑回归)는어느입력이특정그룹에속하는지아닌지판단하는데쓰임
- 支持向量机:支持向量机,즉서포트벡터머신(支持向量机)은n차원공간에서각개체의좌표를만들고,초평면을사용해여러개체를공통된특징에따라그룹으로묶음
- 朴素贝叶斯:朴素贝叶斯는변수간에비종속성이성립한다고가정하고확률을사용해기능에따라개체를분류하는알고리즘
- 결정트리:결정트리(决策树)도분류자의일종으로,트리의잎과노드를횡단이동하여주어진입력이어느카테고리에속하는지판단하는데쓰임
- 선형회귀:선형회귀는관심사와입력변수사이의관계를파악하고,입력변수값에따라그값을예측하는데쓰입니다。
- 资讯:k最近的邻居기법은가장가까운개체를하나의데이터세트로그룹화한다음개체중에서가장자주나타나거나평균적인특징을찾아내는것위주입니다。
- 랜덤포레스트(随机森林):랜덤포레스트(随机森林)는무작위데이터하위집합에서가져온수많은결정트리를모은컬렉션입니다。따라서결정트리하나만사용할때보다좀더정확한예측을내놓을수있는트리조합이생깁니다。
- 助推알고리즘:梯度助推机,XGBoost와LightGBM등의助推알고리즘은앙상블학습을사용합니다。이알고리즘은여러알고리즘(예:결정트리)에서가져온예측을조합하되,이전알고리즘에서발생한오류를고려합니다。
비지도학습머신러닝
- K - means: K - means알고리즘은여러개체의유사상을찾아이를K개의서로다른클러스터로그룹화합니다。
- 계층적클러스터링:계층적클러스터링의경우클러스터수를지정할필요없이중첩된클러스터트리를구축합니다。
머신러닝(ml)에서결정트리란무엇입니까?
决策树是ML中的一种预测方法,用于确定对象属于哪个类。顾名思义,决策树是一种树状的流程图,其中对象的类别是使用某些已知条件逐步确定的。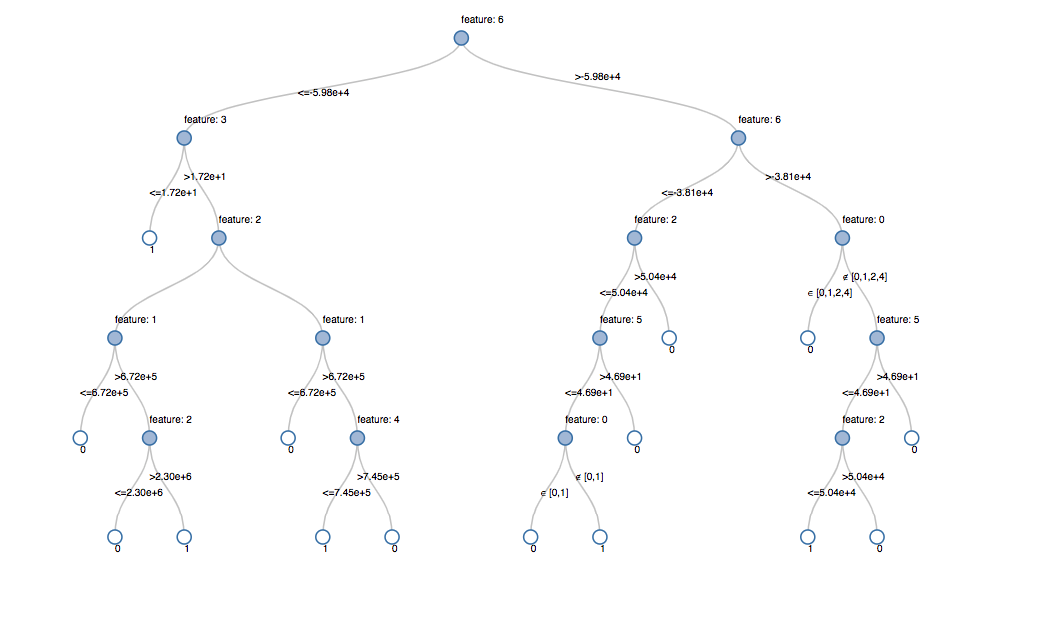 在Databricks Lakehouse中可视化的决策树。来源://www.neidfyre.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
在Databricks Lakehouse中可视化的决策树。来源://www.neidfyre.com/blog/2019/05/02/detecting-financial-fraud-at-scale-with-decision-trees-and-mlflow-on-databricks.html
머신러닝에서회귀란무엇입니까?
数据科学和机器学习中的回归是一种统计方法,能够根据一组输入变量预测结果。结果通常是一个变量,它取决于输入变量的组合。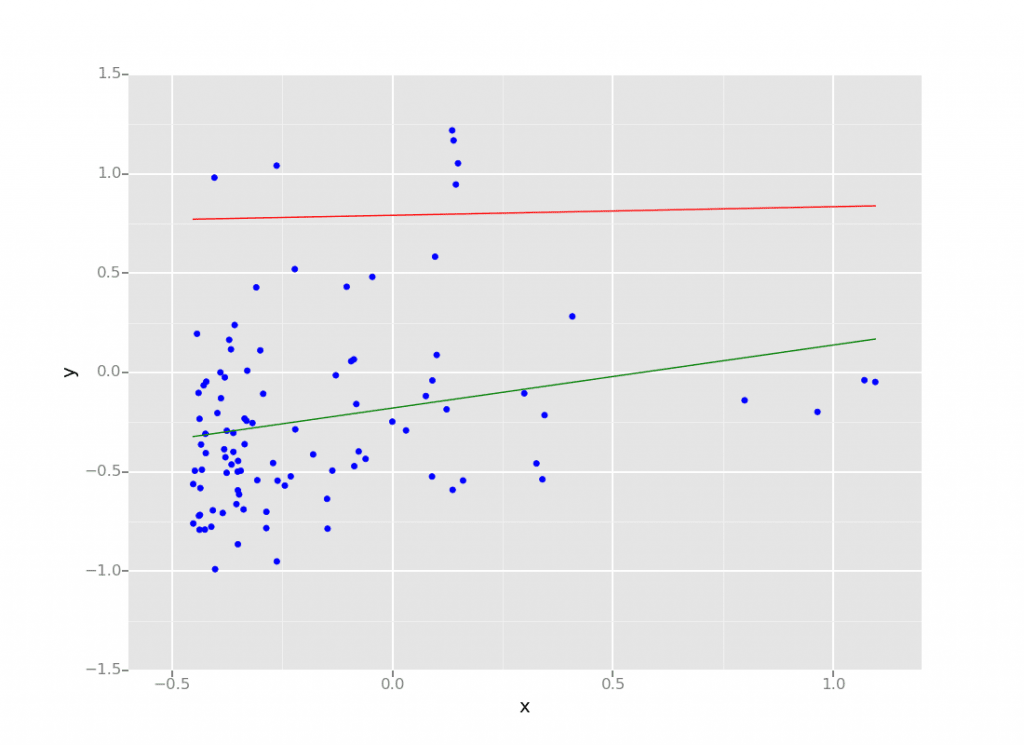 线性回归模型在Databricks Lakehouse上进行。来源://www.neidfyre.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
线性回归模型在Databricks Lakehouse上进行。来源://www.neidfyre.com/blog/2015/06/04/simplify-machine-learning-on-spark-with-databricks.html
머신러닝에서분류자란무엇입니까?
분류자란어느개체를카테고리나그룹의구성원으로할당하는머신러닝알고리즘입니다。예를들어분류자를사용하여이메일이스팸인지아닌지,트랜잭션이사기행위인지아닌지탐지할수있습니다。
머신러닝모델은몇개나됩니까?
많습니다!머신러닝은지금도발전중인분야이며,개발중인머신러닝모델은계속늘어나고있습니다。
머신러닝에가장좋은모델은무엇입니까?
특정상황에가장적합한머신러닝모델은바람직한결과가무엇이냐에따라다릅니다。예를들어어느도시에서과거데이터를바탕으로차량구매수를예측하려하는경우,선형회귀와같은지도학습기법이가장유용할수있습니다。반면이도시의어느잠재고객이차량을구매할지그고객의소득과통근기록에따라결과를알아보고자하는경우,결정트리가가장효과적일수있습니다。
머신러닝(ml)에서모델배포란무엇입니까?
模型部署是使机器学习模型可用于目标环境(用于测试或生产)的过程。该模型通常通过api与环境中的其他应用程序(如数据库和UI)集成。部署是一个阶段,在这个阶段之后,组织可以实际地从在模型开发中所做的大量投资中获得回报。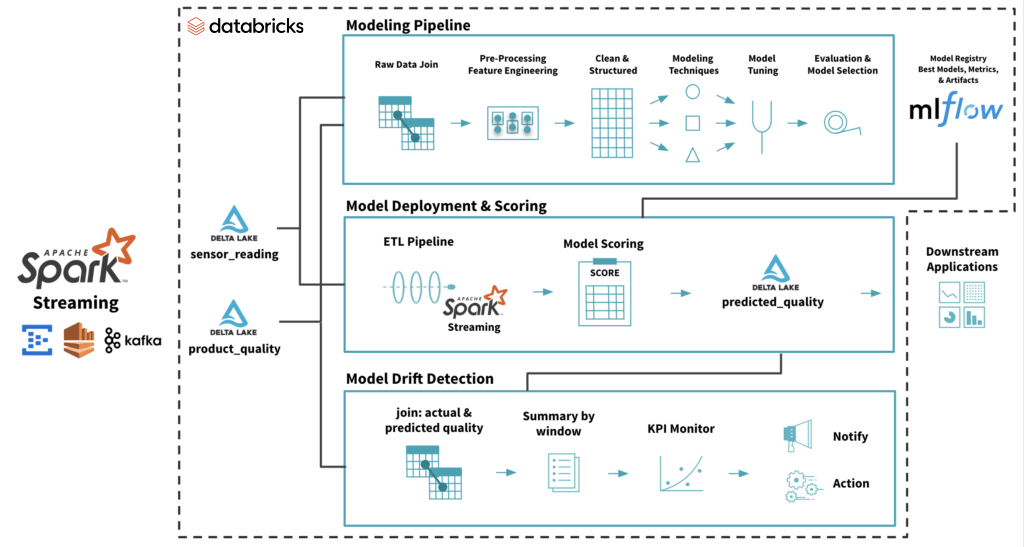 在Databricks Lakehouse上的完整机器学习模型生命周期。来源://www.neidfyre.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
在Databricks Lakehouse上的完整机器学习模型生命周期。来源://www.neidfyre.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html
딥러닝모델이란무엇입니까?
深度学习模型是一类模仿人类处理信息方式的机器学习模型。该模型由几个处理层(因此称为“深度”)组成,从所提供的数据中提取高级特征。每个处理层都将更抽象的数据表示传递给下一层,最后一层提供更类似于人类的见解。与传统的ML模型不同,深度学习模型需要对数据进行标记,可以吸收大量的非结构化数据。它们被用于执行更类似于人类的功能,如面部识别和自然语言处理。 深度学习的简化表示。来源://www.neidfyre.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
深度学习的简化表示。来源://www.neidfyre.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
시계열머신러닝이란무엇입니까?
시계열머신러닝모델의경우,독립된변수중하나가연속된시간길이(분,일년등)이며이것이종속된변수나예측된변수에의미를지니는모델입니다。시계열머신러닝모델은다가오는어느주의날씨,다음어느달의예상고객수,다음어느해매출지표등시간이제한된이벤트를예측하는데쓰입니다。