

Project Lightspeed:使用Apache Spark进行更快更简单的流处理








通过恋人Ramasamy,马泰Zaharia,雷诺鑫,迈克尔时常要,Awez Syed,雷朱,亚历山大Balikov,杰瑞·彭,Shrikanth Shankar而且Sameer Paranjpye《
2022年6月28日 在工程的博客
流数据是当今计算机的一个关键领域。它是对系统生成的大量传入数据(无论是网络帖子、销售提要还是传感器数据等)做出快速决策的基础。处理流数据在技术上也具有挑战性,它的需求与事件驱动的应用程序和批处理的需求大不相同,而且要满足这些需求更复杂。
为了满足流处理的需要,Apache Spark™2.0中引入了结构化流。结构化流是建立在Spark SQL引擎上的可扩展和容错流处理引擎。用户可以使用SQL或Dataset/DataFrame API来表达逻辑。引擎将负责增量地、连续地运行管道,并在流数据不断到达时更新最终结果。结构化流已经成为几年来的主流,并被1000多个组织广泛采用,仅在Databricks平台上每天就处理超过1pb的数据(压缩)。bob体育客户端下载
随着采用速度的加快以及应用程序迁移到流媒体的多样性的增加,新的需求出现了。我们正在启动一个代号为Project Lightspeed的新项目来满足这些要求,这将把Spark结构化流带到下一代。光速解决的需求分为四个不同的类别:
- 改善延迟并确保其可预测
- 使用新的操作符和api增强数据处理功能
- 改进对连接器的生态系统支持
- 简化部署、操作、监控和故障排除
在这篇博客中,我们将讨论Spark结构化流的发展及其主要好处。然后,我们将概述光速计划中提出的新特性和功能。
Spark结构化流的增长
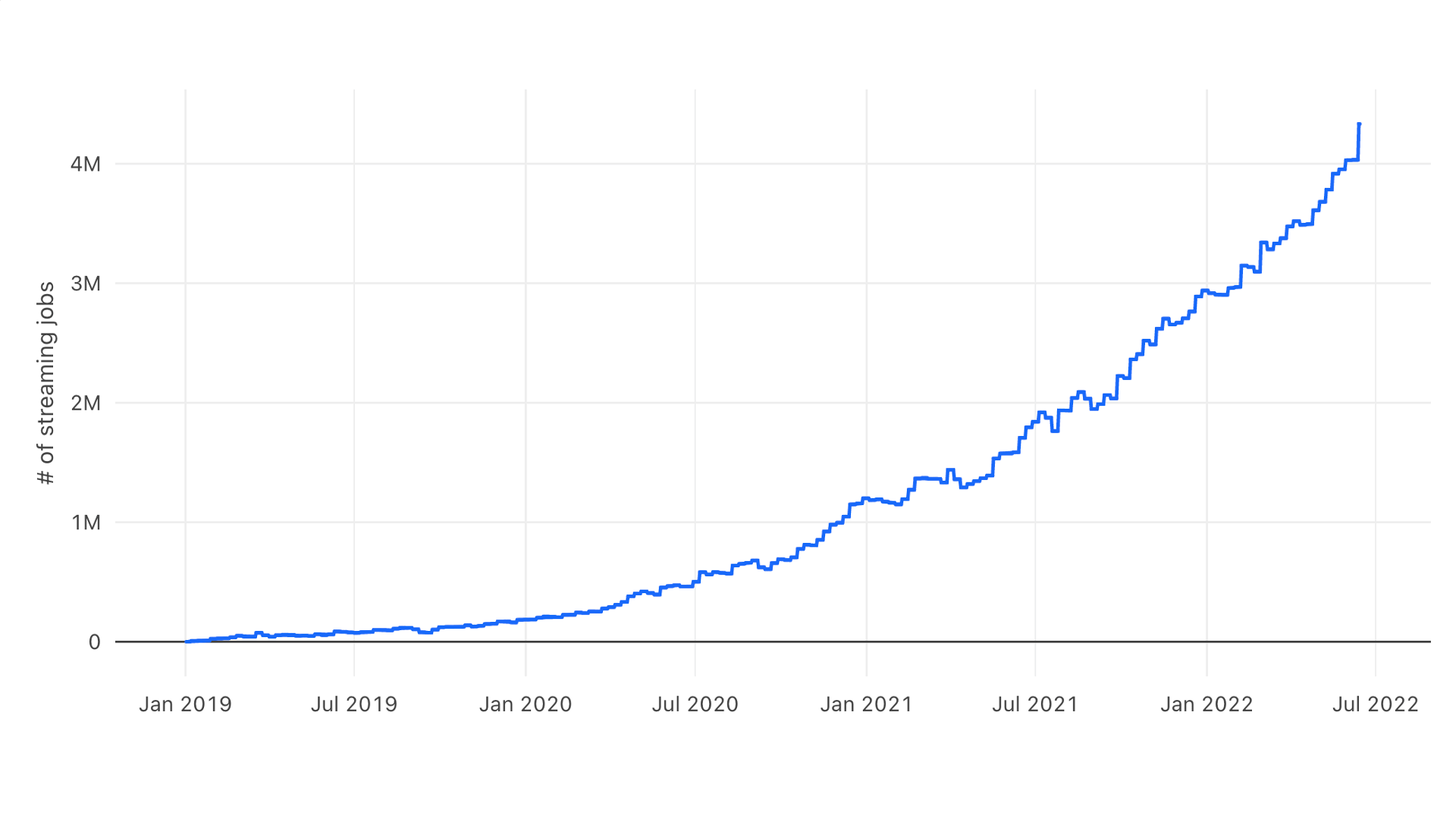
Spark结构化流媒体自从流媒体的早期就被广泛采用,因为它易于使用、性能好、大型生态系统和开发人员社区。我们看到的大多数流工作负载都是客户迁移他们的批处理工作负载,以利用流提供的较低延迟、容错和对增量处理的支持。我们已经看到流媒体客户对开源Spark和Databricks的大量采用。bob下载地址下图显示了过去三年Databricks上每周的流媒体工作数量,从数千增长到400多万,而且还在加速增长。
Spark结构化流的优点
结构化流的几个特性已经使它在今天的数千个流应用程序中流行起来。
- 统一结构化流的最大优势是它使用了与Spark DataFrames中的批处理相同的API,使得从批处理过渡到实时处理变得更加简单。用户可以简单地使用Python、SQL或Spark其他支持的语言编写DataFrame计算,并要求引擎将其作为增量流应用程序运行。然后,当新数据到达时,计算将以增量方式运行,并使用恰好一次的语义自动从故障中恢复,同时运行与批处理计算相同的引擎实现,从而给出一致的结果。这样的共享降低了复杂性,消除了批处理工作负载和流工作负载之间的差异,并降低了操作成本(基础设施的整合是Lakehouse的一个关键优势)。此外,Spark的许多其他内置库都可以在流上下文中调用,包括ML库。
- 容错和恢复-结构化流检查点在处理过程中自动状态。当发生故障时,它自动从以前的状态恢复。故障恢复非常快,因为它仅限于失败的任务,而不是重新启动其他系统中的整个流管道。此外,使用可重放源和幂等接收器的容错功能实现了端到端的恰好一次语义。
- 性能结构化流以较低的成本提供非常高的吞吐量和几秒的延迟,充分利用Spark SQL引擎中的性能优化。系统还可以根据所提供的资源进行自我调整,从而平衡成本、吞吐量和延迟,并支持运行集群的动态扩展。这与需要预先投入资源的系统相反。
- 灵活的操作-使用foreachBatch对流查询的输出应用任意逻辑和操作的能力,使能够执行upserts等操作,写入多个接收器,并与外部数据源交互。超过40%的Databricks用户利用了这个功能。
- 有状态的处理支持有状态聚合和连接,以及用于有界状态和后期订单处理的水印。此外,RocksDB状态存储支持的[flat]mapGroupsWithState的任意状态操作提供了高效和容错的状态管理(从Spark 3.2开始)。
项目光速
随着企业对流媒体的兴趣显著增长,并使Spark结构化流媒体成为各种应用程序的事实上的标准,Project Lightspeed将在改善以下领域进行大量投资:
可预测的低延迟
Apache Spark结构化流在多个维度上提供了平衡的性能——吞吐量、延迟和成本。随着结构化流媒体的发展和在新应用程序中的应用,我们正在分析客户的工作负载,以指导将尾部延迟提高最多2倍。为达到这一目标,我们将采取以下一些措施:
- 抵消管理-我们的客户工作负载分析和性能实验表明,补偿管理操作占用管道30-50%的时间。可以通过使这些操作异步化和可配置的节奏来改进这一点,从而减少延迟。
- 异步的检查点—当前检查点机制处理完一组记录后同步写入对象存储。这在很大程度上导致了延迟。通过将下一组记录的执行与前一组记录的检查点写入重叠,可以提高25%的性能。
- 状态检查点频率- Spark Structured Streaming在一组记录被处理后检查状态,这会增加端到端延迟。相反,如果我们让它每N组检查点可调,延迟可以根据N的选择进一步降低。
增强了处理数据/事件的功能
Spark Structured Streaming已经拥有丰富的功能来表达主要的用例集。随着企业将流扩展到新的用例中,需要额外的功能来简明地表达它们。光速项目在以下方面推进了功能:
- 多状态操作符目前,结构化流只支持每个流作业一个有状态操作符。然而,一些用例在一个作业中需要多个状态操作符,例如:
- 链式时间窗聚合(例如5分钟的翻滚窗聚合,然后是1小时的翻滚窗聚合)
- 链式流-流外部相等连接(例如A左外部连接B左外部连接C)
- 流-流时间间隔连接,然后是时间窗口聚合
- Project Lightspeed将使用一致的语义添加对该功能的支持。
- 先进的窗口- Spark结构化流提供了基本的窗口,解决大多数用例。高级窗口将通过简单、易于使用和直观的API来增强此功能,以支持任意组窗口元素,在窗口上定义通用处理逻辑,描述何时触发处理逻辑以及在应用处理逻辑之前或之后删除窗口元素的能力。
- 状态管理-通过预定义的聚合器和连接提供有状态支持。此外,还提供了专门的api来直接访问和操作状态。Lightspeed中的新功能将随着处理逻辑的变化而结合状态模式的演变,以及从外部查询状态的能力。
- 异步I / O通常,在ETL中,需要与外部数据库和微服务连接流。Project Lightspeed将引入一个新的API,用于管理与外部系统的连接,批量处理请求以提高效率,并异步处理它们。
- Python API校验虽然Python API很流行,但它仍然缺乏有状态处理的原语。Lightspeed将添加一个强大而简单的API来存储和操作状态。此外,Lightspeed将提供与流行的Python数据处理包(如Pandas)更紧密的集成,以方便开发人员。
连接器和生态系统
连接器使Spark结构化流引擎更容易处理数据,并将处理后的数据写入各种消息总线(如Apache Kafka)和存储系统(如Delta lake)。作为光速计划的一部分,我们将在以下方面开展工作:
- 新的连接器-我们将与合作伙伴一起添加新的连接器(例如,bob体育外网下载谷歌Pub/Sub, Amazon DynamoDB),使开发人员能够轻松地使用Spark结构化流引擎和他们喜欢的附加消息总线和存储系统。
- 连接器的增强-我们将启用新的功能,并提高现有连接器的性能。一些例子包括AWS我中的Auth支持Apache卡夫卡连接器和增强的扇出支持亚马逊运动连接器。
操作和故障处理
结构化流作业持续运行,直到显式终止。由于始终在线的性质,有必要使用适当的工具和度量来监视、调试和在超过某些阈值时发出警报。为了实现这些目标,光速计划将改善以下方面:
- 可观察性-目前,从用于监控的结构化流管道生成的指标需要编码来收集和可视化。我们将统一度量收集机制,并提供导出到不同系统和格式的功能。此外,根据客户的输入,我们将为故障排除添加额外的度量标准。
- Debuggability-我们将提供可视化管道的功能,以及如何将其操作符分组并映射到任务和任务正在运行的执行器。此外,我们将实现深入到特定执行者、浏览他们的日志和各种度量的能力。
接下来是什么
在这篇博客中,我们讨论了Spark Structured Streaming的优势,以及它如何促进了它的广泛发展和采用。我们引入了Project Lightspeed,随着越来越多的新用例和工作负载迁移到流媒体,它将Spark结构化流媒体推进到实时时代。
在随后的博客中,我们将从多个维度、增强的功能、操作和生态系统支持等方面详细介绍提高Spark结构化流性能的各个类别。
光速计划将通过与社区密切合作逐步推出。我们预计大部分功能将在明年年初交付。
免费试用Databricks
相关的帖子

如何监控PySpark中的流查询
流是摄取和分析中最重要的数据处理技术之一。它为用户和开发人员提供了低延迟和……

Apache Spark™3.1针对结构化流的新特性
除了提供基于Spark Core和SQL API的流处理能力外,结构化流是最重要的…