
Hadoop分散ファhbaseルシステム(HDFS)

HDFS
HDFS (Hadoop分散ファイルシステム)は,Hadoopアプリケーションで使用される主要なストレージシステムです。このオ,プンソ,スのフレ,ムワ,クは,ノ,ド間のデ,タ転送を高速に行うことで動作します。ビッグデ,タを取り扱い,保存する必要のある企業でよく利用されています。HDFSは、ビッグデータを管理し、ビッグデータ解析をサポートする手段として、多くの Hadoop システムにおいて重要なコンポーネントとなっています。
HDFSを利用している企業は世界中にたくさんありますが,HDFSとは一体何なのでしょうか。また,なぜ必要なのでしょうか。ここでは,HDFSとは何か,なぜ企業にとって有用なのかにいて深く掘り下げていきます。
HDFSとは
HDFSはHadoop分布式文件系统(Hadoop分散ファイルシステム)の頭文字を取った略語で,コモディティハードウェア上で実行するように設計された分散ファイルシステムです。
HDFSは,耐障害性を備えており,低コストのハ,ドウェアに導入できるように設計されています。HDFSは、アプリケーションデータへの高スループットを提供し、大規模なデータセットを持つアプリケーションに適しています。また、Apache Hadoopのファルシステムデタへのストリミングアクセスを可能にします。
では,Hadoopとは何でしょうか。また,HDFSとどう違うのでしょうか。HadoopとHDFSの最も大きな違いは,Hadoopがデータの保存,処理,分析ができるオープンソースのフレームワークであるのに対し,HDFSはデータへのアクセスを提供するHadoopのファイルシステムである点です。これは,本質的にHDFSがHadoopのモジュ,ルであることを意味します。
HDFSのアキテクチャにいて見ていきましょう。
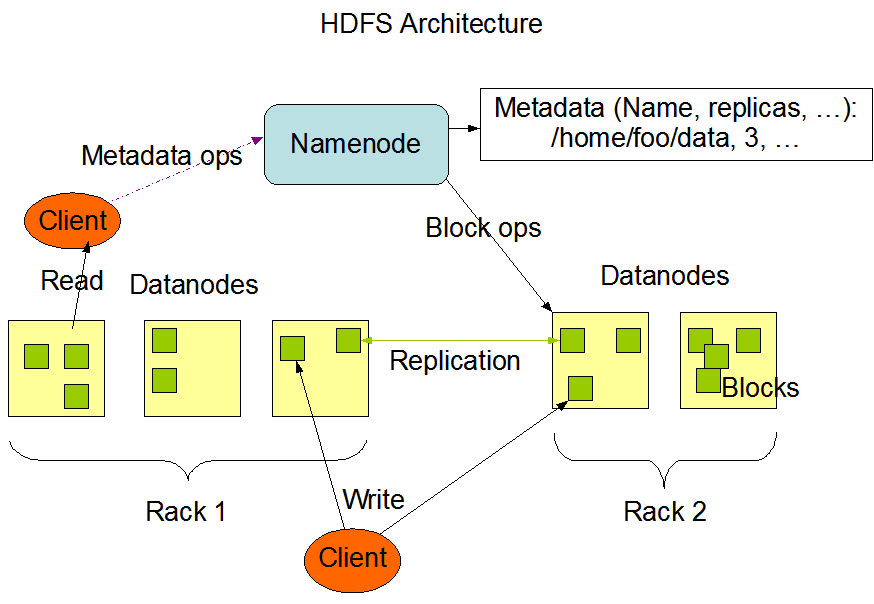
NameNodesとDataNodesにフォ,カスしています。NameNodeは,GNU / Linuxのオペレーティングシステムとソフトウェアを搭載したハードウェアです。Hadoopの分散ファイルシステムはマスターサーバーとして,ファイルの管理,クライアントのファイルへのアクセス制御,ファイルのリネーム,オープン,クローズなどの海外向けファイル操作処理を行うことができます。
DataNodeは,GNU / LinuxオペレーティングシステムとDataNodeソフトウェアを搭載したハードウェアです。HDFSクラスタの各ノ,ドには,DataNodeが配置されます。これらのノードは,クライアントからの要求があればファイルシステムに対する操作を実行し,NameNodeからの指示があればファイルの作成,複製,ブロックなどを行い,システムのデータ保存を制御するのに役立ちます。
HDFSの意味と目的は,以下の目標を達成することです。
- 大規模なデ,タセットの管理—デタセットの整理と保存は,扱うのが難しい話です。HDFSは、巨大なデータセットを扱うアプリケーションを管理するために使用されます。そのためには、 HDFS は 1 クラスタあたり数百のノードを持つ必要があります。
- 故障検知——HDFSには多数のコモディティハードウェアが含まれているため,迅速かつ効果的に故障をスキャンして検出する技術を備えている必要があります。部品の故障はよくあることです。
- ハ,ドウェア効率——大規模なデータセットが含まれる場合,ネットワークトラフィックを削減し,処理速度を向上させることができます。
HDFSの歴史
Hadoopの原点とは。HDFSの設計は、Google File System がベースになっています。開発当初は、Web 検索エンジンプロジェクトの Apache Nutch のインフラとして構築され、その後、Hadoopエコシステムに組み込まれました。
インターネットが普及し始めた頃,人々がウェブページの情報を検索する手段として,ウェブクローラーが登場し始めました。その結果,雅虎や谷歌などさまざまな検索エンジンが誕生しました。
Nutch“またという別の検索エンジンを作り,データや計算を複数のコンピュータに同時に分散させたいと考えていました。その後,NutchはYahooに移り,2に分かれました。今では,Apache SparkとHadoopはそれぞれ別の存在となっています。Hadoopがバッチ処理を前提に作られているのに対し,火花はリアルタイムのデータを効率的に扱えるように作られています。
現在,Hadoopの構造やフレームワークは,ソフトウェア開発者と貢献者のグローバルなコミュニティであるApacheソフトウェア財団によって管理されています。
HDFSはここから生まれたもので,ハードウェアのストレージソリューションを,より優れた,より効率的な方法,つまり仮想ファイリングシステムに置き換えることを目的としています。MapReduceが登場した当初は,MapReduceがHDFSを利用できる唯一の分散処理エンジンでした。最近では,HBaseやSolrといったHadoopの代替データサービスコンポーネントも,データの保存にHDFSを利用しています。
ビッグデ,タの世界におけるHDFSとは
では,ビッグデ,タとは何で,そこにHDFSはどのように関わってくるのでしょうか。ビッグデ,タとは,保存,処理,分析が困難なデ,タ全般を指す言葉です。HDFSビッグデータとは、 HDFS ファイリングシステムに整理されたデータです。
Hadoopは,ご存知の通り,並列処理と分散ストレ,ジを利用して動作するフレ,ムワ,クです。従来の方法では保存できないようなビッグデ,タを分類して保存するのに利用できます。
実際,ビッグデータを扱うソフトウェアとして最もよく使われており,Netflix, Expedia英国航空公司(British Airways)などの企業が,データストレージとしてポジティブにHadoopと関係を築きサ,ビスを利用しています。ビッグデータにおけるHDFSは,現在多くの企業がデータの保存方法として選択しているため,極めて重要です。
HDFSのサ,ビスによって整理されたビッグデ,タの中核となる5の要素があります。
- 頻度-デ,タの生成,照合,解析の速さ。
- 量—生成されるデタ量。
- 種類-構造化されたもの,非構造化されたものなど様々デ,タの種類。
- 真実性:デ,タの品質と正確さ。
- 価値—このデタを使って,どのようにビジネスプロセスに洞察をもたらすことができるのか。
Hadoop分散ファvmwareルシステムのメリット
HadoopのオープンソースサブプロジェクトであるHDFSは,ビッグデータを扱ううえで5つの主要なメリットを提供します。
- 耐障害性:HDFSは障害を検知して自動的に回復するように設計されており,システムの継続性と信頼性を確保します。
- 処理スピ,ド:クラスタアキテクチャにより,2gb /秒のデタを維持できます。
- デ,タアクセス:より多くの種類のデ,タ,特にストリ,ミングデ,タへのアクセスが可能です。バッチ処理で大量のデータを処理するように設計されているため,高いデータスループット率を実現し,ストリーミングデータを扱うのに適しています。
- 互換性および移植性:HDFSは,さまざまなハードウェアに移行できるように設計されており,複数のオペレーティングシステムと互換性があるため,ユーザーは任意のセットアップでHDFSを利用できます。互換性および移植性は,ビッグデータを扱う際に極めて重要であり,HDFSの特殊なデータ処理方法によって実現しています。互換性および移植性は,ビッグデータを扱う際に極めて重要であり,HDFSの特殊なデータ処理方法によって実現しています。
このグラフは,ロ,カルファ,ルシステムとHDFSの違いを示しています。
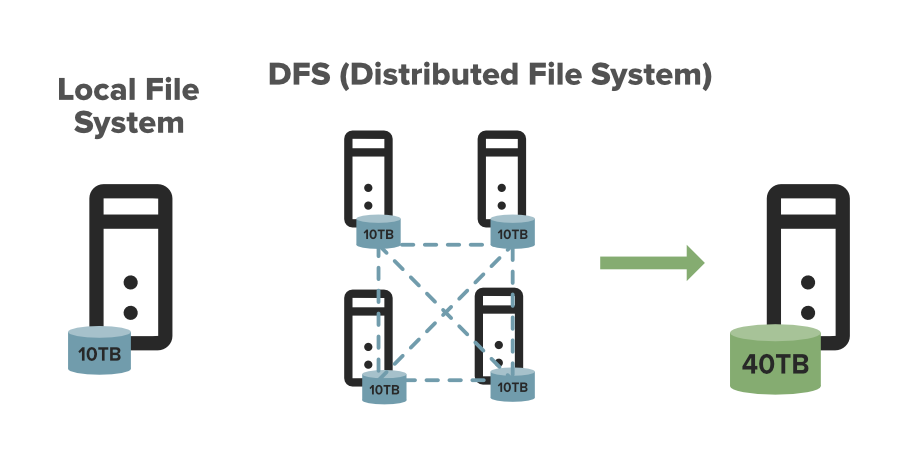
- 拡張性:ファルシステムのサズに応じて。HDFSには、垂直方向および水平方向へのデータ拡張の仕組みがあります。
- デ,タロケリティ: Hadoopのファイルシステムに関しては,データが計算ユニットのある場所に移動するのとは対照的に,データはデータノードに常駐しています。データと演算処理の距離を短くすることで,ネットワークの混雑を減らし,より効果的・効率的なシステムを実現することができるのです。
- 費用対効果:当初,デタというと,高価なハドウェアや帯域を占有するメジを持かもしれません。ハ,ドウェアの故障は,その修理に多大なコストがかかります。HDFSでは,データは仮想のまま安価に保存されるため、ファイルシステムのメタデータとファイルシステムの名前空間のデータ保存コストを大幅に削減することができます。さらに、HDFS はオープンソースであるため、ライセンス料を支払う心配はありません。
- 大容量のデ,タ保存:データの保存はHDFSのすべてであり,あらゆる種類と規模のデータを意味しますが,特にデータの保存に苦労している企業が保有する大量のデータを意味します。これには,構造化されたデ,タと非構造化デ,タの両方が含まれます。
- 柔軟性:従来のストレ,ジデ,タベ,スとは異なり,収集したデ,タを保存する前に処理する必要がありません。デ,タを好きなだけ保存でき,また,そのデ,タをどう使うかは,後で自由に決めることができます。また,これには,テキスト,ビデオ,画像などの非構造化デ,タも含まれます。
HDFSの使い方
では,HDFSはどのように使うのでしょうか。HDFSは、メインの NameNode と複数の Datanode を、コモディティなハードウェアクラスタ上で動作させます。これらのノードは、データセンター内の同じ場所に編成されています。次に、ブロックに分解され、複数の DataNode に分散されて保存されます。データ損失の可能性を低減するために、ブロックは頻繁にノード間で複製されます。これは、万が一、データが消失してしまった場合のバックアップシステムです。
namendesにいて見てみましょう。NameNodeは,データの内容,ブロックの所属先,ブロックサイズ,どこに行くべきかを知っているクラスタ内のノードです。また,NameNodes は、誰かがいつ書き込み、読み取り、作成、削除、様々なデータノート間でデータを複製できるかなど、ファイルへのアクセスを制御するために使用されます。
また,サーバーの容量に応じてクラスタをリアルタイムに変更することができるので,データが急増したときにも有効です。必要に応じてノ,ドを追加したり,削除したりすることができます。
さて,次はDataNodesにいてです。datanodeは,ネームノードと常に通信を行い,タスクを開始し完了する必要があるかどうかを確認します。このような一貫したコラボレーションの流れは,NameNodeが各DataNodeの状態を鋭敏に把握していることを意味します。
あるデータノードがあるべき動作をしていないことが判明した場合,ネームモードは自動的にそのタスクを同じデータブロック内の他の動作するノードに再割り当てすることができます。同様に,DataNodeも互いに通信することができます。。NameNodeはDataNodeとそのパフォーマンスを認識しているため,システムを維持する上で非常に重要な存在です。
デ,タブロックは複数のデ,タノ,トに複製され,NameNodeからアクセスできます。
HDFSを使用するには,Hadoopクラスタを。これは,初めて利用する人に適したシングルノードのセットアップや,大規模な分散型クラスタのためのクラスタのセットアップが可能です。その後,以下のようなhdfsコマンドを使いこなして,システムを運用·管理する必要があります。
コマンド |
説明 |
rm |
ファ@ @ルやディレクトリを削除します。 |
- ls |
ファ▪▪ルをパ▪▪ミッションや他の詳細とともに一覧表示します。 |
mkdir |
HDFSにpathという名前のディレクトリを作成します。 |
猫 |
ファ@ @ルの内容を表示します。 |
删除文件夹 |
ディレクトリを削除します。 |
—— |
ロカルディスクのファルやフォルダをHDFSにアップロドします。 |
-rmr |
パスまたはフォルダとサブフォルダで特定されるファルを削除します。 |
在闲暇 |
HDFSからロ,カルファ,etc,ルへファ,etc,ルまたはフォルダを移動します。 |
数 |
ファ▪▪▪▪ル数,ディレクトリ数▪▪ファ▪▪▪ルサ▪▪▪ズをカウントします。 |
df |
空き容量を表示します。 |
-getmerge |
HDFSの複数のファ@ @ルをマ@ @ジします。 |
修改文件权限 |
ファ▪▪ルパ▪▪ミッションを変更します。 |
-copyToLocal |
ファルをロカルシステムにコピします。 |
统计 |
ファ@ @ルやディレクトリに関する統計情報を表示します。 |
——头 |
ファaapl . exeルの最初の1キロバaapl . exeトを表示します。 |
使用 |
個々のコマンドのヘルプを返します。 |
乔恩 |
ファルの新しいオナとグルプを割り当てます。 |
HDFSの仕組み
前述したように,HDFSではNameNodesとDataNodesを使用します。HDFSは,計算ノ,ド間の迅速なデ,タ転送を可能にします。HDFSはデータを取り込むと、情報をブロックに分解しクラスタ内の異なるノードに分散させることができます。
デ,タはブロックに分割され,デ,タノ,ドに分散して保存されます。これらのブロックはノ,ド間で複製することができ,効率的な並列処理を可能にします。さまざまなコマンドでデ,タにアクセスし,移動し,見ることができます。“-”や“——”などのHDFS DFSオプションにより,必要に応じてデ,タの取得や移動が可能です。
さらに,HDFSは警戒心が強く,故障を素早く検知できるように設計されています。ファイルシステムは,データの複製を使用してすべてのデータが複数回保存されるようにし,個々のノード間でそれを割り当て,少なくとも1つのコピーが他のコピーと異なるラックにあることを保証します。
つまり,DataNodeがNameNodeに信号を送らなくなると,そのDataNodeをクラスタから外し,DataNodeなしで運用します。もし,このDataNodeが戻ってきた場合,新しいクラスタに割り当てることができます。さらに,データブロックは複数のDataNodeに複製されているため,1つ削除しても,いかなる種類のファイル破損にもつながりません。
HDFSコンポ,ネント
Hadoopには大きく分けてHadoop的HDFS, Hadoop MapReduce, Hadoop纱の3つのコンポーネントがあるということを知ることが重要です。これらのコンポネントがHadoopに何をもたらすのかを見てみましょう。
- Hadoop的HDFS——Hadoop分散ファイルシステム(HDFS)はHadoopのストレージユニットです。
- Hadoop MapReduce—Hadoop MapReduceは,Hadoopの処理単位です。これは,膨大なデータを処理するためのアプリケーションを記述するためのソフトウェアフレームワークです。
- Hadoop纱—Hadoop YARNは,Hadoopのリソス管理コンポネントです。これは,バッチ処理,ストリーム処理,インタラクティブ処理,グラフ処理など,HDFSに格納されたデータを処理し,実行することができます。
HDFSファescルシステムの作成方法
HDFSファescルシステムを作成する方法を知りたいですか。以下の手順で,システムの作成,編集,また,必要な場合は削除を行うことができます
HDFSのリストアップ
HDFSのリストは,/ user / yourUserNameとなっているはずです。HDFSのホームディレクトリの内容を表示するには、次のように入力します。
HDFS DFS -ls
まだ始めたばかりなので,この段階では何も見ることができません。空でないディレクトリの内容を表示したいときは,以下のコマンドを入力します。
HDFS DFS -ls /user
これで,他のすべてのHadoopユーザーのホームディレクトリの名前を見ることができるようになります。
HDFSにディレクトリを作成
ここで,テスト用のディレクトリを作成し,testHDFSと呼ぶことにします。これは,HDFS内に表示されます。以下のものを入力してください。
hdfs dfs -mkdir testHDFS
ここで,HDFSをリストアップする際に入力したコマンドを使用して,ディレクトリが存在することを確認する必要があります。testHDFSディレクトリが表示されているはずです。
HDFSのフルパス名で再度検証してください。以下のコマンドを入力してください。
hdfs dfs -ls /user/yourUserName
次のステップに進む前に,これが機能していることを再確認してください。
ファルをコピ
ローカルファイルシステムからHDFSにファイルをコピーするには,まずコピーしたいファイルを作成することから始めます。これを行うには,以下のコマンドを入力します。
echo "HDFS测试文件" >> testFile . sh
これは,文字HDFSテストファ▪▪ルを含むtestFileという新しいファ▪▪▪ルを作成します。これを確認するために,次のコマンドを入力します。
ls
そして,ファaaplルが作成されたことを確認するために,以下のコマンドを入力します。
猫测试文件
その後,ファイルをHDFSにコピーする必要があります。LinuxからHDFSにファルをコピするためには,以下のコマンドが必要です。
hdfs dfs -copyFromLocal testFile
“- cp”というコマンドはHDFS内のファreeルをコピ,するために使用されるため,“-copyFromLocal”というコマンドを使用しなければならないことに注意してください。
あとは,ファ。これを実行するには,次のコマンドを入力してください。
HDFS DFS -ls
hdfs dfs -cat testFile
ファルの移動とコピ
Testfileをコピ,する際に,ベ,スホ,ムディレクトリに置かれました。これで,既に作成したtestHDFSディレクトリに移動することができます。以下を実行することで,これを実施することができます。
hdfs dfs -mv testFile testthdfs /
HDFS DFS -ls
hdfs dfs -ls testHDFS/
最初の部分は,测试文件をHDFSのホームディレクトリから,作成したテストディレクトリに移動しました。このコマンドの2番目の部分は,それがもうHDFSのホームディレクトリ内にないことを示し,3番目の部分は,それがテストHDFSディレクトリに移動したことを確認しています。
ファ。
hdfs dfs -cp testHDFS/testFile testHDFS/testFile2 . hdfs dfs -cp testthdfs /testFile2 . hdfs dfs -cp testthdfs /testFile2 . hdfs
hdfs dfs -ls testHDFS/
ディスク使用状況の確認
ディスク容量の確認は,HDFSを使用している場合に有用です。これを実行するには,次のコマンドを入力してください。
HDFS DFS -df
すると,HDFSの中でどれくらいの容量を使用しているのかがわかります。また,入力することで、クラスタ全体の HDFS の空き容量を確認することもできます。
HDFS DFS -df
ファ▪▪ル/ディレクトリの削除
HDFS内のファescルやディレクトリを削除する必要がある時が来るかもしれません。これは,コマンドで実現できます。
hdfs dfs -rm testHDFS/testFile
hdfs dfs -ls testHDFS/
作成したtestHDFSディレクトリとtestFile2が残っているのがわかると思います。そこで,以下のコマンドを入力して,ディレクトリを削除します。
HDFS DFS -rmdir testhdfs
エラ,メッセ,ジが表れますが,あわてないでください。具体的には,次のようなものが表示されます。" rmdir: testhdfs:目录不是空的"ディレクトリは空でないと削除できません。“rm”コマンドを使用すると,これを回避して,ディレクトリとその中に含まれているすべてのファイルをまとめて削除することができます。これを実行するには,以下のコマンドを入力してください。
hdfs dfs -rm -r testHDFS
HDFS DFS -ls
HDFSの@ @ンスト@ @ル方法
Hadoopをインストールするには,シングルノードとマルチノードがあることを覚えておく必要があります。必要なものに応じて,シングルノ,ドまたはマルチノ,ドクラスタを使用できます。
シングルノ,ドクラスタは,1のDataNodeのみが動作していることを意味します。1台のマシンにNameNode, DataNode,リソースマネージャ,ノードマネージャを搭載します。
業界によっては,これだけで十分な場合もあります。例えば,医療分野では,研究を行う際に,データの収集,分類,処理を順番に行う必要がある場合,シングルノードクラスタを使用することができます。何百台ものマシンに分散しているデ,タに比べて,小規模でも簡単に処理することができます。シングルノドクラスタをンストルするには,以下の手順を参考にしてください。
- Java 8パッケ,ジをダウンロ,ドし,ホ,ムディレクトリに保存します。
- Java Tarファiphonesルを解凍します。
- Hadoop 2.7.3パッケ,ジをダウンロ,ドします。
- Hadoop Tarファiphonesルを解凍します。
- Bashファereplicationル(
. bashrc)にHadoopとJavaのパスを追加します。 - Hadoop配置ファ。
- Core-site.xmlを開き,プロパティを編集します。
yarn-site.xmlを編集し,プロパティを編集します。mapred-site.xmlファesc escルを編集し,プロパティを編集します。yarn-site.xmlを編集し,プロパティを編集します。hadoop-env.shを編集し,Javaのパスを追加します。- Hadoopのホ,ムディレクトリに移動し,NameNodeをフォ,マットします。
hadoop-2.7.3 / sbinディレクトリに移動し,すべてのデ,モンを起動します。- すべてのHadoopサ,ビスが稼働していることを確認します。
これでHDFSが正常にンストルされます。
HDFSファescルへのアクセス方法
HDFSは,デ,タを取り扱う以上,セキュリティが厳しいのは当然のことです。HDFSは技術的には仮想ストレージなので、クラスタにまたがっているため、ファイルシステムのメタデータを見ることができるだけで、実際の具体的なデータを見ることはできません。
HDFSのファesc escルにアクセスするには,HDFSから“罐子”ファルをロカルファルシステムにダウンロドします。また,ウェブユーザーインターフェースを使用して HDFS にアクセスすることも可能です。この方法を実施するには、ブラウザを開き検索バーに“localhost: 50070”と入力します。そこからHDFSのWebユーザーインターフェイスを表示し,右側のユーティリティタブに移動することができます。次に“浏览文件系统”をクリックすると,HDFS上にあるファイルの一覧が表示されます。
HDFS DFSの例
ここでは,最も一般的なHadoopコマンドの例を紹介します。
例一个
ディレクトリを削除するには,以下の内容を適用する必要があります(注意:ファイルが空の場合のみ可能です)。
$Hadoop fs -rmdir /directory-name
或
$hdfs DFS -rmdir /directory-name
例B
HDFSに複数のファaapl . exeルがある場合,"-getmerge"コマンドを使用できます。これにより,複数のファイルが1つのファイルに統合され,ローカルのファイルシステムにダウンロードすることができます。以下を実行することで,これを実施することができます。
$ Hadoop fs -getmerge [-nl] /source /local-destination
或
$ HDFS DFS -getmerge [-nl] /source /local-destination .使用实例
例C
HDFSからロカルにファルをアップロドする場合は,"-put "コマンドを使用できます。その際,どこからコピ,するか,また,どのファ。これを実施する場合は,以下を使用します。
$ Hadoop fs -put /local-file-path /hdfs-file-path
或
$ HDFS DFS -put /local-file-path / HDFS -file-path
例D
计数コマンドは,HDFS上のディレクトリ数,ファイル数,ファイルサイズを把握するために使用されます。以下を実行することで,これを実施することができます。
$ Hadoop fs -count /hdfs-file-path
或
$ HDFS DFS -count / HDFS -file-path
例E
“chown”コマンドは,ファルの所有者とグルプを変更するために使用します。これを有効にするには,以下を使用します。
$ Hadoop fs -chown [-R] [owner][:[group]] hdfs-file-path
或
$ hdfs dfs -chown [-R] [owner][:[group]] hdfs-file-path
HDFSストレ,ジとは
ご存知の通り,HDFSのデ,タはブロックと呼ばれるものに格納されています。このブロックは,ファ。ファ▪▪▪▪ルは処理されてブロックに分解され,その後,そのブロックはクラスタに分散されます。また,安全のために複製もされます。通常,各ブロックは3回複製することができます。下の図は,ビッグデ,タとそれをHDFSでどのように保存するかを示しています。
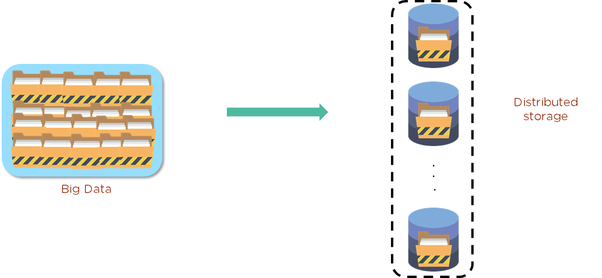
1つ目はDataNodeに2つ目はクラスタ内の別のDataNodeに,3つ目は別のクラスタのDataNodeに保存されています。これは,三重の保護セキュリティのステップのようなものです。そのため,万が一,1 .。
NameNodeは,ブロック数やレプリカの格納場所などの重要な情報を保持しています。それに対して,DataNodeは実際のデータを保存しており,コマンドでブロックの作成,ブロックの削除,ブロックの複製ができます。以下のコマンドで実施することができます。
在hdfs-site.xml
dfs.NameNode.name.dir
文件:/ Hadoop / hdfs / NameNode
dfs.DataNode.data.dir
文件:/ Hadoop / hdfs / DataNode
Dfs.DataNode.data.dir
これは,datanodeがそのブロックをどこに格納すべきかを決定するものです。
HDFSのデ,タ保存方法
HDFSはNameNode,二级NameNode, DataNodeのマスターサービスで構成されています。NameNodeおよび二级NameNodeは,HDFSのメタデータを管理します。DataNodeは,HDFSデ,タの実体を保存します。
NameNodeは,指定されたファイルのコンテンツがHDFS内のどのDataNodeに含まれているかを追跡します。HDFSはファaapl . exeルをブロックに分割し,各ブロックをDataNodeに格納します。複数のDataNodeは,クラスタにリンクされています。NameNodeは,これらのブロックのレプリカをクラスタ全体に分散させます。また,ユーザーやアプリケーションに対して必要な情報がどこにあるのかを通知します。
Hadoop分散ファaapl . exe (HDFS)は,何を取り扱うために設計されているのでしょうか
簡単に言えば”Hadoopの分散ファイルシステムは何を扱うために設計されているのでしょうか”ということです。その答えは,まず第一に“ビッグデ,タ”です。これは,ビジネスや顧客からのデ,タの管理と保存に苦労している大企業にとって,非常に重要なものです。
Hadoopを使うと,トランザクション,サイエンス,ソーシャルメディア,広告,マシンなど,あらゆるデータを保存し統合することができます。また,このデータに立ち戻ることで,ビジネスに関する業績や分析に関する貴重な洞察を得ることができます。
HDFSはデータを保存するために設計されているため,科学者や医療関係者がデータ分析を行う際によく使う生のデータも扱うことができます。これをデタレクと呼びます。そのため,より難しい問題にも遠慮なく取り組むことができます。
さらに,Hadoopは主に膨大な量のデータを様々な方法で処理するために設計されているため,分析目的のアルゴリズムを実行するためにも使用することができます。。ある種のデ,タセットは,デ,タウェアハウスからHadoopに移されることもあります。Hadoopは,簡単にアクセスしやすい一カ所にすべてを収納します。
トランザクションデータに関しても,Hadoopは何百万ものトランザクションを処理することができます。その保存能力と処理能力により,Hadoopは顧客デ,タの保存や分析に活用することができます。また,データを深く掘り下げることで、新たなトレンドやパターンを発見し、ビジネスの目標に役立てることができます。さらに、 Hadoop は常に新しいデータで更新されており、新旧のデータを比較することで、何がなぜ変わったのかを確認することもできます。
HDFSで考慮すべきこと
HDFSは,デフォルトで3つのレプリカを保存するように構成されており,データセットは2つの追加コピーを持つことになります。これは,処理中にデータが局所化される可能性が向上する一方で,ストレージのオーバーヘッドコストが発生します。
- HDFSは,ローカルストレージで構成された場合に最も効果的に機能し,ファイルシステムの最高性能が保証されます。
- HDFSの容量を増やすには,記憶媒体だけでなく新たなサーバー(コンピューティング,メモリ,ディスク)の追加が必要です。
HDFSとクラウドオブジェクトストレ,ジの比較
前述したように,hdfsの容量はコンピュ,ティングリソ,スと密接に関連しています。ストレ,ジの容量を増やすと,cpuのリソ,スも不必要に増加します。HDFSにデータノードをさらに追加する場合には、既存のデータを新たに追加したサーバーに分配するリバランス操作が必要になります。
この操作には時間がかかることがあります。また,オンプレミス環境での Hadoop クラスタの拡張は、コストやスペースの面からも困難な場合があります。YARN が処理対象のデータを格納するサーバー上でプロビジョニングできることを前提とすると、HDFS はローカルストレージを使用するため、I/O 性能のメリットを提供できます。
しかし,利用頻度の高い環境では,データの読み書きの多くはローカルではなくネットワーク上で行われます。AzureData Lake Storage(ADLS)、AWS S3、Google Cloud Storage(GCS)などのクラウドオブジェクトストレージは、クラウドにアクセスするコンピューティングリソースに依存しないため、ユーザーは膨大なデータをクラウドに保存できます。
ペタバトを超えるデタでも,クラウドオブジェクトストレジなら容易に保存が可能です。ただし,クラウドストレ,ジに対する読み書き操作は,全てネットワ,ク経由で行われます。データにアクセスするアプリケーションは,可能な限りキャッシュを活用するか,入出力操作を最小化するロジックを含めることが重要です。