
特性深入研究:Apache Spark结构化流中的水印

关键的外卖
- 水印帮助Spark了解基于事件时间的处理进度,何时生成带窗口的聚合以及何时修剪聚合状态
- 在连接数据流时,Spark默认使用一个全局水印,该水印根据在输入流中看到的最小事件时间来清除状态
- 可以利用RocksDB来减少集群内存和GC暂停的压力
- StreamingQueryProgress而且StateOperatorProgress对象包含关于水印如何影响流的关键信息
简介
在构建实时管道时,团队必须面对的现实之一是分布式数据摄取本质上是无序的。此外,在有状态的上下文中流媒体对于操作,团队需要能够正确地跟踪他们正在摄取的数据流中的事件时间进度,以便正确地计算时间窗口聚合和其他有状态操作。我们可以使用结构化流来解决所有这些问题。
例如,假设我们是一个团队,正在构建一个管道,以帮助我们的公司对租赁给客户的矿机进行主动维护。这些机器总是需要在最佳状态下运行,以便我们实时监控它们。我们需要对流数据执行有状态聚合,以理解和识别机器中的问题。
这就是我们需要利用结构化流和水印来产生必要的有状态聚合的地方,这将有助于为这些机器的预测性维护和更多决策提供信息。
什么是水印?
一般来说,在处理实时流数据时,由于数据的摄取方式以及整个应用程序是否遇到停机等问题,事件时间和处理时间之间会有延迟。由于这些潜在的可变延迟,用于处理此数据的引擎需要某种机制来决定何时关闭聚合窗口并产生聚合结果。
虽然补救这些问题的自然倾向可能是使用基于挂钟时间的固定延迟,但我们将在接下来的示例中说明为什么这不是最佳解决方案。
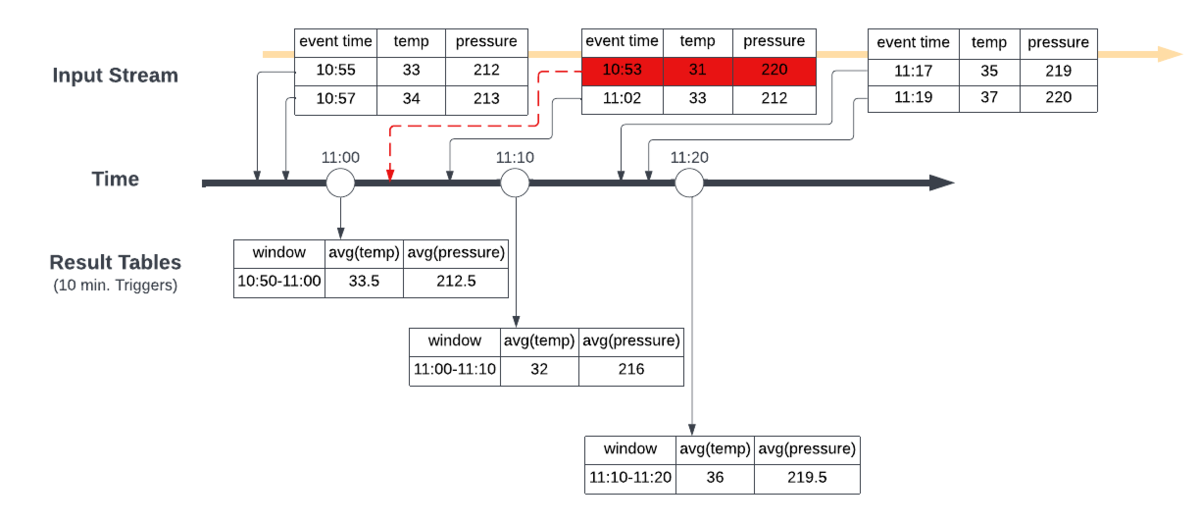
为了直观地解释这一点,让我们以一个场景为例,我们在大约上午10:50→上午11:20的不同时间接收数据。我们正在创建10分钟的滚动窗口,计算在窗口期间获得的温度和压力读数的平均值。
在第一张图中,我们在上午11点、11点10分和11点20分触发滚动窗口,导致结果表在各自的时间显示。当第二批数据在上午11:10左右到达时,其中的事件时间为上午10:53,这将被纳入为上午11:10关闭的11:00→11:10窗口计算的温度和压力平均值,这不会给出正确的结果。
为确保获得想要生成的聚合的正确结果,我们需要定义水印这将允许Spark了解何时关闭聚合窗口并产生正确的聚合结果。
在结构化流应用程序中,我们可以确保通过使用名为水印。在最基本的意义上,通过定义水印Spark结构化流知道它什么时候摄取了所有数据,T,(基于设置的延迟期望),以便它可以关闭并产生到时间戳的窗口聚合T.
第二张图显示了实现10分钟水印并在Spark Structured Streaming中使用追加模式的效果。
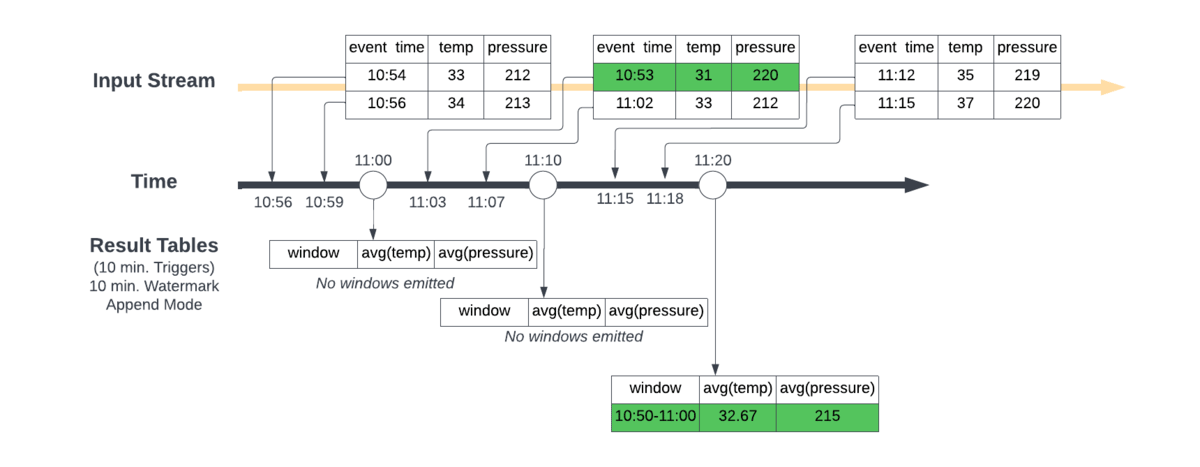
与第一个场景不同的是,Spark将每十分钟发出前十分钟的窗口聚合(即在11:10 AM发出11:00 AM→11:10 AM窗口),Spark现在等待关闭并输出一次窗口聚合最大事件可见时间减去指定水印大于窗口的上限。
换句话说,Spark需要等待,直到它看到最近看到的事件时间减去10分钟大于11:00 AM的数据点,才能发出10:50 AM→11:00 AM聚合窗口。在上午11:00,它看不到这个,所以它只在Spark的内部状态存储中初始化聚合计算。在11:10 AM,这个条件仍然没有满足,但是我们有了一个新的10:53 AM的数据点,所以内部状态得到更新没有发出。最后在11:20 AM Spark已经看到了一个事件时间为11:15 AM的数据点,由于11:15 AM减去10分钟是11:05 AM,比11:00 AM晚,所以10:50 AM→11:00 AM窗口可以被发射到结果表中。
这将根据水印定义的预期延迟时间正确地合并数据,从而产生正确的结果。一旦发出结果,相应的状态将从状态存储中删除。
在管道中加入水印
为了理解如何将这些水印合并到结构化流管道中,我们将通过一个实际的代码示例来探索这个场景,该示例基于本文介绍部分中所述的用例。
假设我们正在从云端的Kafka集群中获取所有传感器数据,并且我们希望每10分钟计算一次温度和压力平均值,预期时间偏差为10分钟。带有水印的结构化流管道看起来是这样的:
PySpark
sensorStreamDF=火花\.readStream \.format \(“卡夫卡”).option(“kafka.bootstrap。“host1:port1,host2:port2”)\.option("subscribe", "tempAndPressureReadings") \.load ()sensorStreamDF=sensorStreamDF \.withWatermark("eventTimestamp", "10分钟")\.groupBy (窗口(sensorStreamDF。eventTimestamp, "10分钟"))\.avg(sensorStreamDF.temperaturesensorStreamDF.pressure)
sensorStreamDF.writeStream.format(“δ”).outputMode(“追加”).option(“checkpointLocation”、“/δ/事件/ _checkpoints / temp_pressure_job /”).开始(“/δ/ temperatureAndPressureAverages”)在这里,我们简单地从Kafka读取数据,应用我们的转换和聚合,然后写入Delta Lake表,这些表将在Databricks SQL中可视化和监控。对于特定的数据样本,写入表的输出如下所示:

为了整合水印,我们首先需要识别两个项:
- 表示传感器读数的事件时间的列
- 数据的估计预期时间偏差
从前面的示例中,我们可以看到由.withWatermark ()方法,使用eventTimestamp列作为事件时间列,10分钟表示我们期望的时间偏差。
PySpark
sensorStreamDF=sensorStreamDF \.withWatermark("eventTimestamp", "10分钟")\.groupBy (窗口(sensorStreamDF。eventTimestamp, "10分钟"))\.avg(sensorStreamDF.temperaturesensorStreamDF.pressure)既然我们知道了如何在结构化流管道中实现水印,那么了解其他项目(如流连接操作和管理状态)如何受到水印的影响将非常重要。此外,当我们扩展我们的管道时,我们的数据工程师将需要了解和监控一些关键指标,以避免性能问题。在深入研究水印时,我们将对所有这些进行探讨。
不同输出模式下的水印
在深入研究之前,了解您选择的输出模式如何影响所设置的水印的行为是很重要的。
水印只能在运行流媒体应用程序时使用附加或更新输出模式。还有第三种输出模式,即完全模式,在这种模式下,整个结果表都被写到存储中。不能使用这种模式,因为它要求保存所有聚合数据,因此不能使用水印来删除中间状态。
这些输出模式在窗口聚合和水印上下文中的含义是,在“追加”模式下,聚合只能生成一次,不能更新。因此,一旦生成了聚合,引擎就可以删除聚合的状态,从而保持整体聚合状态有界。后期记录——近似水印启发式不适用的记录(它们比水印延迟周期更老),因此必须删除——已经生成了聚合,并且删除了聚合状态。
相反,对于“更新”模式,可以从第一个记录开始,在每个接收到的记录上重复生成聚合,因此水印是可选的。水印只在启发式引擎知道不能接收该聚合的更多记录时才用于修饰状态。一旦状态被删除,所有迟来的记录都必须被删除,因为聚合值已经丢失并且不能更新。
了解状态、延迟到达记录和不同的输出模式如何导致在Spark上运行的应用程序的不同行为是很重要的。这里的主要收获是,在追加和更新模式中,一旦水印表示接收了聚合时间窗口的所有数据,引擎就可以修剪窗口状态。在附加模式下,聚合只在关闭时间窗口加上水印延迟时产生,而在更新模式下,它在每次更新窗口时产生。
最后,通过增加水印延迟窗口,您将导致管道等待数据的时间更长,并可能丢失更少的数据——更高的精度,但也会产生更高的聚合延迟。另一方面,较小的水印延迟会导致较低的精度,但也会降低产生聚合的延迟。
| 窗口延迟长度 | 精度 | 延迟 |
|---|---|---|
| 更长的延迟窗口 | 更高的精度 | 更高的延迟 |
| 更短的延迟窗口 | 低精度 | 更低的延迟 |
深入研究水印
连接和水印
在流应用程序中执行连接操作时,特别是在连接两个流时,有几个注意事项需要注意。假设对于我们的用例,我们希望将关于温度和压力读数的流式数据集与机器上其他传感器捕获的附加值连接起来。
在结构化流中可以实现三种主要类型的流-流连接:内部连接、外部连接和半连接。在流应用程序中进行连接的主要问题是,您可能对连接的一侧没有完整的了解。让Spark了解什么时候没有预期的未来匹配,这类似于前面关于聚合的问题,在发出聚合之前,Spark需要了解什么时候没有新的行可以合并到聚合的计算中。
为了允许Spark处理这个问题,我们可以在流-流连接的连接条件中利用水印和事件时间约束的组合。这种组合允许Spark过滤掉后期记录,并通过连接上的时间范围条件来修整连接操作的状态。我们在下面的例子中演示这一点:
PySpark
sensorStreamDF=spark.readStream.format(“δ”)。表格(“sensorData”)tempAndPressStreamDF=spark.readStream.format(“δ”)。表格(“tempPressData”)sensorStreamDF_wtmrk=sensorStreamDF。withWatermark("timestamp", "5分钟")tempAndPressStreamDF_wtmrk=tempAndPressStreamDF。withWatermark("timestamp", "5分钟")joinedDF=tempAndPressStreamDF_wtmrk.alias(“t”)。加入(sensorStreamDF_wtmrk.alias(“s”),expr(“””s.sensor_id == t.sensor_id ANDs.timestamp >= t.timestamp ANDS.timestamp <= t.timestamp + interval 5分钟”“”),joinType=“内心”).withColumn(“sensorMeasure坳(“Sensor1”)+坳(“Sensor2”))\.groupBy (窗口(col("t.timestamp"), "10 minutes")) \.agg (avg(坳(“sensorMeasure”)).alias(“avg_sensor_measure”),avg(坳(“温度”)).alias(“avg_temperature”),avg(坳(“压力”)).alias \(“avg_pressure”)).选择("window", "avg_sensor_measure", "avg_temperature", "avg_pressure")
joinedDF.writeStream.format \(“δ”).outputMode \(“追加”).option("checkpointLocation", "/checkpoint/files/") \.toTable(“output_table”)然而,与上面的例子不同的是,有时每个流的水印可能需要不同的时间倾斜。在这个场景中,Spark有一个处理多个水印定义的策略。火花维护一个全局水印这是基于最慢的流,以确保在不丢失数据时最大程度的安全性。
开发人员确实有能力通过更改来改变这种行为spark.sql.streaming.multipleWatermarkPolicy来马克思;然而,这意味着来自较慢流的数据将被丢弃。
要查看需要或可以利用水印的所有连接操作,请签出本节Spark的文档。
使用水印监视和管理流
当管理一个流查询时,Spark可能需要管理数百万个键并为每个键保存状态,Databricks集群自带的默认状态存储可能不太有效。您可能会开始看到更高的内存利用率,然后出现更长的垃圾收集暂停。这些都将阻碍结构化流应用程序的性能和可伸缩性。
这就是RocksDB的用武之地。你可以在Databricks中通过在Spark配置中启用RocksDB来利用它:
spark.conf。集(“spark.sql.streaming.stateStore.providerClass”,“com.databricks.sql.streaming.state.RocksDBStateStoreProvider”)这将允许运行结构化流应用程序的集群利用RocksDB,它可以更有效地管理本机内存中的状态,并利用本地磁盘/SSD,而不是将所有状态保存在内存中。
除了跟踪内存使用情况和垃圾收集指标外,在处理水印和结构化流时,还应该收集和跟踪其他关键指标和指标。要访问这些指标,您可以查看StreamingQueryProgress和StateOperatorProgress对象。请查看我们的文档以获得如何使用这些工具的示例在这里.
在StreamingQueryProgress对象中,有一个名为“eventTime”的方法,可以调用它并返回马克斯,最小值,avg,水印时间戳。前三个是所看到的最大、最小和平均事件时间在扳机里。最后一个触发器中使用的水印。
StreamingQueryProgress对象的缩写示例
{“id”:“f4311acb - 15 - da - 4 - dc3 - 80 - b2 - acae4a0b6c11”,. . . .“eventTime”: {“平均”:“2021 - 02 - 14 - t10:56:06.000z”,“马克斯”:“2021 - 02 - 14 - t11:01:06.000z”,“最小值”:“2021 - 02 - 14 - t10:51:06.000z”,“水印”:“2021 - 02 - 14 - t10:41:06.000z”},“stateOperators”: [{“operatorName”:“stateStoreSave”,“numRowsTotal”:7,“numRowsUpdated”:0,“allUpdatesTimeMs”:205,“numRowsRemoved”:0,“allRemovalsTimeMs”:233,“commitTimeMs”:15182,“memoryUsedBytes”:91504,“numRowsDroppedByWatermark”:0,“numShufflePartitions”:200,“numStateStoreInstances”:200,“customMetrics”: {“loadedMapCacheHitCount”:4800,“loadedMapCacheMissCount”:0,“stateOnCurrentVersionSizeBytes”:25680}}. . . .}这些信息可用于协调流查询输出的结果表中的数据,也可用于验证所使用的水印是否为预期的eventTime时间戳。当您将数据流连接在一起时,这可能变得非常重要。
在StateOperatorProgress对象中有numRowsDroppedByWatermark指标。这个指标将显示有多少行被认为太晚而不能包含在有状态聚合中。请注意,这个指标是测量删除的行数事后的而不是原始输入行,因此这个数字并不精确,但可以表明有延迟数据被删除。这与来自StreamingQueryProgress对象的信息一起,可以帮助开发人员确定水印是否正确配置。
多重聚合,流和水印
结构化流查询的另一个限制是在单个流查询中链接多个有状态操作符(例如聚合、流连接)。对于有状态聚合,单一全局水印的这种限制是Databricks正在研究的解决方案,并将在未来几个月发布更多信息。查看我们关于光速计划的博客,了解更多信息:BOB低频彩Project Lightspeed:使用Apache Spark更快更简单的流处理(www.neidfyre.com).
结论
使用结构化流和数据水印,组织(如上面描述的用例)可以构建有弹性的实时应用程序,以确保由实时聚合驱动的指标被准确计算,即使数据没有正确排序或准时。要了解BOB低频彩有关如何使用Databricks构建实时应用程序的更多信息,请联系Databricks代表。