
機械学習モデル,決定木(ディシジョン·)による分析を活用した金融詐欺検知の大規模展開



2019年5月2日 在数据库ブログ
人工知能(AI)を活用した金融不正行為検知の大規模展開は,いかなるユースケースにおいても容易なことではありません。膨大の履歴データの取捨選択,絶えず進化する機械学習と深層学習技術の複雑さ,不正行為の実例の少なさなどが,不正行為パターンの検知を困難にしています。金融サ,ビス業界においては、セキュリティに対する懸念の高まりや、不正行為がどのように特定されたかを説明することの重要性が加わり、複雑さがさらに増大しています。

一般的に,検知パターンを作成するために,まずはドメインエキスパートが不正行為者が行うであろう行為を想定して一連のルールを作成します。ワ,クフロ,に金融詐欺検知の専門家を含めて,特定の動作に関する要件をまとめる場合もあります。その後,データサイエンティストは,利用可能なデータのサブサンプルを取得し,これらの要件と,場合によっては既存の金融不正事例を参照して,深層学習または機械学習アルゴリズムのセットを選択します。そして,データエンジニアが,この検知パターンを本番環境で使用するために,結果として生じるモデルを,しきい値(条件分岐の境目となる値)を持つルールセットに変換します。これには通常,sqlを使用します。
このアプロ,チにより,金融機関は一般デ,タ保護規則(<一个href="https://en.wikipedia.org/wiki/General_Data_Protection_Regulation" target="_blank">GDPR)に準拠した不正取引を特定する明確な特性を提示することができます。しかし,このアプロ,チにもいく,か課題があります。まず,ハ,ドコ,ドされたル,ルセットを使用した不正検出システムの実装は非常に脆弱です。不正パターンに変更を加えると,更新に非常に時間がかかってしまうため,現在の市場で起こっている不正行為の変化に追いついて,対応することが困難です。
さらに,上記のワークフローのシステムは各々がサイロ化(孤立化)されることが多く,ドメインエキスパート,データサイエンティスト,データエンジニアが全て区分化されています。データエンジニアの重要な役割は,膨大な量のデータを管理し,ドメインエキスパートやデータサイエンティストの作業を本番レベルのコードに変換することです。共通のプラットフォームがない場合,ドメインエキスパートとデータサイエンティストは,分析のために単一のマシンに適合するサンプリングされたダウンデータに頼るしかありません。このようなサイロ化された環境では,お互いのコミュニケーションが難しくなり,コラボレーションの欠如につながります。
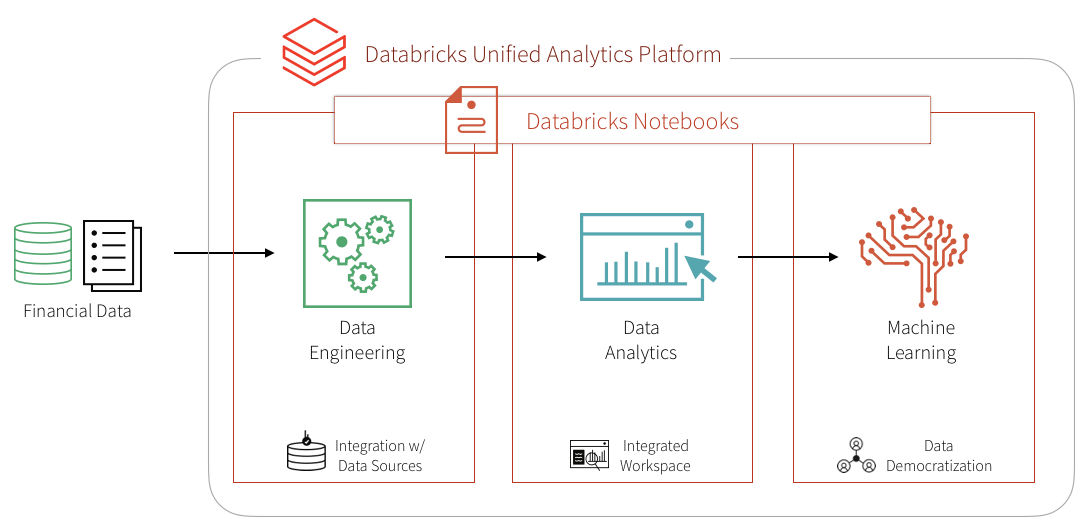
このブログでは,データブリックスを採用して,不正検出のキープレイヤーであるドメインエキスパート,データサイエンティスト,データエンジニアを統合し,いくつかのルールベースの検出ユースケースをデータブリックスのプラットフォーム上の機械学習ユースケースに変換する方法を紹介します。具体的には,大規模なデータセットからモジュラー機能を構築するフレームワークを活用して,機械学習で不正検出データパイプラインを作成し,リアルタイムでデータを視覚化・分析する方法,また,決定木(ディシジョン・ツリー)やApache火花MLlibを採用して不正を検出する方法・メリット・特徴を解説します。その後,MLflowを使用してモデルの反復処理と改良を行い,精度を向上させます。
機械学習によるソリュ,ション
金融業界では,機械学習モデルの採用に比較的消極的な見方があります。それは,特定された不正なケースを正当化できない”ブラックボックス”ソリューションと考えられているためです。GDPR要件と金融規制にデタサエンスの能力を活用することは一見不可能です。しかし,いくつかの成功したユースケースでは,機械学習を適用して大規模に不正行為を検出することで,上述した多くの問題を解決できることが示されています。
実際に確認された不正行為の事例が少ないため,金融不正を検出する”教師あり機械学習モデル”をトレーニングすることは困難です。しかし,特定の不正行為を識別する既知のルールセットの存在は,合成ラベルセットと特徴量の初期セットを作成するのに役立ちます。また,この分野のドメインエキスパートが開発した検出パターンの出力は,適切な承認プロセスを経て本番環境で運用されているはずです。これは,予想される不正行為フラグを生成するので,機械学習モデルをトレーニングするための出発点として使用することができます。これにより,次の3の懸念が同時に軽減されます。
- トレ,ニングラベルの欠如
- 使用する特徴量の決定
- モデルに適したベンチマ,クの有無
ルールベースの不正行為フラグを認識する機械学習モデルをトレーニングすると,混同行列を介して予想される出力と直接比較できます。結果がルールベースの検出パターンと適合していれば,このアプローチによって,不正防止に機械学習を採用することへの信頼を得ることができます。また,このモデルの出力の解釈は非常に簡単なため,元の検出パターンと比較した場合の予想される検出漏れと誤検出の基本的な議論に役立つかもしれません。
決定木(ディシジョンリ)モデルの活用
機械学習モデルの解釈が難しいという懸念は,初期の機械学習モデルとして決定木モデルを使用することで解決できるかもしれません。決定木モデルは一連のルールに従ってトレーニングされているため,決定木は他の機械学習モデルよりも優れています。決定木モデルを使用するさらなるメリット·特徴としては,モデルの最大限の透過性です。このモデルは基本的に不正の意思決定プロセスを示しますが,人間の介入や,ルールやしきい値のハードコーディングを不要にします。もちろん,モデルの将来の反復過程では,最大の精度にするために異なるアルゴリズムを利用する可能性も理解する必要があります。アルゴリズムに組み込まれた特徴を理解しなければ,透過的なモデルは実現できないからです。解釈可能な特徴を持ことで,解釈可能で制御可能なモデルの結果が得られます。
機械学習アプローチを採用する最大のメリットは,初期のモデリング作業の後は,将来の反復がモジュール化され,ラベル,特徴量,あるいはモデルタイプのセットが非常に簡単でシームレスに更新され,運用までの時間が短縮される点です。この作業は,デ,タブリックスの統合分析プラットフォ,ムの採用でさらに促進されます。このプラットフォームでは,ドメインエキスパート,データサイエンティスト,データエンジニアが同じデータセットを大規模に処理し,笔记本環境で直接共同作業を行うことができます。それでは始めましょう。
決定木モデル構築のためのデ,タの取り込みと探索
この例では,合成デ,タセットを使用します。デ,タセットを自分でロ,ドするには,Kaggleからロ,カルマシ,ンに<一个href="https://www.kaggle.com/" target="_blank">ダウンロ,ドし,<一个href="https://docs.microsoft.com/en-us/azure/databricks/data/data" target="_blank">Azureや<一个href="//www.neidfyre.com/docs/data/data.html" target="_blank">AWS経由でデタをンポトしてください。
PaySimデータは,アフリカのある国で実施されたモバイルマネーサービスの1ヶ月の財務ログから抽出した,実際の取引のサンプルに基づくモバイルマネー取引をシミュレーションしたものです。次の表は,デ,タセットが提供する情報を示しています。<一个href="//www.neidfyre.com/www/jp/wp-content/uploads/2019/04/1-Ingest-Data.png">
デ,タの探索
DataFramesを作成します。<一个href="//www.neidfyre.com/docs/data/databricks-file-system.html" target="_blank">Databricksファ电子书阅读器ルシステム(DBFS)にデ,タをアップロ,ドしたので,Spark SQLを使って<一个href="//www.neidfyre.com/www/jp/glossary/what-are-dataframes">DataFramesを迅速か容易に作成できます。
#创建df DataFrame包含我们的模拟财务欺诈检测数据集df=火花。sql("selectstep, type, amount, nameorg, oldbalanceOrg, newbalancorg, nameDest, oldbalanceDest, newbalanceDest from sim_fin_fraud_detection")DataFrameを作成したので,スキ,マと最初の1000行をみてデ,タを確認します。
#查看你的数据的模式df.printSchema() root |——step: integer (nullable =真正的) |——类型:字符串(nullable =真正的|——金额:双(可空=真正的) |——nameOrig:字符串(nullable =真正的|——oldbalanceOrg:双(可空=真正的) |—newbalanceOrig:双(可空=真正的) |——nameDest:字符串(nullable =真正的) |——oldbalanceDest:双(可空=真正的) |—newbalanceDest:双(可空=真正的)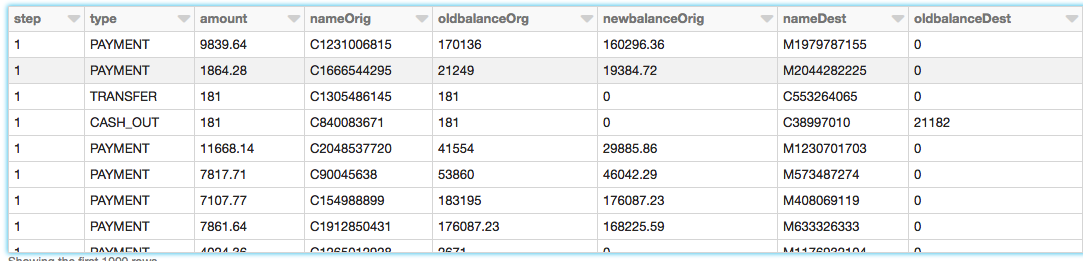
取引の種類
データをわかりやすいように視覚化して,データが捉えた取引の種類と,全体の取引件数に対する割合をみてみましょう。
![]()
また,ここで取り上げているデータの金額がどのくらいかを理解するために,取引の種類と,現金の動きに基づいたデータ(つまり,総取引金額)を視覚化します。
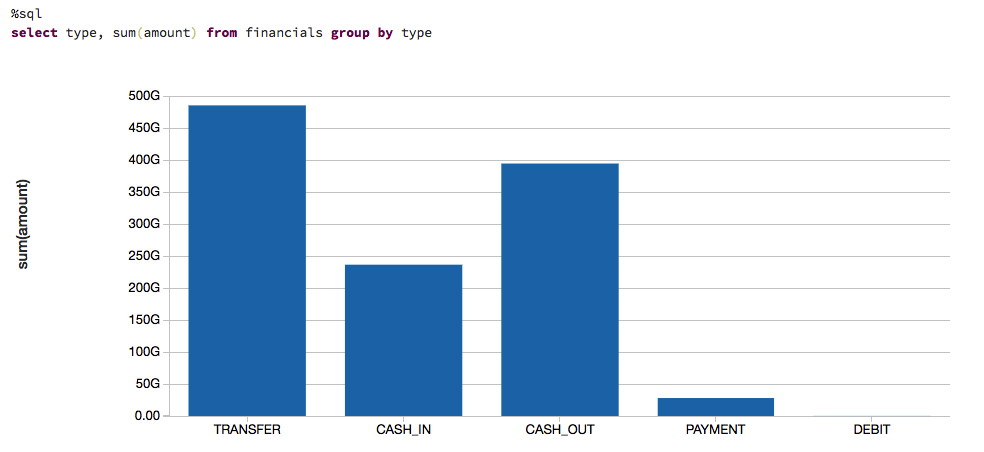
ル,ルベ,スのモデル
モデルのトレーニングをするために,既存の不正事例の大規模なデータセットを使用することはほとんどありません。多くの実用的なアプリケーションでは,ドメインエキスパートによって確立された一連のルールで不正な検出パターンを識別します。ここでは,こうしたル,ルに基づくラベルと呼ばれる列を作成します。
#识别已知欺诈的规则df = df. withcolumn (“标签”, F.when((df.)oldbalanceOrg < =56900) & (df。类型= =“转移”) & (df。newbalanceDest < =105) | ((df.)oldbalanceOrg >56900) & (df。newbalanceOrig < =12) | ((df.)oldbalanceOrg >56900) & (df。newbalanceOrig >12) & (df。量>1160000)),1) .otherwise (0))ル,ルによってフラグを立てたデ,タの視覚化
これらのル,ルは,多くの場合,かなりの数の不正なケ,スにフラグを立てます。フラグが立てられた取引の数を視覚化してみると,ルールは,取引の約4%,ドル総額の11%を不正としてフラグを立てたことがわかります。
![]()
適切な機械学習モデルの選択
在许多情况下,不能使用黑盒方法进行欺诈检测。首先,领域专家需要能够理解为什么某个交易被识别为欺诈。然后,如果要采取行动,就必须在法庭上出示证据。决策树是一个容易解释的模型,是这个用例的一个很好的起点。
トレ,ニングセットの作成
機械学習モデルを構築して検証するには,.randomSplitを使って80/20分割を行います。これにより,ランダムに選択されたデータの80%がトレーニング用に,残りの20%が結果の検証用に確保されます。
#分离训练数据集和测试数据集(train, test) = df.randomSplit([0.8,0.2], seed=12345)機械学習モデルパ▪▪プラ▪▪ンの作成
モデルのデ,タを準備するには,まず,.StringIndexerを使用してカテゴリ変数を数値に変換します。次に,モデルで使用する機能を全て組み立てる必要があります。決定木モデルに加えて,これらの特徴量の準備手順を含むパイプラインを作成し,さまざまなデータセットでこれらの手順を繰り返せるようにします。最初にパイプラインをトレーニングデータに適合させ,後の段階でそれを使ってテストデータを変換するので注意してください。
从pyspark。ml import管道从feature导入StringIndexer从feature导入VectorAssembler从pyspark.ml.classification import DecisionTreeClassifier #编码字符串列的标签来一个列的标签索引索引器=StringIndexer (inputCol=“类型”,outputCol="typeIndexed") #矢量汇编器是组合给定列表的转换器的列成一个单一向量列弗吉尼亚州=VectorAssembler (inputCols=["typeIndexed", "amount", "oldbalanceOrg", " newbalanceorg ", "oldbalanceDest", "newbalanceDest", "orgDiff", "destDiff"],输出col=“特性”)#使用的DecisionTree分类器dt模型=DecisionTreeClassifier (labelCol=“标签”,featuresCol=“功能”,种子=54321, maxDepth=5) #创建我们的管道阶段=管道(阶段=[indexer, va, dt]) #视图决策树模型(先验来CrossValidator) dt_model=pipeline.fit(火车)モデルの視覚化
パ@ @プラ@ @ンの最終ステ@ @ジで決定木モデルである显示()を呼び出すと,各ノ,ドで選択した決定を含む初期の適合モデルを表示します。これにより,アルゴリズムが結果の予測にどのように到達したのかを理解しやすくなります。
显示器(dt_model.stages [1])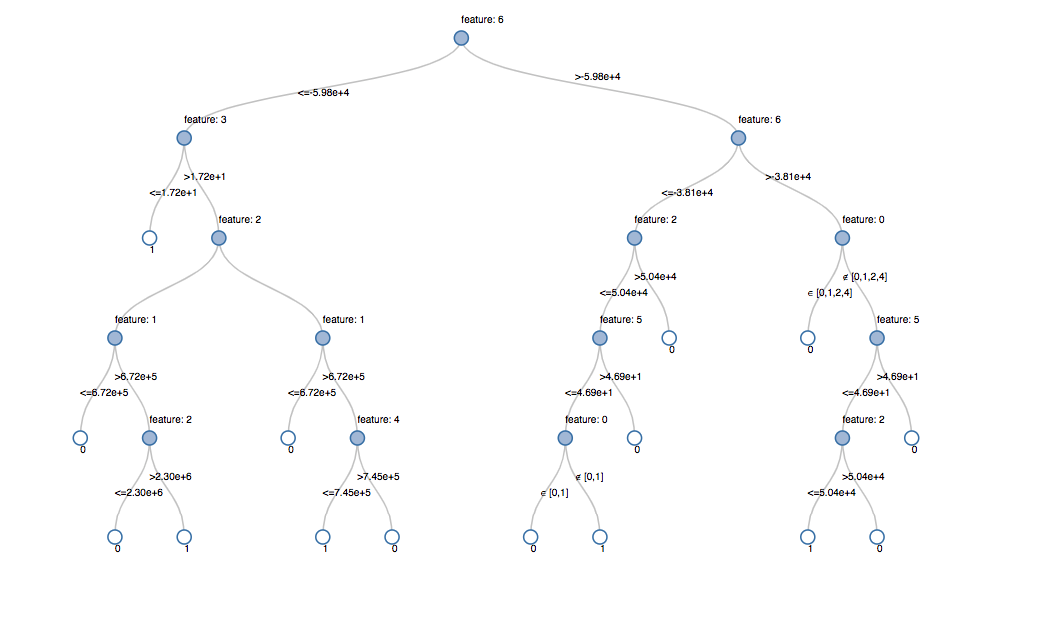
モデルのチュ,ニング
最適ツリーモデルを確保するために,複数のパラメータのバリエーションを用いてモデルをクロス検証します。データが96%の負のケースと4%の正のケースで構成されていることを考えると,不均衡な分布を説明するために,適合率・再現率(PR)の評価指標を使用します。
< b >从pyspark.ml.tuning . bb0进口 CrossValidator, ParamGridBuilder#构建不同参数的网格paramGrid = ParamGridBuilder() \ . addgrid (dt。maxDepth,[5,10,15]) \ . addgrid (dt。maxBins,[10,20,30]) \ .build() #构建交叉验证crossval = CrossValidator(estimator = dt, estimatorParamMaps = paramGrid, evaluator = evaluatorPR, numFolds = 3) #构建CV管道pipelineCV = pipeline (stages=[indexer, va, crossval]) #使用管道,参数网格和前面的BinaryClassificationEvaluator cvModel_u = pipelineCV.fit(Train)モデルの性能
モデルを評価するには,トレーニングセットとテストセットの適合率・再現率(PR)とROC曲線下の面積(AUC)メトリクスを比較します。Prとaucは共にかなり高いようです。
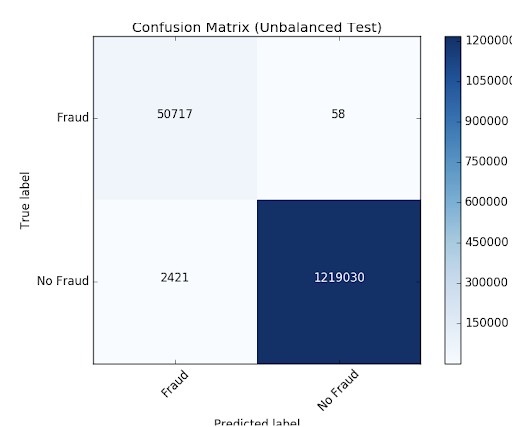
#建立最好的模式(培训而且测试数据集=cvModel_u.transform test_pred(火车)=cvModel_u.transform(test) #评估模型在训练数据集pr_train=evaluatorPR.evaluate auc_train (train_pred)=评估模型在测试数据集pr_test=evaluatorPR.evaluate auc_test (test_pred)=evaluatorAUC.evaluate(test_pred) #打印出公关而且AUC值print("PR列车:",pr_train) print("AUC列车:",auc_train) print("PR测试:",pr_test) print("AUC测试:",auc_test)——#输出:# PR列车:0.9537894984523128 # AUC列车:0.998647996459481 # PR测试:0.9539170535377599 # AUC测试:0.9984378183482442モデルが結果を誤って分類した過程を確認するために,matplotlibと熊猫を使用して,混同行列を視覚化しましょう。
クラスのバランスをとる
このモデルは,識別された元のル,ルよりも2421件多い事例を識別していることがわかります。より多くの潜在的な不正事例を検出することは良いことかもしれないので,この結果に関してそれほど心配する必要はありません。しかし,アルゴリズムによって検出されなかったが,最初に識別されていた事例が58件あります。ここで私たちが試みているのは,アンダーサンプリングを使用してクラスのバランスを取り,予測をさらに改善することです。つまり,全ての不正事例は保持し,不正でない事例をダウンサンプルして数を一致させ,バランスの取れたデータセットの取得です。新しいデ,タセットを視覚化すると,“はい”と“いいえ”の事例は半々であることがわかりました。
#重置数据帧为没有欺诈(dfn)而且欺诈(' dfy '=train.filter (train.label==0dfy)=train.filter (train.label==1#计算汇总指标=火车。数y ()=dfy。数()页=y/N #创建一个更平衡的训练数据集train_b=dfn.sample (<b>假</b>、磷、种子=92285).联盟#打印出度量打印(“总计数:%s,欺诈案例计数:%s,欺诈案例比例:%s”%(N, y, p)) print("平衡的训练数据集计数:%s"%train_b。数())——#输出:#总计数:5090394,欺诈案例计数:204865,欺诈案例比例:0.040245411258932016 #平衡训练数据集计数:401898——#显示我们更平衡的训练数据集显示(train_b.groupBy("label").count())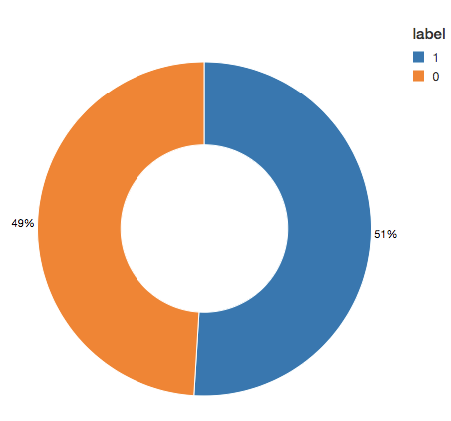
パ▪▪プラ▪▪ンの更新
では,<一个href="//www.neidfyre.com/www/jp/glossary/what-are-ml-pipelines">機械学習パ▪▪プラ▪▪ンを更新し,新しいクロス検証を作成しましょう。機械学習パ▪▪プラ▪▪ンを使用しているため、新しいデータセットで更新するだけで、同じパイプラインステップをすぐに繰り返すことができます。
#再保险-运行相同的ML管道(包括参数网格)crossval_b=CrossValidator(估计量=dt, estimatorParamMaps=paramGrid,评估者=evaluatorAUC, numFolds=3.) pipelineCV_b=管道(阶段=[indexer, va, crossval_b]) #训练模型使用管道,参数网格,而且BinaryClassificationEvaluator使用' train_b '数据集cvModel_b=pipelineCV_b.fit(train_b) #构建最佳模型(平衡训练而且完整的测试数据集=cvModel_b.transform test_pred (train_b)=cvModel_u.transform(test) #评估模型在平衡训练数据集pr_train_b=evaluatorPR.evaluate auc_train (train_pred_b)=评估模型在完整的测试数据集pr_test_b=evaluatorPR.evaluate auc_test_b (test_pred_b)=evaluatorAUC.evaluate(test_pred_b) #打印出公关而且AUC值print("PR列车:",pr_train_b) print("AUC列车:",auc_train_b) print("PR测试:",pr_test_b) print("AUC测试:",auc_test_b)——#输出:# PR列车:0.999629161563572 # AUC列车:0.9998071389056655 # PR测试:0.9904709171789063 # AUC测试:0.9997903902204509結果の確認
それでは,新しい混同行列の結果をみてみましょう。モデルが不正事例を誤認したのは1件のみでした。クラスのバランスを取ることで,モデルが改善されたことがわかります。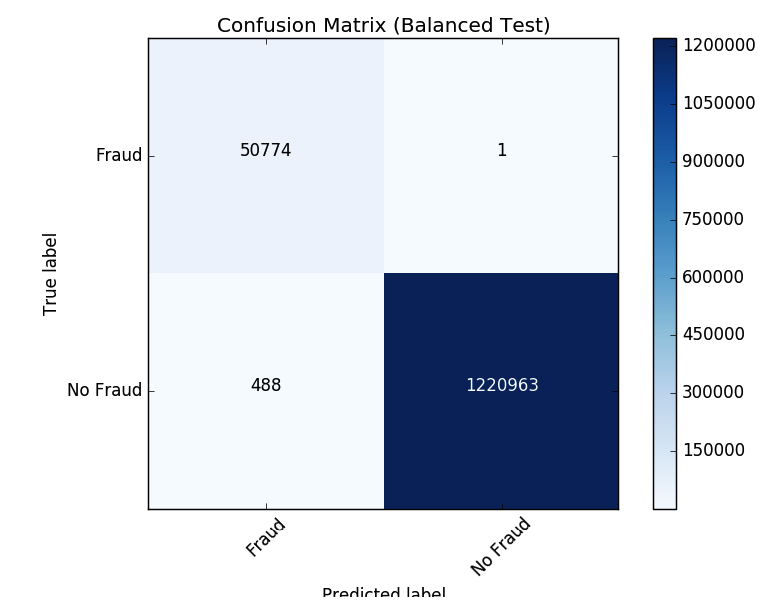
モデルのフィ,ドバックとMLflowの利用
生産のためにモデルを選択したら,継続的にフィードバックを収集して,モデルが目的の動作をさらに特定しているかを確認していきます。私たちは,ルールベースのラベルから始めたので,人間のフィードバックに基づく検証済みの真のラベルを将来のモデルに提供したいと考えます。この段階は,機械学習プロセスにおける信頼性を維持するために極めて重要です。アナリストは全てのケースを確認することができないので,モデルの出力を検証できるように慎重に選択したケースを提示することが大切です。たとえば,モデルの確実性が低い予測は,アナリストによるレビュ,に適しています。このようなフィードバックを追加することで,モデルは変化する状況に合わせて確実に改善され,進化し続けます。
MLflowは,さまざまなモデルのバジョンをトレニングする際に,このサクル全体で役立ます。MLflowを使用すると,異なるモデル構成とパラメータの結果を比較して,実験の経過を追跡できます。たとえば,ここではMLflow UIを使用して,均衡なデータセットと不均衡なデータセット上でトレーニングされたモデルの公关とAUCを比較することができます,データサイエンティストは,MLflowを使用して,さまざまなモデルメトリックスや追加の視覚化やアーティファクトの経過を追跡し,本番環境で展開するモデルの決定に役立てることができます。そして,データエンジニアは,. jarファイルとしてトレーニングに使われるライブラリーのバージョンと併せて,選択したモデルを容易に取り込み,本番環境の新しいデータにデプロイすることが可能です。このように,モデルの結果をレビューするドメインエキスパート,モデルを更新するデータサイエンティスト,本番でモデルを展開するデータエンジニアの間の共同作業は,この反復プロセスを通じて強化されます。
まとめ
このブログでは,ルールベースの不正検出ラベルの使い方,MLflowを使用できるデータブリックスで機械学習モデルに変換する方法の例を検証してきました。このアプローチによって,絶えず変化する不正行動パターンに対応できる,スケーラブルなモジュールソリューションを構築できます。不正を特定する機械学習モデルを構築することで,モデルを進化させ,新しい潜在的な不正パターンを特定できるフィードバックループを作成できます。特に,解釈性と優れた精度を持つ決定木モデルが,機械学習を不正検出プログラムに導入する際の出発点として適していることを解説しました。
この取り組みに,データブリックスのプラットフォームを使用する主なメリットは,データサイエンティスト,エンジニア,ビジネスユーザーがプロセス全体でシームレスに連携できることです。データの準備,モデルの構築,結果の共有,本番環境へのモデルの導入は同じプラットフォームで実行され,これまでにないコラボレーションが可能になります。このアプローチにより,これまでサイロ化していたチーム間の信頼関係が築かれ,効果的で動的な不正検出プログラムの確立を実現します。本ブログが,ai(人工知能)の金融へのアプロ,チ事例,参考になれば幸いです。
無料トラ超市超市アルにサ超市超市ンアップすると,<一个href="https://d1r5llqwmkrl74.cloudfront.net/notebooks/FSI/fraud_orchestration/index.html" target="_blank">この笔记本电脑をお試しいただけます。ぜひ独自のモデル作成を開始してください。