






获得免费的Delta Lake:权威指南(早期发布)
在数据+人工智能峰会上,我们激动地宣布Delta Lake:权威指南的早期发布,奥莱利出版。这个指南教我们如何建立一个现代湖屋建筑它将仓库的性能、可靠性和数据完整性与数据湖中可用的非结构化数据的灵活性、规模和支持结合在一起。它还展示了如何使用Delta Lake作为湖屋的关键使能器,在开放Parquet格式的基础上提供ACID事务、时间旅行、模式约束等。Delta Lake增强了Apache Spark,通过支持数据完整性、数据质量和性能,使存储和管理大量复杂数据变得更加容易。
从阅读这篇指南中你能期待什么?方法为数据湖带来事务性和可靠性三角洲湖.您将了解大数据技术景观的演变——从数据仓库到数据湖屋.
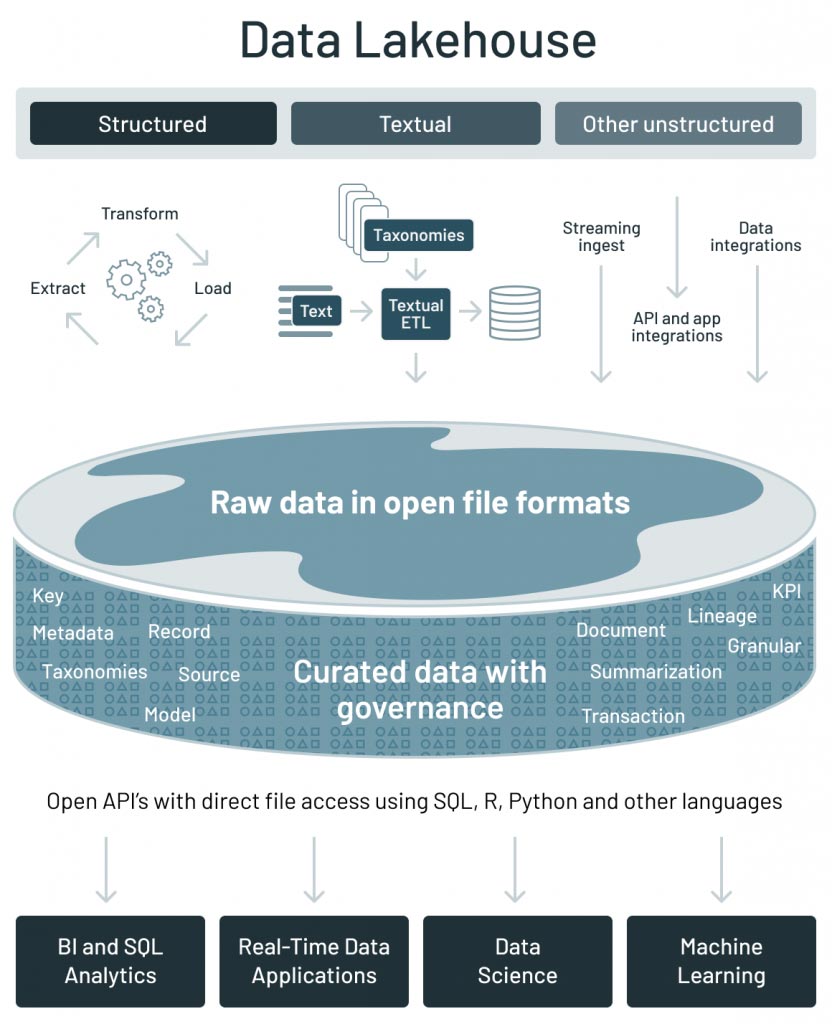
与构建数据管道相关的挑战并不缺乏,本指南介绍了如何解决这些挑战,并使数据管道健壮可靠,以便下游用户既能实现重大价值,又能依靠他们的数据做出关键的数据驱动决策。
而许多组织已经标准化了Apache火花™作为大数据处理引擎,我们需要为数据湖添加事务性,以确保高质量的端到端数据管道。这就是三角洲湖的由来。三角洲湖增强Apache火花通过支持数据完整性、数据质量和性能,可以轻松存储和管理大量复杂数据。随着最近的公告迈克尔时常要而且马泰Zaharia, Databricks最近发布Delta Lake 1.0在Apache Spark 3.1上,增加了实验性支持谷歌云存储,Oracle云存储而且IBM云对象存储.关于这个版本,我们也做了介绍三角洲分享,一个开放的协议用于大型数据集的安全实时交换,使组织能够实时共享数据,而不管他们使用哪种计算平台。bob体育客户端下载我们将在本书的未来版本中逐步介绍所有这些版本的指南。
本指南旨在指导数据工程师、数据科学家和数据从业者如何使用Delta Lake大规模构建可靠的数据湖和数据管道。此外,你将:
- 了解关键的数据可靠性挑战以及如何解决它们
- 了解如何使用Delta Lake实现数据可靠性提升
- 了解如何针对数据湖并发运行流作业和批处理作业
- 探索如何针对数据湖执行更新、删除和合并命令
- 深入研究使用时间旅行来回滚和检查数据的以前版本

- 学习为实际用例构建有效、高质量的端到端数据管道的最佳实践
- 与其他数据技术集成,如Presto, Athena, Redshift和其他BI工具和编程语言
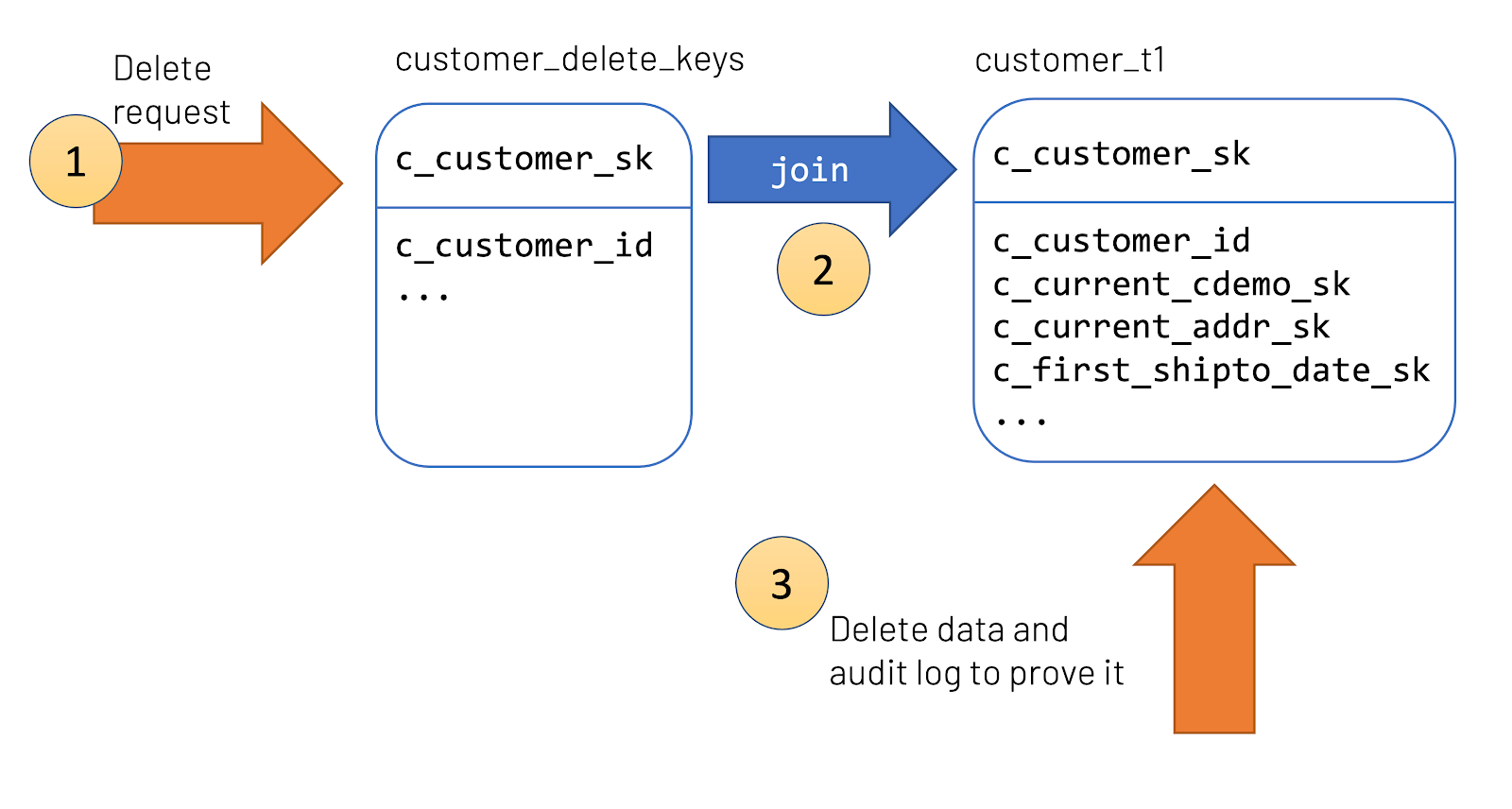
- 了解事务日志可以成为绝对救星的不同用例,例如数据治理(GDPR / CCPA):
读者角色
本指南不要求任何先验知识现代湖屋建筑不过,对大数据、数据格式、云架构和Apache Spark有一定的了解是有帮助的。虽然我们邀请任何对数据架构和机器学习感兴趣的人来查看我们的指南,但它对以下方面特别有用:
- 数据工程师有Apache Spark或大数据背景
- 机器学习工程师谁参与日常数据工程
- 数据科学家谁有兴趣学习管理数据的幕后数据工程
- dba(或其他操作人员)了解SQL和DB概念,并希望将他们的知识应用于数据湖的新世界
- 大学的学生谁在学习计算机科学、数据和人工智能的所有可能的东西
电子书的早期发行现在可以从砖而且O ' reilly.你可以阅读最早形式的电子书——作者写的原始和未经编辑的内容——所以你可以在这些书名正式发布之前很久就利用这些技术。最终的电子版预计将于2021年底发布,印刷版将于2022年4月推出。多亏了加里•奥布莱恩,杰斯哈伯曼而且克里斯Faucher奥莱利帮我们出版了这本书

为了让你先睹为快,这里有一段摘自第二章的描述三角洲湖是什么。
三角洲湖是什么?
如前所述,随着时间的推移,已经构建了不同的存储解决方案来解决数据质量问题——从数据库到数据湖。从数据库到数据湖的转换支持业务逻辑与存储的解耦,以及独立扩展计算和存储的能力。但在这种转变中,人们忽略了如何确保数据的可靠性。为数据湖提供数据可靠性导致了Delta Lake的发展。
Delta Lake由Apache Spark的最初创建者构建,旨在结合在线分析工作负载的优点(即OLAP风格):数据库的事务可靠性与数据湖的水平可伸缩性.
Delta Lake是一种基于文件的开源存储格式,提供ACID事务、可扩展的元数据处理,并统一流和批处理数据。它运行在您现有的数据湖之上,并与Apache Spark和其他处理引擎兼容。具体来说,它提供了以下特性:
- 酸担保:Delta Lake确保写入存储的所有数据更改都提交以保证持久性,并且对读取器原子可见。换句话说,不再有部分或损坏的文件!我们将在本章后面的事务日志中讨论更多关于acid担保的内容。
- 可伸缩的数据和元数据处理:由于Delta Lake是建立在数据湖上的,所有使用Spark或其他分布式处理引擎的读写都固有地可扩展到pb级。然而,与大多数其他存储格式和查询引擎不同,Delta Lake利用Spark向外扩展所有元数据处理,从而有效地处理千兆字节级表中数十亿文件的元数据。我们将在本章后面讨论更多关于事务日志的内容。
- 审计历史和时间旅行:Delta Lake事务日志记录对数据所做的每个更改的详细信息,提供更改的完整审计跟踪。这些数据快照使开发人员能够访问并恢复到早期版本的数据,以进行审计、回滚或重现实验。我们将在第3章:德尔塔时空旅行中进一步探讨这个主题。
- 模式强制和模式演进:Delta Lake会自动防止插入模式不正确的数据,即不匹配表模式。在需要时,它允许显式地、安全地改进表模式,以适应不断变化的数据。我们将在第4章进一步探讨这个主题,重点是模式的实施和演变。
- 支持删除、更新和合并:大多数分布式处理框架不支持对数据湖进行原子数据修改操作。Delta Lake支持合并、更新和删除操作,以支持复杂的用例,包括但不限于更改数据捕获(CDC)、缓慢更改维度(SCD)操作和流式upserts。我们将在第5章:Delta中的数据修改中进一步探讨这个主题。
- 流和批量统一:Delta Lake表既可以批处理,也可以作为流源和接收器工作。跨越各种延迟(从流数据输入到批量历史回填到交互式查询)的工作能力都是开箱即用的。我们将在第6章:使用Delta的流应用程序中进一步深入讨论这个主题。
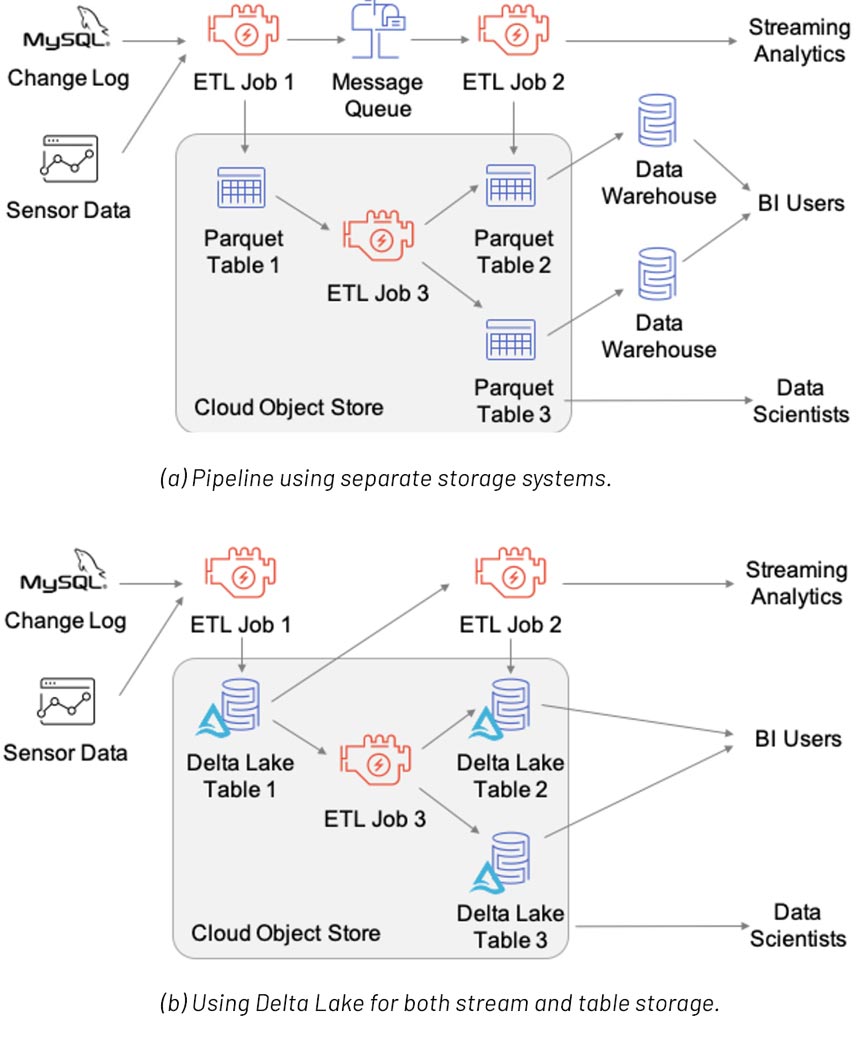
上图(引用自VLDB20论文)显示了使用三个存储系统(消息队列、对象存储和数据仓库)实现的数据管道,或者使用Delta Lake进行流和表存储。Delta Lake版本无需管理多个数据副本,只使用低成本的对象存储。有关更多信息,请参阅VLDB20论文:Delta Lake:云对象存储上的高性能ACID表存储。
此外,我们计划在书的最终版本中涵盖以下主题。
- 构建数据管道的一个关键部分是构建正确的平台和体系结构,因此我们将重点关注如何构建数据管道bob体育客户端下载三角洲湖奖章建筑(第七章)而且湖屋建筑(第八章)分别。
- 由于数据可靠性对所有数据工程和数据科学系统都至关重要,因此所有系统都可以访问该功能也很重要。因此在与三角洲湖的整合(第九章),我们将重点介绍Delta Lake如何与其他开源和专有系统集成,包括但不限于Presto、Athena等!
- 由于Delta Lake已投入生产多年,每天处理的数据超过1eb,因此本文将讨论大量的设计技巧和最佳实践使用Delta Lake的设计模式(第十章).
- 对于生产环境来说,为您的湖构建安全和治理的能力同样重要,这将在安全和治理(第11章)。
- 为了总结这本书,我们还将介绍一些重要的主题,包括性能和调优(第12章),迁徙至三角洲湖(第13章),三角洲湖案例研究(第十四章).
请务必查看一些相关内容,从2021年数据+人工智能峰会bob体育客户端下载平台——来自梦想家和思想领袖包括Bill Inmon:数据仓库之父,马拉拉Yousafzai:诺贝尔和平奖得主和教育倡导者,穆格加·库珀博士而且亚当Steltzner:著名的开拓性工程师NASA-JPL的火星探测器“毅力”任务,索尔Rashidi:雅诗兰黛的CAO,DJ帕蒂尔他在领英创造了“数据科学家”的头衔,迈克尔时常要他是Databricks的杰出软件工程师,马泰Zaharia: Databricks的联合创始人兼首席技术专家Apache火花而且MLflow而且阿里Ghodsi: Databricks首席执行官和联合创始人,以及其他特色演讲者。提高你的知识水平技术含量高,由知名专家主讲。
免费试用Databricks
相关的帖子