
简介
想看而不是读?看看视频在这里.
迈克·奥尔特加:
感谢您今天参加我们的会议,讨论如何利用临床数据分析和云端机器学习来改善医院运营。
Integris Health的数据工程和自动化总监朱利叶斯·阿巴特(Julius Abate)将加入我们,他将领导那里的数据平台,并分享许多很酷的用例。bob体育客户端下载与Julius一起的还有KenSci的联合创始人兼首席技术官Ankur Teredesai和Databricks的医疗保健和生命科学技术总监Frank Nothaft,他们分享了与Julius这样的客户在如何实施这些解决方案方面的实际经验。
接下来我要把它交给今天的第一位演讲者,Frank Nothaft。
使用Databricks个性化患者体验并改进操作
Frank Nothaft:
嗨,所有。很高兴今天能和大家聊天。我是Frank Nothaft,正如Micheal提到的,我是Databricks在医疗保健和生命科学领域的技术总监,我负责我们的全球医疗保健和生命科学业务。首先,对于那些不熟悉该公司的人来说,Databricks是一个云平台,它提供了一个统一的数据分析平台,允许团队在数据工程、数据科学和商业分析方面进行协作。bob体育客户端下载我们的团队于2013年由Apache Spark软件项目的最初创建者在UC Berkeley AMPLab共同创立。在Apache Spark项目开源之后,我们的团队决定构建一个平台,使公bob下载地址司能够更容易地利用Apache Spark的高性能、易于使用、低成本和安全的云平台。bob体育客户端下载自2013年以来,我们已经成长起来,现在我们有超过5000个客户和450个合作伙伴正在使用这个平台,我们已经做了很多工作来构建一个更好的开bob体育外网下载源生态系统来使用Apache Spark。bob下载地址bob体育客户端下载

我们仍然贡献了开源Apache Spark项目中75%的代码。bob下载地址我们最近增加了Delta Lake项目,该项目增加了一个高性能云原生数据湖。这是一种用于存储数据的bob下载地址开源格式,可以在云和其他本地存储系统上提供acid一致性。然后我们添加了MLflow项目,这是一个开源项目,通过跟踪和构建钩子快bob下载地址速地将模型投入生产,为人们提供了一种简单的方法来管理他们的机器学习生命周期。
随着我们公司的成长,我们看到的一件大事是一个很好的机会,我们可以扩展到专业行业,并进一步帮助客户更积极、更成功,并从他们对软件的投资中更快地看到成功。早在2017年,我们开始去建立我们的卫生保健和生命科学垂直,挂着一个大大的关注让这些团队正在非常在医疗领域特定问题,在生命科学领域,可以站起来这些问题,把这些高性能机器学习和数据工程能力的领域科学家之手,这样他们真的可以给人带来的数据业务,对病人护理或治疗方法的发展产生影响。我们的业务增长非常迅速。我们与十大制药公司中的七家合作。我们与多家财富10强医疗保健公司合作。我们在护理提供者领域有大量的实践,我们将深入研究所有这些组织都看到的一些用例。

当我们审视医疗保健的现状时,我们正处于一个令人着迷的时代,一个巨大的转变正在发生。我们看看这个行业的整合,如果你进入一个历史上有很多小型社区医院,有几家大型公立医院的大都市地区,你现在经常会看到许多医院合并成区域连锁,在一个地区可能会有三家主要的连锁医院。与此同时,我们在数据收集方面出现了很多趋势,现在病人有前所未有的机会获得关于他们的护理信息,关于他们病情的信息,我们看到很多提供者建立了数字界面,病人可以进入,改变他们的预约,直接通过应用程序与他们的医生交谈。这为我们提供了大量的数据,为患者提供了更多的选择,使我们能够继续前进,塑造他们的体验。
最后,当我们放眼整个行业时,我们有一个重大的变化,过去我们在服务中得到了补偿,我们做了什么,我们根据我们为病人提供的服务得到了补偿,我们现在改变了一种模式,我们将根据病人所经历的价值和结果获得补偿。我们看到的是,这对我们来说是一个很好的机会,可以继续使用我们正在收集的大规模数据集,无论是通过我们的电子病历,还是通过我们的数字外展系统,为我们的病人提供个性化的护理,改善我们的病人得到的结果。
如果我们不继续这样做,实际上我们面临着非常大的风险。如果与我们竞争的其他护理系统在使用这些信息来个性化护理和改善结果方面做得更好,我们很可能会失去我们的病人。即使是现在,每年也有20%的患者因为对目前的医疗服务提供者不满而转行。
然而,当我们看看需要什么才能继续下去,将这些大数据转化为临床实践的实际变化,在我们如何继续下去,如何招募病人,如何管理病人护理体验方面,有很多地方我们需要技术来继续前进,为我们挺身而出,但很难让人们继续前进并做到这一点。首先,我们看到的是规模是一个非常大的问题。如果我们要建立一个在病人层面上个性化护理的系统,我们需要能够将我们所有的数据资产聚集在一起,以构建每个病人的单一视图,我们需要将其扩展到系统中的所有病人。这意味着我们必须能够接收来自病床的电子病历数据、账单数据、图像、物联网数据,我们必须将这些数据统一在一起。这可能是数百tb,最高可达pb级的数据,目前大多数护理系统都没有能力处理这些数据。他们可能有一个可以支撑的数据仓库,但他们没有一个伟大的大数据平台,可以把所有这些数据集成在一起。bob体育客户端下载
当我们研究机器学习领域时,可重复性是一个大问题。如果我们看一个模型,如果我要使用机器学习并将其整合到临床实践中,我知道我的医生会想要了解这个模型是如何构建的。这是一个我可以信任的模型吗?我们知道有些病人会对我们提出同样的要求,如果监管机构介入,他们会对模型是如何建立的,它们是在什么基础上训练的,以及我们如何确保它们有效提出强烈的问题。很多时候,人们没有一个很好的策略来确保他们所做的机器学习是可重复的,这最终成为一个非常强大的大门,阻止他们在整个护理生态系统中推广机器学习。
最后,安全和隐私是一个真正的大障碍。当我们考虑将数据转移到云端时,当我们听到医疗组织内部的首席信息官们说,他们的很多担忧都是立即确保他们能够满足合规要求,以便他们的利益相关者信任他们管理数据的方式,并信任使用云计算来做出这些数据驱动的决策。
Databricks平台作为云原生服务解决bob体育客户端下载了这一问题,最终消除了许多障碍。首先,如果我们考虑成本效益的规模,我们在Spark生态系统和Delta Lake文件格式中做了大量工作,以便非常容易地加载许多不同的数据类型并大规模地处理它们。例如,如果我们看看我们做过的一些项目,其中一个非常令人兴奋的项目是我们在Regeneron制药组织做的,就是从他们合作的医院系统中获取临床数据。它从患者身上获取基因组数据,并对其进行测序,然后将这些数据整合在一起,以超过100万名患者的规模。他们可以把所有的数据都存储在德尔塔湖。他们能够让这些表格广泛地被人们使用。他们能够在上面进行计算,他们实际上已经能够完成需要三个月才能完成的计算工作,并将其加速到两天。这最终使他们能够建立一个非常大的,全面的患者视图,涵盖他们感兴趣的所有临床表型,所有这些不同的正交数据资产,他们可以很好地了解遗传疾病是如何发展和表现的。
当我们考虑可重复性时,我们的机器学习库管理工具MLflow是一个开源工具,它允许你继续跟踪完整的保管链,所有的数据,所有进入机器学习模型的谱系,这样你就可以了解进入其中的一切。bob下载地址您可以以可复制的方式锁定该模型,并继续广泛地共享它。当我们看到像Optum这样的组织时,他们已经能够继续使用它来将机器学习扩展到由80个不同的数据科学家组成的大型数据科学团队,他们正在努力做一些事情,比如预测会导致疾病的条件,这样他们就可以在个性化护理方面做得更好,并提出预防性护理途径。
最后,当我们审视我们在云中运行的方式时,我们花了大量的时间和精力来确保我们的云服务非常安全,它符合HIPAA和Azure等法规,我们高度信任CSF认证。我们在产品和平台中都有深入的支持,允许您在产品功能的每一层定义访问控制。bob体育客户端下载这使您可以确信,您可以继续在大量PHI上部署此系统,同时满足您的内部遵从性需求,并能够在非常细的粒度上保护数据资产。
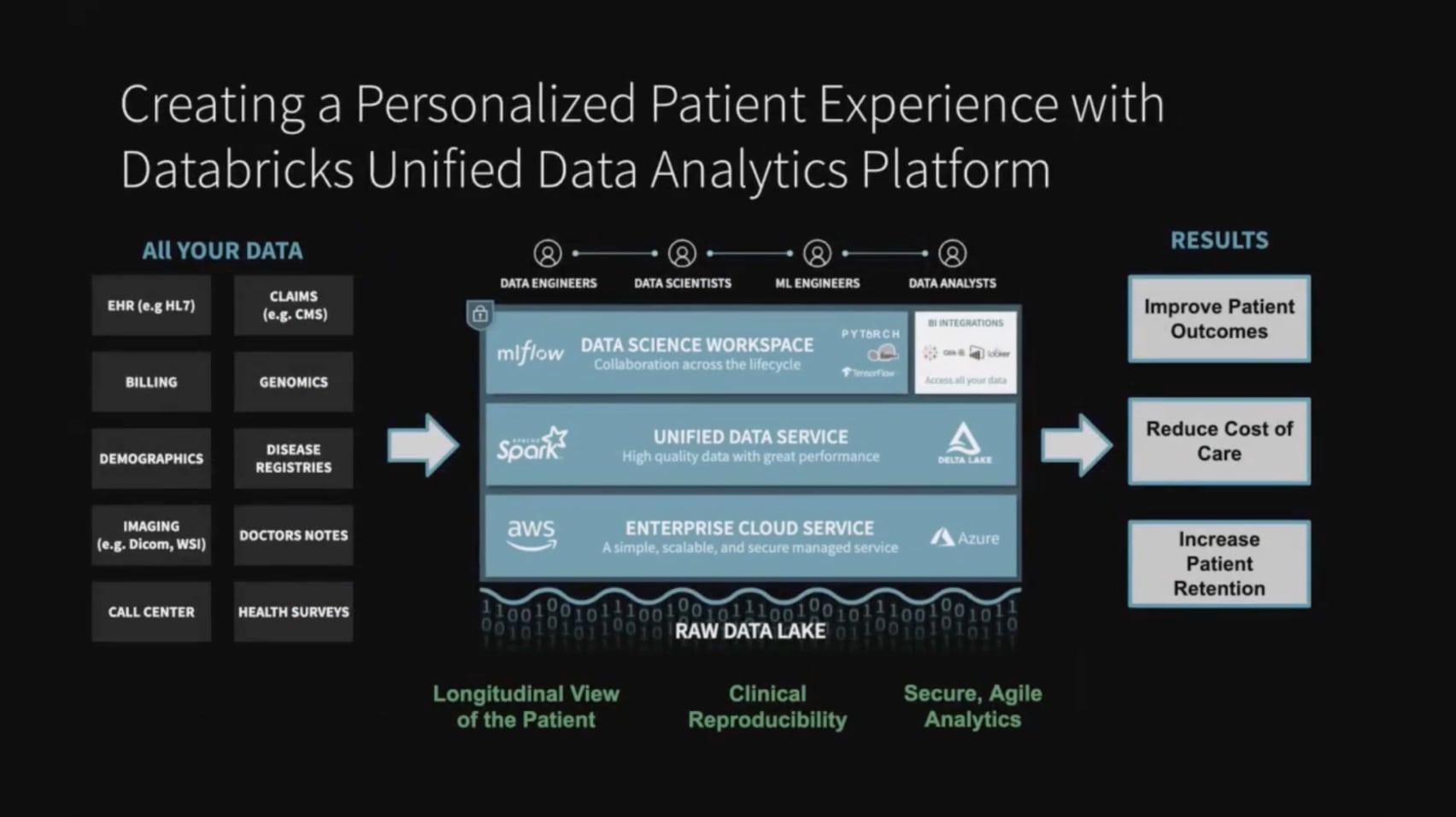
最终当这些结合在一起时,这就是你可以思考的方式。你所有的数据都将保存在云存储中。我们直接部署到您的云中,因此我们的企业云服务在您的帐户中运行。当你在计算时,它会自动增加或减少计算资源。它让你很容易通过UI来启动计算集群这样你的数据科学家,你的数据分析师就不需要学习如何进入云控制台来启动计算集群。这是一种非常容易使用的形式。我们的统一数据服务是Apache Spark的优化版本,加上托管的Delta Lake服务,通过将扩展计算与高效的缓存和云IO层集成在一起,提供了非常高的性能。然后我们有一个数据科学工作空间,它提供了一个受管理的笔记本电脑,所以它就像Jupyter笔记本电脑,在云端运行,具有高度的访问控制和深度协作。我们有内置的版本控制和共享笔记本的能力,因此您可以轻松地在团队之间共享笔记本,并了解人们如何前进并将他们的分析放在一起。最终,这可以让你非常快速地推进分析项目,最终改善患者的结果,降低护理成本,提高患者的保留率。
最终有了这个平台,我们有很多能力可以让你个bob体育客户端下载性化病人的体验,我们看到客户在人口健康方面使用这个平台来了解影响他们护理的社会因素和疾病合并症。我们看到很多人将它用于基因组学的高级工作流,医学成像的高级工作流和医疗物联网的高级工作流。然后我们在病人参与领域看到了很多工作,为我们如何运营医院的运营方面建立了更好的模型,可以改善或最终导致病人体验的改变。有了这些,我们将继续,转向KenSci团队。KenSci有一个非常棒的平台,在人口健康和护理管理bob体育客户端下载领域提供了很多工作,所以我将继续把它交给Ankur Teredesai, KenSci的首席技术官,他将带你们了解KenSci产品,并帮助你们理解它如何适合你们的战略。
KenSci整合医疗保健数据,支持跨数据团队协作

Ankur Teredesai:
谢谢你,Frank,感谢你对Databricks的精彩介绍,感谢你为众多客户提供了精简的价值主张,并带来了巨大的价值。从KenSci的角度来看,KenSci是一个智能预测系统。我们处在记录系统和参与系统之间。KenSci带给Julius和Integris以及美国和全球许多客户的主要价值是,医疗保健是如此微妙。它受到高度监管,要创建一个机器学习驱动的洞察交付平台,就需要许多专门针对医疗保健的组件。bob体育客户端下载我们的旅程始于2015年。我们是从华盛顿大学分离出来的,我在那里花了十多年的时间,对半径的人工智能模型进行基础研究,以获得更广泛和更好的用例,并将所有这些模型放在云端,我们于2015年创建了KenSci。今天,KenSci在几乎四大洲开展工作,美国大多数大型医疗保健机构都是KenSci的客户。
KenSci通过在护理管理、运营效率、成本和利用率预测模型方面拥有人工智能驱动的智能系统,实现了一个积极的参与和交互系统。
KenSci和Databricks共同推动的主要价值是,KenSci作为一个加速器,让您从Databricks作为一个平台获得价值,跨越三个主要枢纽,帮助您轻松地消化、实验、培训和在云上协作。bob体育客户端下载因此KenSci为大多数领先的emr提供预构建的数据连接器。我们帮助摄取索赔和Rx规范数据,供应链数据。我们创造了医疗数据是一种常见的数据目录中,这样,当你连接到数据的来源,开始将为未来的建设和机器学习,数据转换过程进行了简化,这样所有的操作细节和触发器需要看出去,异常处理,数据质量,都是照顾KenSci平台与砖坐在云的顶部。bob体育客户端下载我们也提供共享的笔记本和创作经验在KenSci, Julius将在稍后的网络研讨会上谈论。
关于第二个支点,对于医疗保健组织来说,拥有一个难以管理和扩展的复杂数据基础设施的整个想法是我们花费了大量时间和精力来开发的。如今,借助KenSci, Integris等医疗保健组织可以一键启动自动伸缩机制,根据数据的数量和速度,Integris类组织可以无缝地处理数据工作负载。一些内部特性和许多医疗保健客户选择KenSci的原因是通过数据健康报告对医疗保健数据进行操作化,利用Databricks Delta确保对传入的质量控制和验证对医疗保健进行细致入微的处理,并理解医疗保健数据所带来的粒度级别,当您试图将许多机器学习模型一起操作时,这非常有用。最后,但并非最不重要的是,在这个枢纽,是我们已经到位的企业级安全和合规性控制,使整个KenSci体验符合HIPAA和GDPR的基于角色的设置。您可以使用KenSci基础设施无缝地进行基于角色的数据访问控制。
在改善患者护理结果和投资回报率价值的第三个支点上,KenSci今天有超过17个用例支持数百个机器学习模型,这些模型在KenSci生态系统中无缝运行,无摩擦。我们称之为模型模板和加速器的每一个模型都由主题专家(包括临床医生)进行验证,以确保遵循这些机器学习模型的特征向量得到适当的管理,并映射到临床医生SME的理解。KenSci还提供了一些非常独特的开箱即用的东西,我们称之为我们的变化分析和快速跟踪路径,以推动ROI的快速价值。该产品的这一功能是帮助医疗保健客户使用Databricks将数据快速泵出KenSci,并为整个变化分析仪表板提供了开箱即用的动力,以便医疗保健组织中的c级高管及其团队能够真正开始从整个系统的优化角度看到分析机会在哪里。我们可以下次再详细讨论。我很高兴与大家分享我的一些想法。
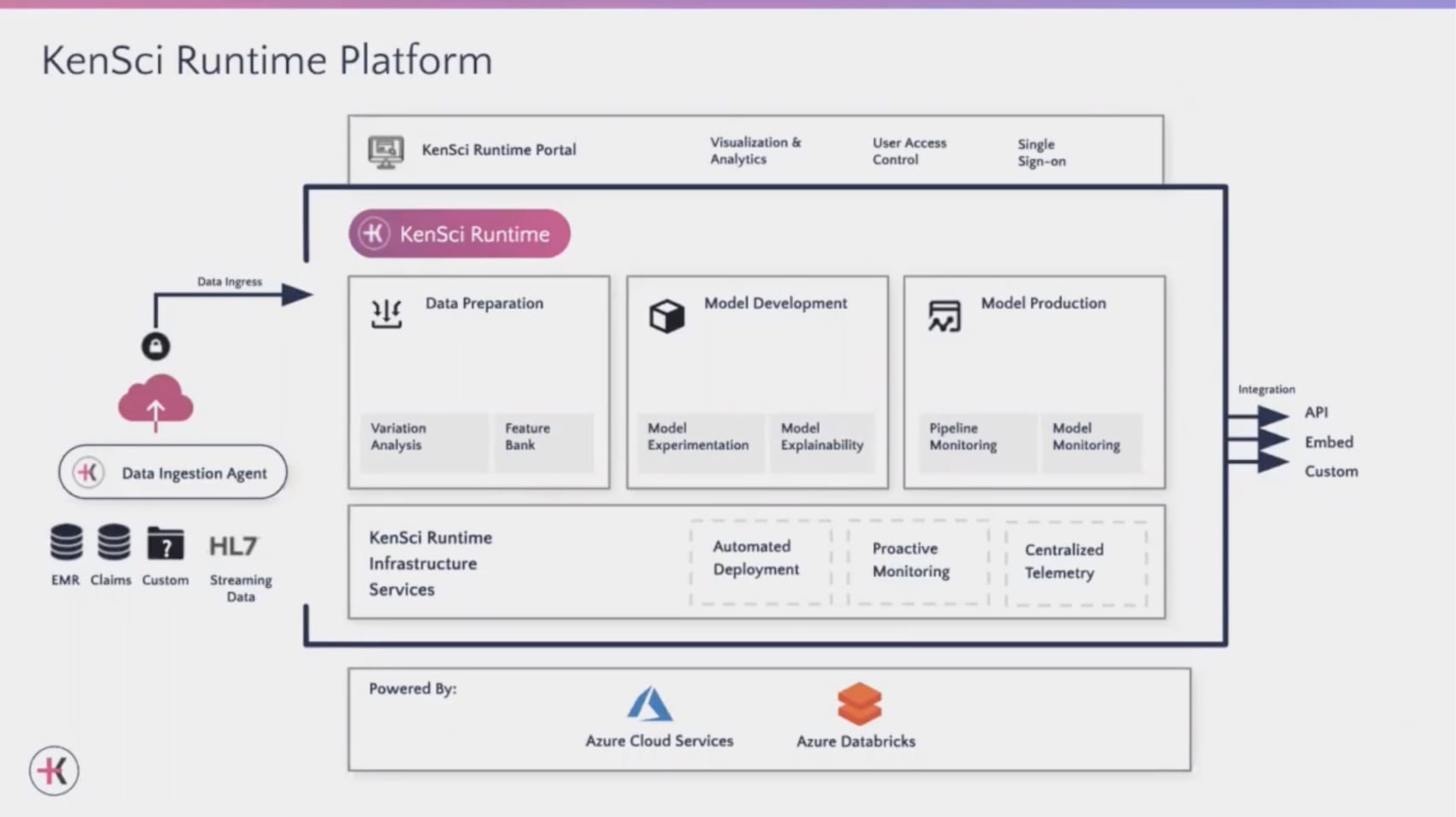
这是一个360度视图,一个顶级视图,KenSci开发的运行时平台。bob体育客户端下载在KenSci,我们很早就意识到建立一个机器学习模型是很好的。只要有两个轻微的数据中断,就会变得更容易,但保持整个管道从准备到模型开发再到医疗系统模型生产的运行仍然是一项繁重的任务。我们希望真正解放像Julius这样出色的数据工程师和数据科学家来完成他们的工作,创新他们将大部分时间和精力集中在他们每天与之交互的用例和业务用户上,因此,有了KenSci运行时基础设施服务集的想法,它可以自动处理部署、监控、集中遥测审计日志和合规原因。它都是在Azure上的Databricks上提供支持的,然后数据准备,模型开发和生产级别的流水线都是由KenSci通过包和KenSci提供的库来处理的。在此之上是KenSci运行时门户,它允许对您的报告进行管理、可视化和分析。
它允许您进行细粒度用户级访问控制,最好的部分是它将与您组织的单点登录功能集成,以便组织可以无障碍地迁移到云中,管理所有数据资产报告以及分析洞察,而无需更改任何安全协议或访问控制更改。最后,但并非最不重要的是,KenSci平台中的所有内容都可以作为API提供,可以嵌入到工作流程中,KenScbob体育客户端下载i保证确保这些API满足我们为患者和有需要的客户提供的sla和正常运行时间要求。这些需求可能相当严格,但到目前为止,我们已经相当成功地确保满足了这些需求和sla。
为了快速浏览KenSci为大型医疗保健组织(如Integris)添加的组件,首先我们提供托管基础设施服务。从快速部署到端到端基础设施管理,KenSci提供了一切。
接下来是托管数据摄取过程,从事件级数据到客户DMRs再到企业数据仓库。我们已经开发了连接器和数据输入管道,因此即使是原始hl7也可以通过一个工具进行处理,我们称之为KenSci Agent Ken,并且允许通过KenSci Agent Ken集成平台快速地从源数据移动和转换到云端。bob体育客户端下载该服务可以在预置的虚拟机上运行,也可以在云中运行,这取决于每个客户的自定义基础设施需求。它的主要作用是将数据从客户内部的企业数据仓库资产或直接从客户电子医疗记录或任何其他来源转移到云上的KenSci平台。bob体育客户端下载
我们很早就意识到的另一个非常重要的特性是,数百名数据科学家能够利用每个数据科学家的工作,因为他们正在努力塑造和启用机器学习工作负载。我们都知道,机器学习中90%到95%的工作并不是真正地建立模型,而是探索数据,塑造数据,创建特征,然后在预测模型中变得有价值。有了KenSci功能库,Julius可以共享他为一个模型创建的功能,并在他正在构建的其他模型中重用它们,但与此同时,他可以与Integris和他的团队中的其他四位数据科学家共享相同的功能,这样他们就不必重新创建这些功能,我们已经通过KenSci机器学习库中的平台包功能使这非常容易发现。bob体育客户端下载
您将在屏幕上看到Databricks环境,因此所有内容都在Databricks笔记本中。它使用非常熟悉的工具进行模型训练,它允许最终用户做的基本上是使用KenSci包和机器学习模型,人们可以将模型和通过KenSci加速器可用的功能导入到Databricks笔记本电脑中,然后运行整个管道进行训练,作为在Databricks笔记本电脑环境中的实验。同样,保留Databricks提供的工具和令人惊叹的强大功能,但为像Julius这样的团队的医疗保健领域用例添加价值加速器。
一旦建立了模型,而且不仅仅是一个模型,而是可能创建了机器学习模型的整个级联管道,您需要一个地方,让组织能够可靠地依赖这些模型,每天数千次地进行评分,以便产生大多数医疗保健组织所需的ROI。使用KenSci运行时或KenSci模型评分管道,只需几行代码,您就可以在Azure中使用Databricks编排整个管道,从安装数据一直到清理,再到运行评分引擎,并确保多个用例所需的数百个模型无缝启动,并生成输出,然后进入可视化工具或工作流,如果需要集成的话,可以移动回EMR。这是一个非常健壮的模型评分管道。它使用Azure数据工厂端到端编排,以便在工作流中实现无缝集成。
在医疗保健领域,模型监测和遥测极其重要。举个例子,我相信Julius过几分钟就会讲到,假设有一个预测模型预测医院里一个大的普通病房里病人的住院时间。为了确保管道启动并运行并产生正确的结果集,以便医院的运营能够无缝运行,确保模型输出的质量与我们在数据中看到的一致,以及在模型标准化并投入生产时最终的准确性或精度召回是非常重要的。KenSci模型生命周期中的模型健康监控工具将允许像Julius这样的人每天或每小时查看该情况,并了解和查看任何给定时间点的遥测输出,以确保模型性能不会下降到某个阈值以下。事实上,在KenSci平台中内置了一些机制和警报系统,如果模型的性能低于一定的接受水平或阈值,自动触发器可以通知Julius,然后返回并调查为什么bob体育客户端下载停留时间模型是不良的,以及再培训或数据质量问题是否阻碍了该模型的性能。
正如你所看到的,从一键式管理的基础设施服务到无缝无缝的数据摄取,允许在整个组织和全球范围内共享任何数据科学过程中最耗时的功能,如特性,使模型训练能够在Databricks环境中进行,以便该工具的简单性可供多个数据科学家共享和共同工作,运行整个管道。为数百个模型无缝评分,一直到遥测这些模型和它们的性能基准都在一个平台内提供,我们提供作为Databricks环境之上的KenSci平台。bob体育客户端下载这就是整体的价值主张。我想让朱利叶斯来给我们讲解一下如何在Integris建立和扩大创新。朱利叶斯,交给你了。接受挑战吧。
为Integris的临床团队建立和扩展创新

朱利叶斯减弱:
谢谢你,Ankur,也谢谢你,Frank,谢谢你的演讲,谢谢你对这些产品的贡献,这些产品是我们现在的基础。我是朱利叶斯·阿巴特。我是Integris Health的数据工程总监。到本周为止,我已经在这个组织工作两年了。如你所见,我们是俄克拉荷马州最大的非营利组织。我相信我们目前有大约1万名员工。我们为200万病人提供服务。大约有100多万个是活跃的。我们有一个国家认可的移植中心,也是该州心血管护理的卓越中心。目前,我们的数据工程团队专注于通过在临床和业务工作流中直接提供人工智能和流程合规性快速反馈来改进流程。
当我第一次在我们的新首席信息官Ben Mansalis博士手下工作时,我们必须考虑当前的分析状态,这是随着时间的推移而发展起来的。
我们的起点是随着时间的推移,对于很多人来说,你最终会有多个团队在不同的系统上工作。我们有软件即服务(SaaS)方面的专家,他们不用SQL编写Oracle数据库。我们有一些Oracle SQL的专家,他们不了解SaaS部分或自动化。当然,在我们上线后,我们有一个团队从EPIC中报告,他们完全在EMR中工作,然后我们有一些人从Clarity(报告服务器)报告,他们很少交谈、交流,或者有很多共享的知识和集成。还有大量的手工进程和单线程进程。许多人没有报道某个领域,他们报道的是特定的报道。如果有人去度假,这些服务线路或诊所系统的报告不会完成,我们的数据集成版本是两个不同的团队运行导出,然后会有一个分析师负责合并这些Excel表格。我相信这是一个很多人在不同地点听过很多次的故事。
当客户去不同的团队要求相同的报告时,报告给这些团队的内容是不一致的。随着时间的推移,指标定义会发生变化,如果没有适当的管理,不同的团队会报告不同的项目。一个很好的例子是,我可以要求两组人提供停留时间报告。有人可能会给我一个病人从入院到出院的全程住院时间。人们可以把这当作他们在这里的时候,包括午夜在内的耐心的日子。给我两个不同的数字,用于两个非常不同的原因。即使在单个团队中,也缺乏任何类型的分析变更控制,这意味着在数百个管理中,无论是通过Crystal报告服务,还是那些保存在某个共享驱动器中并每月手动运行一次的查询,当出现弃用或定义更改时,项目都不会更新。更改直到注意到错误才会传播,如果它甚至被注意到的话。这一切都导致系统对数据缺乏信任,并花费大量时间来获取数据,手动将其组合在一起,而没有足够的时间花在实际分析上,这将我们带到我们所采取的第一步。
我在这里代表我们的临床和商业情报部门,他们首先说,“允许我们集中所有的报告系统。”我们把所有团队聚集在一起,说:“我们要在一个平台上工作。”bob体育客户端下载计划是在整个组织中以开发测试和prod格式部署SQL server实例。对于那些更专业的人来说,我们说的是一些结实的机器,有几百gb的RAM,多个tb的硬盘和16核。所有我们想玩的玩具。然后,我的背景是分析服务,在一个熟悉支点和通用微软生态系统的组织工作,Power BI和分析服务模型是我们的部署方法。它的效果也很好,因为它非常友好,两个非营利组织,所以它不仅是一个简单的数据透视表工具,任何在Power pivot工作过的人都能理解它的基本原理,而且它也很容易作为一个新兴部门来销售,说:“嘿,我们想尝试一些新的东西。我们想要改进分析领域的任何干扰因素。”
另一件事是合并技能和数据的竖井,所以我们运行跨职能的敏捷团队,其中有工程师、科学家、分析师和报告作者,他们都在同一个项目和同一个系统中工作。我们有分析师,他们想要亲自操作我们的管道,他们与工程师一起工作,他们对他们交付的最终数据感到非常兴奋,并深入其中并提出这些问题,而不仅仅是支持团队的基础设施。我们还引入了项目范围和分析的概念。我们希望限制范围蠕变,并增加报告或项目的有效性,即使这意味着在某种程度上对客户不利。我们的团队还承担了接触客户的义务,他们不仅要了解客户对我们的要求,还要了解他们的最终结果。如果这是一种改进,我们能找到更好的方法吗?我们能否为他们跳出思维定势?当然,最重要的事情之一,就是围绕系统中的度量和测量的定义的整合。我们想要防止漂移,并创建一个实际的元数据字典,可以被人们利用,并节省我们团队的时间。
我们知道我们必须把整个系统统一到一个任务之下。我们在辐条和中心模型下与我们的敏捷团队一起工作,在系统周围有主题专家团队来帮助找到机会领域,利用我们正在发布的分析来评估在改进方面最大的价值,无论是在人口健康方面,还是在降低死亡率,再入院率方面,或者在某些领域降低成本,并帮助这些团队在整个系统中实施和社会化,增加采用。这些团队还被组建起来,作为管理工作的关键声音,这是在整个系统中显示住院时间的决定因素。包括什么价格?它包括哪些drg ?包括哪些类型的案例,这样人们就可以知道,当看到三个不同的报告和三个不同的版本时,潜在的指标是什么,这也对分析工具产生了令人难以置信的高需求。
Integris刚刚开始成为一个数据驱动的组织,所以当我们展示了可以生产什么,与数据交互和使用工具的低门槛是什么时,就有了令人难以置信的高需求,并产生了一些令人难以置信的项目。
我们努力将组织从关注滞后指标,等待来自CMS的高质量数据,等待数据仓库负载直到计费结束后一个月,看到数据并认为30天的延迟并不糟糕,“让我们看看这些领先指标。”让我们看看你昨天的表现。”我们展示的一个重要方法是社会参与分析。我们开始利用系统周围的主题专家团队确定流程,我们认为这些流程会影响医院的主要问题。你在这里看到的是我们进行的第一个项目之一,在整个系统中试点使用新生儿败血症风险计算器,以减少因潜在的错误或不准确的测试而被错误送往新生儿重症监护室的婴儿数量。你在左下角看到的是当我们让神经外科医生快速反馈他们的MME处方时,吗啡等效处方是,跟踪阿片类药物,到阿片类药物naïve的病人,在过去六个月里没有服用阿片类药物。
你在这里看到的是快速的进步。你看到的这条令人难以置信的垂直线是你开始向他们展示“你是这样做的”的那一刻。以下是你也可以迭代的方法,快速做出改变,评估昨天发生的事情,然后说,“为了达到目标,我需要做哪些不同的事情?”’”,虽然我们知道我们看到的是合规率从12%上升到26%,但我们说的是在很短的时间内合规率增加了一倍多。至于新生儿败血症风险计算器,这是一个非常顺利的过程,到最后,我们能够停止社会参与,因为我们在所有部门的所有病例中达到了90%到100%。然后问题来了。
就在我们达到目标的时候,因为我们有这些惊人的用例来展示这个系统,我们有令人难以置信的临床团队的支持,我们希望进行更多的试点,我们在技术上达到了极限。

正如我们在这里所说的,时机就是一切。我们是一个24小时运转的系统,所有的医院都是这样,不仅如此,我们的领导一大早就起床了。我们进行分层分组。从8点开始,团队聚集在一起,讨论问题,评估所有他们能传递到链条上的信息,无论是哪些病人昨天刚刚重新入院,我是否需要派出护理计划团队?我们昨天的收入和预算是多少?我们接受了多少手术?我们昨天的空置率是多少?这些不会被喝掉,但这些需要在早上准备好。我们围绕流程参与所做的一些出色工作需要一些沉重的开销,甚至对于我们拥有的机器也是如此。有些需要遍历笔记,使用通配符搜索我们认为超过100万个笔记的庞大数据集来找到非标准化的特定关键短语,然后经历整个过程,将数据从报告数据库和系统中迁移出来,对其进行转换,将其加载到分析服务模型中,完全处理该模型,只是增加了可能发生故障的更多步骤。
我们遇到的甚至是我们设置的这些出色的服务器,并认为只是蜜蜂的膝盖被日常工作负载完全压扁了。无论是内存膨胀还是CPU难以计算这些查询,我们总是开始在计时上落后。我们有一些流程暂停了,我们给客户带来了不确定性。我们冒着失去这些人信任的风险,这些人对我们非常有信心,我们真的想为他们做出一些出色的改变。
就在那时,在和KenSci的谈话中,我们说:“是时候在云端思考了,跳出物理的框框思考了。”我们的眼睛已经打开了最新的工具和游戏,尽管这些Spark集群改变了我们整个团队的生活,因为我们获得了Databricks环境的支柱。令人难以置信的速度。扩展的想法和感觉,“嘿,我只是使用我所需要的资源,“因为担心最初的云你按小时支付工具,很可能你没有思想这些术语,有能力使用尽可能多或尽可能少我们需要对手头的工作,给我们的团队组合的如前所述,支持多种语言是难以置信的降低进入壁垒。我们让BI开发人员能够立即开始在Databricks中进行构建,因为Spark SQL在语法上在许多方面与T-SQL非常接近。对于那些有数据科学背景并希望在该领域做出更多贡献的人来说,他们有能力使用Python,使用那些包,并真正完成他们上学时的工作和他们的目标。最重要的是速度。10倍的可能是低卖它的净流程,这需要几个小时的加载在早上,计算一年或两年的流程指标在10分钟内完成。我们被宠坏了。
然后是附加在它上面的多个数据源的想法。首先我们介绍了blob存储,然后很快KenSci向我们介绍了Delta Lake。这是我们整个云数据湖的基础。加速启动和合并的能力,因此每天从我们必须使用的文件etl中加载来自所有不同系统的不同数据。随着时间的推移,它使跟踪变得非常容易,并确保数据保真度对我们来说非常重要,可以建立信任,确保我们在本地和云中有准确的行,这样我们就可以完全放心地从任何一个位置运行相同的报告。Ankur提到的Agent Ken的出现,将这一切连接在了一起,这绝对是我们快速采用Databricks的关键,它可以轻松地将我们所有的资源都放到云端,就像他说的,解放了我们,让我们可以自由地使用它。
这是,当我们从数据仓库的想法转移到模式仓库的想法时,所以我们在90分钟内就有数据可用,有时更少,当Agent Ken第一次启动时,而不是做ETL,我们只是做一个提取和加载。我们将所有数据以原生格式保存在数据湖中,没有转换,没有预连接。而不是必须进行备份,必须对100个包进行经典的数据仓库,我们所有的变更控制都构建在我们利用的模式中。除非必须,否则我们不会查询底层数据。相反,我们使用预定义的逻辑查询构建在数据之上的Us,这允许我们在任意数量的报告、任意数量的数据模型、任意数量的特性中引用相同的逻辑,并且只在一个位置进行更改。

我之前讲过速度。光是我们移动的速度就令人难以置信。之前运行查询的项目,喝杯咖啡,吃午饭,回来,也许它会完成,我真的希望没有错误,我必须再次运行它,现在在几分钟内完成。我们能够迭代我们的创造力和学习的步伐。在30到45分钟的时间内,您就越早了解到某些东西存在问题,需要更改,需要从模式端到端传播到数据模型中。然后,Power BI中构建的Spark连接器允许我们通过自助数据模型轻松地转换现有的交付格式,只需指向Databricks hive实例,并从那里获取我们实现的数据。
然后,这把我们带到了现在的位置,从组织中获得了令人难以置信的信心,并有能力做我们想做的工作,有能力迅速行动并交付到所有领域。我们已经从几乎没有及时获得数据(如果确实加载了,通常也会延迟)的阶段,发展到推动整个系统的流程改进,并能够出去推动采用,最重要的是,自助报告。建立一个与我们所需要的任何系统规模相当的分析团队是非常困难的,所以将数据以一种简化的、可用的、结构清晰、定义清晰的格式交到用户手中可以扩展容量和思维。把数据交给专家可以让他们提出问题,而不是跳过我们,让我们把时间集中在你在这里看到的项目上。我们从神经外科领域的新生儿败血症和阿片类药物订单,到现在致力于通过深入和外展来推动人口健康,跟踪人群的筛查率,标记谁需要筛查,并提供接近实时反馈的医疗援助。
对于每一个来就诊需要这些检查的病人,你是否完成了他们的订单,然后询问呼叫中心,在过去三个月来就诊并有订单的病人,我们是否打电话给他们,让他们完成这些订单,完成这些测试包,为他们的健康做乳房x光检查?然后从医院的参与过程来看,我们说:“让我们来解决大问题。让我们试着减少摔倒。让我们努力降低压疮的发病率"所以我们开始参与社会活动大约两小时轮转病人,护士之间的流程依从性和每小时轮转以减少医院内的摔倒率。我们发现,我们担心的是,随着我们的扩张,我们会成为那个部门,成为那些进来的人,给你增加更多的工作,但事实证明,人们想要的是反馈。让他们知道自己前一天的表现会让他们兴奋。当我们进行四舍五入时,我们看到外面的团队围着数据挤在一起,向我们提出问题,很兴奋地想知道这个过程是如何在后台工作的,想知道如果护理团队的任何成员检查了病人,他们是否都得到了信任?他们能一起工作吗?
现在我们有了基础设施,我们正在努力采用KenSci平台,作为一种方式,超越滞后指标,领先指标,进入预测指标,作为工作流程的一部分,并建立对人工智能系统的信心,就bob体育客户端下载像他们现在对我们的分析一样。我想感谢你们两位抽出时间,感谢我们每天都在使用的这些工具,就这样。我们可以走到最后。
迈克·奥尔特加:
太棒了,朱利叶斯。谢谢你!
朱利叶斯减弱:
我要分享这个。这句话被认为是亚伯拉罕·林肯说的。“给我六个小时砍倒一棵树,我会用前四个小时磨斧头。”数据库和肯探员是我们的磨刀石,让我们能够走出去。谢谢你!
常见问题
迈克·奥尔特加:
太棒了。感谢你分享你的故事,感谢你们所做的所有伟大的工作,改善整个医院的手术,以及你们取得的一些巨大成功。今天有很多很棒的故事,我现在想做的是,顺便感谢我们所有的演讲者,Frank和Ankur,他们分享了Databricks平台以及KenSci放在上面的使能器如何让医院和医疗保健系统做和Julius一样的工作。bob体育客户端下载
Integris团队是如何跟上所有新工具的速度的?采用这些技术的过程是怎样的?
朱利叶斯减弱:
正如我所说,很大一部分原因在于Spark SQL和T-SQL之间的相似性,因此,作为报告撰写者、开发人员、分析师,能够将他们现有的知识放到一个新的环境中,并能够被告知,“听着,放上一些眼罩是可以的。您不必担心现在可以使用的所有附加功能。您仍然可以编写查询。您仍然可以创建视图。你仍然可以用自己非常熟悉的格式构建逻辑。”这是一个很大的部分。然后另一部分是让肯探员能够说,“嘿,数据在这里。数据已经准备好了,”所以最大的障碍可能是,或者最大的教学时刻,只是理解我们现在建立模型的方式。这是PBIX,这是连接器,这是数据集如何工作以及我们如何连接到它的源数据。实际上,虽然Databricks有很多功能,我们可以用它做很多事情,其中一些我现在还无法做到,我还在学习中,有些人花了几个月的时间,我们每天的工作和翻译都非常快。
迈克·奥尔特加:
太棒了。现在你可以访问实时数据,并引入一系列不同的数据源,从人力资源系统,运营系统,当然还有预测分析,你开始看到的一些前沿用例是什么,或者你是否开始看到现在你有实时数据和预测能力的价值?
朱利叶斯减弱:
我们做的第一个实时操作不仅仅是利用最后一天的功能,报告数据库,而是通过api或HL-7s引入实时数据,以便在临床楼层和手术室实时提高人员配备效率,所以给不同楼层、不同部门的经理反馈,告诉他们现在谁被认为是人手过剩或人手不足。我们可以在哪里调动人员?我们希望在我们的旗舰医院尝试和试点效率最大化。这是最大的问题之一。另一种则是将人们从未有过的自助服务的基础进行了完善,制作了一些非常详细的分析工具和专门的模型,使他们能够自己回答问题,以更快的速度回答问题,回答关于最近发生的事情的问题,而这些问题以前只是在他们的脑海中出现。随着人们意识到数据的可用性,问题实际上仍在不断涌现,所以我们仍在了解人们的思想随着数据的变化而变化。
迈克·奥尔特加:
Ankur和Frank,你们显然在很多不同的医疗系统中工作过。你所看到的一些新兴用例正在增加实时数据访问的即时价值?
Ankur Teredesai:
非常好的问题。我有时会把通过Databricks和KenSci平台集成的这种级别的数据粒度的可用性等同于一个金矿,现在可以慢慢地和有意地收获。bob体育客户端下载一旦这个个性化机器学习流程和见解的基本管道可用,人们就开始在许多不同的用例中真正实现价值。尤其令我兴奋的是病人流量用例,它预测了早期到达,人口普查,导致了普通病房的住院时间管理。人们对从普通病房到重症监护室,再从重症监护室回到普通病房,然后再回到普通病房的升降问题都很感兴趣,所以从更广泛的角度来看,人们对能够捕捉卫生系统内的操作状态很感兴趣,可以启用这样的多个用例。我们看到的另一件事是出院计划。非常复杂的出院计划,从出院处置到预测哪些病人可能会短期住院,这对卫生系统来说是非常沉重的负担,无论是收入还是人员配备,正如朱利叶斯已经提到的。整个套件正在变得活跃起来,我注意到我们的客户合作伙伴要求KenSci构建更多的加速器,以便自定义这些模型,并将其放入管道中用于端点api或向bob体育外网下载后集成到EMR中。
Frank Nothaft:
是的。我认为Ankur和Julius提供了很多有价值的东西,所以我会简短地说,但有一件事让我很兴奋,我看到很多人对自己感到非常兴奋,那就是一些地方能够使用这个直播,实时数据流来做一些预测,让人们更多地关注处于边缘情况的病人,在接下来的几分钟到几小时的治疗过程中,他们的病情严重程度可能会增加或减少,诸如此类。我们已经看到人们在这个领域做了大量创新的事情,我认为这是一个非常非常重要的领域,值得我们所有人关注。
迈克·奥尔特加:
Frank, Delta Lake和开源技术是如何在这些实时用bob下载地址例中发挥作用的?
Frank Nothaft:
好问题,好问题。我认为如果你想到我们正在使用的数据时,这往往被从根本上以流媒体的方式,不管是得到收集的变化数据捕获管道电缆在人力资源或我们是否使用直播HL-7饲料,我们需要一个好地方土地数据的原始格式之前我们所做的任何类型的转换到一个新的格式,可以支持它。有了这些馈送,随着它们变得越来越大,随着我们进入更大的医院系统,我们实际上可以处理大量传入的数据。这个数据集可以快速增长到很多tb, pb级的大小。对于Delta Lake,作为一种高性能文件格式,它提供了一个资产一致性层,实际上是专门为支持流用例而设计的。虽然你可能不得不使用一个专为流数据量身定制的数据库系统,但它专为少量数据量身定制,但Delta Lake允许你将这些数据流到高性能和低成本的近对齐的云存储中,在那里你可以轻松使用常见的ETL、数据工程和数据科学库(如Spark)。它确实减少了在实时和接近实时环境中处理这些复杂流数据源的障碍。
迈克·奥尔特加:
Ankur,在Databricks之上的KenSci应用程序组合中,有多少应用程序是开箱即用的,几乎没有修改,而不是让医疗保健系统使用他们的工具重新开发他们的应用程序?什么是开箱即用,什么是重做?
Ankur Teredesai:
又一个好问题。医疗保健是如此微妙。我们都花了几十年的时间试图集成数据,并理解安装EMR和自定义提要带来的细微差别。我们发现,与其做一个从左到右的旅程,从试图转换所有来自人力资源、调度和计费系统的数据,然后试图在此基础上为机器学习建立语义层,不如把它作为一个从中到左,从中到右的问题,首先从小的角度解决问题,找出对机器学习和洞察分析重要的主要特征转换和属性,然后手动或通过加速器进行转换,这将带来更好的开箱即用体验。当然,最后一英里总是具有挑战性的,定制确实需要一点时间,但特别是像Integris这样的卫生系统,甚至需要6到8个月才能建立一个模型,并称之为健壮的并验证它,KenSci已经能够在6周左右的时间内完成整个工作流程。因为使用了开箱即用的组件,这是一笔可观的节省。
在出站方面,对于最终用户,如出院计划或医院操作,KenSci提供了可定制的仪表板乐高积木,但我们的游戏实际上是api和有保证的sla,然后可以针对安装设置进行调整和定制,我们可以作为附加服务,或者如果开箱即用的组件足够多,那么我们就会这样做(在10个案例中有8个是这样)。定制的水平,但是我们给医疗系统带来的真正价值,正如Julius指出的,是由于数据管道和现成的功能工程,以及由于Databricks的笔记本电脑体验和Delta Lake技术而开放的模型模板的快速加速,因此可以更快地进行客户合作伙伴可能想要的任何类型的定制。
迈克·奥尔特加:
太棒了。我想对我们的演讲者说声谢谢。在医疗保健环境中应用机器学习和规模化分析的伟大转换。



联系我们为个性化的演示//www.neidfyre.com/company/contact
