






将自然语言处理大规模应用于医疗保健文本
本文是我与John Snow实验室的AI布道者Moritz Steller合作撰写的一篇文章。观看我们的按需车间,提取现实世界…
下健康保险携带与责任法案(HIPAA)根据最低必要标准,hipaa涵盖的实体(如医疗系统和保险公司)必须做出合理努力,确保获得受保护健康信息(PHI)的权限仅限于实现特定使用、披露或请求的预期目的所需的最低必要信息。
在欧洲,GDPR列出了公司在分析或共享医疗数据之前必须满足的匿名化和伪匿名化要求。在某些情况下,这些要求超出了美国的规定,还要求公司对性别身份、种族、宗教和工会从属关系进行修订。几乎每个国家对敏感的个人和医疗信息都有类似的法律保护。
诸如此类的最低必要标准可能会对推进人口层面的保健研究造成障碍。这是因为医疗保健数据的大部分价值在于半结构化叙事文本和非结构化图像,其中通常包含难以删除的个人可识别的健康信息。例如,这样的PHI使得组织内的临床医生、研究人员和数据科学家很难注释、训练和开发能够预测疾病进展的模型。
除了合规性之外,在分析之前对PHI和医疗数据进行去标识的另一个关键原因(特别是对于数据科学项目)是防止偏见和从虚假相关性中学习。删除患者的地址、姓氏、种族、职业、医院名称和医生姓名等数据字段,可以防止机器学习算法在进行预测或建议时依赖这些字段。
医疗保健自然语言处理(NLP)领域的领导者John Snow Labs和Databricks正在合作,通过一系列针对常见NLP用例的Solution Accelerator笔记本模板,帮助组织大规模处理和分析其文本数据。你可以在我们之前BOB低频彩的博客中了解更多关于我们合作的信息,bob体育外网下载自然语言处理在大规模卫生文本中的应用.
为了帮助组织自动删除敏感的患者信息,我们构建了一个用于去除PHI的联合溶液加速器它建立在医疗保健和生命科学数据库湖屋的基础上。John Snow Labs在开源Spark NLP库的基础上提供了两个商业扩展,这两个扩展对去身份识别和匿名化任务都很有用,在这个Accelerator中使用:
下面是解决方案加速器的高级演练。
在本解决方案加速器中,我们将向您展示如何从医疗文档中删除PHI,以便在不泄露患者身份的情况下共享或分析这些文档。以下是工作流的高级概述:
你可以访问笔记本获取解决方案的完整演练。

作为第一步,我们从云存储中加载所有PDF文件,为每个文件分配一个唯一的ID,并将生成的dataframe存储到Lakehouse的Bronze层中。注意,原始PDF内容存储在二进制列中,可以在下游步骤中访问。

在下一步中,我们从每个文件中提取原始文本。由于PDF文件可以有多个页面,因此更有效的方法是先将每个页面转换为图像(使用PdfToImage()),然后对每个图像使用ImageToText()从图像中提取文本。
#转换PDF文档为每页图片pdf_to_image = PdfToImage()\.setInputCol (“内容”) \.setOutputCol (“图像”)#运行OCRocr = ImageToText()\.setInputCol (“图像”) \.setOutputCol (“文本”) \.setConfidenceThreshold (65) \.setIgnoreResolution (假)
ocr_pipeline = PipelineModel(stages=[pdf_to_image,光学字符识别])与SparkNLP类似,transform是Spark OCR中的标准化步骤,用于对准任何与Spark相关的转换器,可以在一行代码中执行。
Ocr_result_df = ocr_pipeline.transform(pdfs_df)请注意,您可以直接在笔记本中查看每个单独的图像,如下所示:

应用此管道后,我们将提取的文本和原始图像存储在DataFrame中。请注意,图像、提取的文本和原始PDF之间的链接是通过云存储中的PDF文件路径(和唯一ID)保存的。

通常,扫描的文档质量较低(由于图像倾斜,分辨率较差等),导致文本不准确,数据质量较差。为了解决这个问题,我们可以在sparkOCR中使用内置的图像预处理方法来提高提取文本的质量。
下一步,我们处理图像以增加可信度。Spark OCR具有ImageSkewCorrector它检测图像的倾斜并旋转它。在OCR管道中应用此工具有助于相应地调整图像。然后,通过应用ImageAdaptiveThresholding工具,我们可以根据局部像素邻域计算一个阈值掩码图像,并将其应用于图像。我们可以添加到管道中的另一种图像处理方法是使用形态操作。我们可以用ImageMorphologyOperation它支持侵蚀(去除物体边界上的像素),膨胀(为图像中对象的边界添加像素)、开幕(从图像中删除小物体和细线,同时保留图像中较大物体的形状和大小)及关闭(与打开相反,用于填充图像中的小孔).
删除背景对象ImageRemoveObjects可以用来以及添加ImageLayoutAnalyzer以管道为例,分析图像并确定文本的区域。我们完全开发的OCR管道的代码可以在加速器中找到笔记本.
让我们看看原始图像和修正图像。

经过图像处理后,我们有一个更干净的图像,置信度增加了97%。

现在我们已经校正了图像偏度和背景噪声,并从图像中提取了校正后的文本,我们将得到的DataFrame写入Delta中的Silver层。
一旦我们完成使用Spark OCR来处理文档,我们就可以使用临床命名实体识别(NER)管道来检测和提取文档中感兴趣的实体(如姓名、出生地等)。我们在一篇文章中更详细地讨论了这个过程上一篇博文从实验室报告中提取肿瘤学见解。
然而,临床记录中通常有PHI实体,可用于识别个体并将其与已识别的临床实体(例如疾病状态)联系起来。因此,在文本中识别PHI并混淆这些实体非常关键。
这个过程有两个步骤:提取PHI实体,然后隐藏它们;同时确保结果数据集包含对下游分析有价值的信息。
与临床NER类似,我们使用医学NER模型(ner_deid_generic_augmented)来检测PHI,然后我们使用“faker方法”来混淆这些实体。我们完整的PHI提取管道也可以在加速器中找到笔记本.
管道检测PHI实体,然后我们可以用NerVisualizer对其进行可视化,如下所示。

现在要构建一个端到端的去识别管道,我们只需在PHI提取管道中添加混淆步骤,将PHI替换为假数据。
混淆=去识别()\.setInputCols ([“句子”,“令牌”,“ner_chunk”]) \.setOutputCol (“鉴定”) \.setMode (“混淆”) \.setObfuscateRefSource (“骗子”) \.setObfuscateDate (真正的)
obfuscation_pipeline =管道(阶段=[deid_pipeline,困惑])在下面的例子中,我们编校了病人的出生地,并将其替换为一个假位置:

除了混淆之外,用于医疗保健的SparkNLP还提供了用于编校的预训练模型。下面是一个屏幕截图,显示了这些编校管道的输出。

SparkNLP和Spark OCR可以很好地协同工作,用于大规模的PHI去识别。在许多情况下,联邦和行业法规禁止分发或共享原始文本文件。如前所述,我们可以创建一个可伸缩的自动化生产管道,对pdf中的文本进行分类,混淆或编校PHI实体,并将结果数据写回Lakehouse。然后,数据团队可以轻松地与下游分析师、数据科学家或业务用户共享这些“净化”的数据和去标识信息,而不会损害患者的隐私。下面是Databricks上这个数据流的概要图。
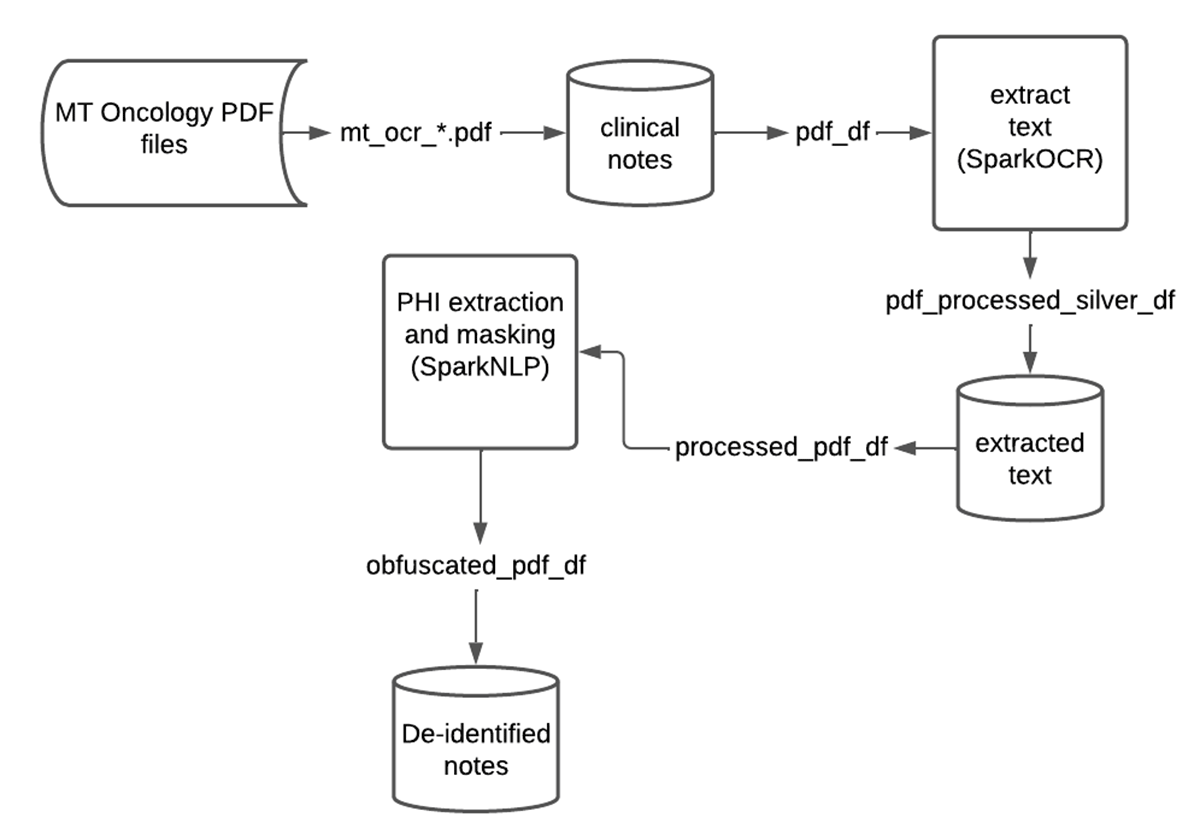
通过这个解决方案加速器,Databricks和John Snow Labs可以轻松地自动去识别和混淆PDF医疗文档中包含的敏感数据。
要使用此解决方案加速程序,您可以预览笔记本电脑在线并直接导入到您的Databricks帐户。笔记本包括安装相关的John Snow Labs NLP库和许可密钥的指导。
你也可以访问我们的医疗保健和生命科学湖屋页以了解我们所有的解决方案。

