하둡에코시스템이란무엇입니까?
Apache Hadoop에코시스템이란Apache Hadoop소프트웨어라이브러리를이루는다양한구성요소를말합니다。오픈소스프로젝트는물론광범위한보조툴이많습니다。하둡에코시스템중에서가장잘알려진툴을몇가지만예로들면HDFS Hive Pig YARNMapReduceSpark, HBase, Oozie, Sqoop, Zookeeper등이있습니다。개발자가자주사용하는주하둡에코시스템구성소를소개하면다음과같습니다。
Hdfs란무엇입니까?
Hadoop分布式文件系统(HDFS)은Apache에서가장큰프로젝트중하나이며하둡의기본스토리지시스템입니다。NameNode와DataNode아키텍처를사용합니다。분산형파일시스템으로상용하드웨어클러스터에서실행되는큰파일을저장할수있습니다。
Hive란무엇입니까?
蜂巢는하둡에코시스템내에저장된대형数据集를쿼리하거나분석하는데쓰이ETL및는데이터웨어하우징툴입니다。Hive에는크게세가지기능이있습니다。데이터약,쿼리,그리고하둡에저장된비구조적,반구조적데이터분석입니다。여기에는SQL과유사한인터페이스,SQL과작동원리가비슷한HQL언어가있어쿼리를자동으로MapReduce작업으로변환합니다。
Apache Pig란무엇입니까?
하둡내에서쓰이는크기가큰数据集의쿼리를실행하는데쓰는고수준스크립팅언어입니다。猪의단순하고SQL과비슷한스크립팅언어를일명拉丁语이라고하며,이언어의주된목표는필요한작업을수행하고최종출력을바람직한형식으로배열하는데있습니다。
MapReduce란무엇입니까?
 하둡의데이터처리계층의일종입니다。여기에는크기가큰구조적데이터,비구조적데이터를처리하는기능도있고크기가매우큰파일을병렬식으로관리할수도있습니다。이를위해작업을일련의독립적작업(子工作,하위작업)으로나눕니다。
하둡의데이터처리계층의일종입니다。여기에는크기가큰구조적데이터,비구조적데이터를처리하는기능도있고크기가매우큰파일을병렬식으로관리할수도있습니다。이를위해작업을일련의독립적작업(子工作,하위작업)으로나눕니다。
纱线이란무엇입니까?
纱은另一个资源谈判의약어인데,통상약어만써서지칭합니다。Apache Hadoop의이것은오픈소스핵심구성요소중하나로,리소스관리에적합합니다。워크로드관리,모니터링,보또한시스템리소스를하둡클러스터에서실행되는다양한애플리케이션에할당하면서동시에각각의클러스터노드에서어느작업을실행하는것이좋은지할당하기도합니다。Yarn은크게두가지구성소로이루어져있습니다。
- 리소스관리자
- 노드관리자
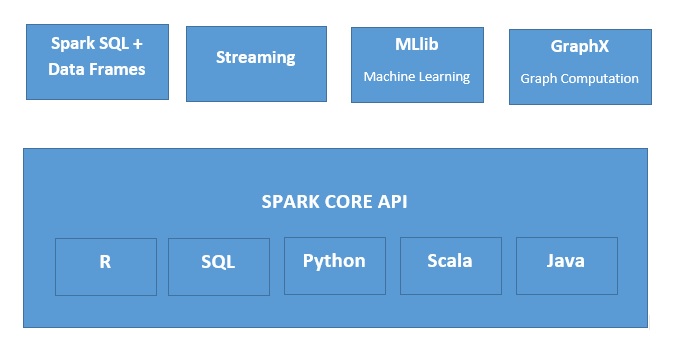
Apache Spark란?
Apache火花는무척광범위한상황에사용하기적합한고속,메모리내데이터처리엔진입니다。火花는여러가지방식으로배포할수있고Java、Python、Scala와R프로그래밍언어를포함하며SQL스트리밍데이터,머신러닝과그래프처리를지원하여주어진애플리케이션한개에서이를함께사용할수있습니다。