




通过Delta Live table向零售商提供实时数据
注册参加“交付零售洞察”网络研讨会,了解更多关于零售商如何通过Delta Live Tables实现实时BOB低频彩决策的信息。大流行…
2022年8月4日 在工程的博客
查看我们的新订单拣选优化解决方案加速器欲知详情,请下载笔记本。
对网上购买店内提货(BOPIS)、路边和当天送货上门的需求也在增加迫使零售商将当地商店作为快速履行中心。在大流行的早期,许多零售商措手不及炒引入和扩大这些服务的可用性,利用现有的库存和基础设施及时交付货物。随着购物者回到商店,对这些服务的需求也在增加有增无减最近的调查显示,人们对更多更快的选择的期望只会更低增加在未来的岁月里。这让零售商们开始思考如何才能更好地在长期内实现这些功能。
如今,大多数零售商面临的核心挑战不是如何及时将商品交付给顾客,而是如何在留住顾客的同时做到这一点盈利能力。据估计,利润减少了3到8个百分点在每个订单放置在线快速履行。派一名工人到货架上为每一份订单挑选商品的成本是主要的罪魁祸首随着劳动力成本的不断上升(而消费者对为越来越被视为基本服务的服务支付额外费用几乎没有兴趣),零售商感到压力很大。
自动化仓库和为拣货效率优化的黑暗商店等概念已被提出作为解决方案。然而,所需的前期资本投资,以及对这种模式在除最大市场以外的所有市场的可行性的质疑,导致许多人将注意力集中在继续使用现有门店上。事实上,全球最大的零售商沃尔玛最近宣布它致力于这一方向,尽管有一些店内的变化,旨在提高他们的努力效率。
在沃尔玛和许多其他公司提出的履行模式中,现有的门店足迹是一个核心组成部分快速实施策略。在最简单的模型中,工作人员遍历商店布局,为网上订单挑选商品,然后从柜台或储藏室包装和运输。在更复杂的模型中,高需求的商品被安排在后台的履行区域,从而减少了将工人派到挑选生产率下降的车间的需要。
店内采摘生产率的下降是通过设计。在传统零售场景中,零售商利用客户提供的免费劳动力来增加在店内的时间。通过将顾客从商店的一端送到另一端,以挑选他们在访问期间经常需要的商品,零售商增加了顾客对现有商品和服务的接触。通过这样做,零售商增加了额外购买的可能性。
对于负责代表客户挑选订单的工人来说,冲动购买根本不是一种选择,而且长时间的遍历只会增加履行成本。作为一名分析师笔记,“在商店环境中,工作效率的杀手是旅行距离。”最大限度地发挥亲自购物者潜力的商店设计决策与那些负责全渠道实现的决策是不一致的。
大多数购物者都认识到大多数商店布局固有的低效率。节俭的购物者通常会携带一份商品清单,并经常优化清单上商品的排序,以减少在部门和过道之间的往返。对产品植入的了解以及某些商品的特殊处理需求,可以确保更有效地通过商店,并最大限度地减少重复旅行以更换运输中损坏的商品的可能性。
但是,这种通过多年的经验和对所购买物品的熟悉而建立起来的知识,可能对一个经常是一个人的挑选者来说是不可能的演出人员为别人取单是偶尔做的副业。对于这些工作人员来说,要挑选的商品列表可能没有提供关于最佳排序的线索,让他们按照给出的顺序遍历商店挑选商品。
在最近一篇题为网上购买-店内提货零售模式:店内挑选和包装的优化策略,利等。以一个布局如图1所示的杂货店为例,研究了几种挑选顺序优化的效率。
使用历史顺序,作者改变了物品的挑选顺序,以实现各种目标,如最小化总遍历时间和最小化产品损坏。他们将这些数据与提供给挑选者的默认排序顺序进行了比较,后者是基于最初添加到在线购物车的商品的顺序。他们的目标不是为所有零售场景确定一种最佳方法,而是提供一个评估不同方法的框架,以便其他人在寻求提高挑选效率的方法时可以效仿。
有了这个目标,我们用330万份订单重新创作了他们的部分作品Instacart数据集映射到所提供的商店布局作为论文作者使用的专有订单历史对我们来说是不可用的。虽然历史数据集不同,但我们发现不同测序方法对采摘时间的相对影响与作者的发现密切相关(图2)。
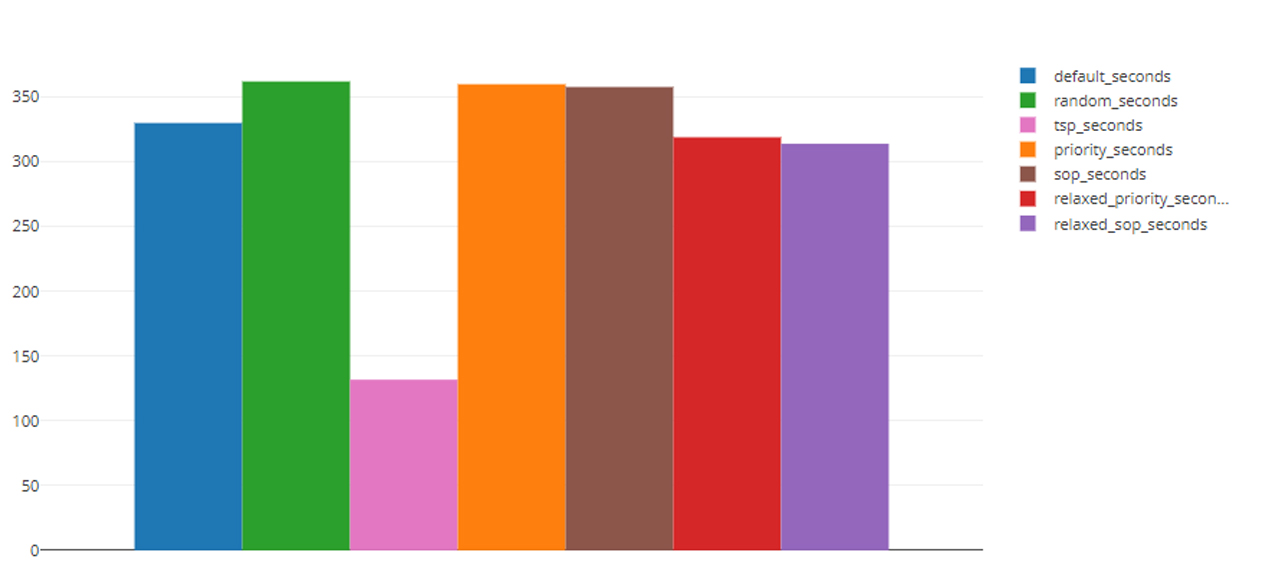
在优化策略的评估中,将各种算法应用于历史数据集是一种常见的做法。使用先前的配置和场景,优化策略的效果可以在应用于现实世界之前进行评估。这样的评估可以帮助组织避免意想不到的结果,并评估方法中微小变化的影响,但执行起来可能相当耗时。
但是通过并行工作,通常花费在评估方法上的几天甚至几周可以减少到几小时甚至几分钟。关键是在更大的评估集中识别离散的、独立的工作单元,然后利用技术将这些单元分布到大型计算基础设施中。
在上面探索的拾取优化中,每个订单代表这样一个工作单元,因为一个订单中的项目排序不会影响其他任何订单的排序。在极端的情况下,我们可能会同时对所有330万进行优化,以极快地执行我们的工作。更典型的情况是,我们可以提供较少数量的资源,并将较大资源集的子集分配给每个计算节点,从而使我们能够平衡提供基础设施的成本与执行分析的时间。
Databricks在这个场景中的强大之处在于,它使得云中的资源配置非常简单。通过将我们的历史订单加载到Spark数据框架中,它们立即分布到已供应的资源中。如果我们提供了更多或更少的资源,数据帧就会重新平衡自己,而不需要我们付出额外的努力。
诀窍是将优化逻辑应用于每个订单。使用一个Pandas用户自定义函数(UDF),我们能够以有效的方式将开源库和自定义逻辑应用bob下载地址于每个订单。结果返回到数据框架,然后可以持久化并进一步分析。要了解这是如何在上面引用的分析中完成或在您的组织中实现的,请检查我们的解决方案加速器优化的订单选择。

