




Azure上的现代工业物联网分析-第2部分
在Azure上的现代工业物联网(IoT)分析系列的第1部分中,我们介绍了大数据…
2020年8月11日 在公司博客上
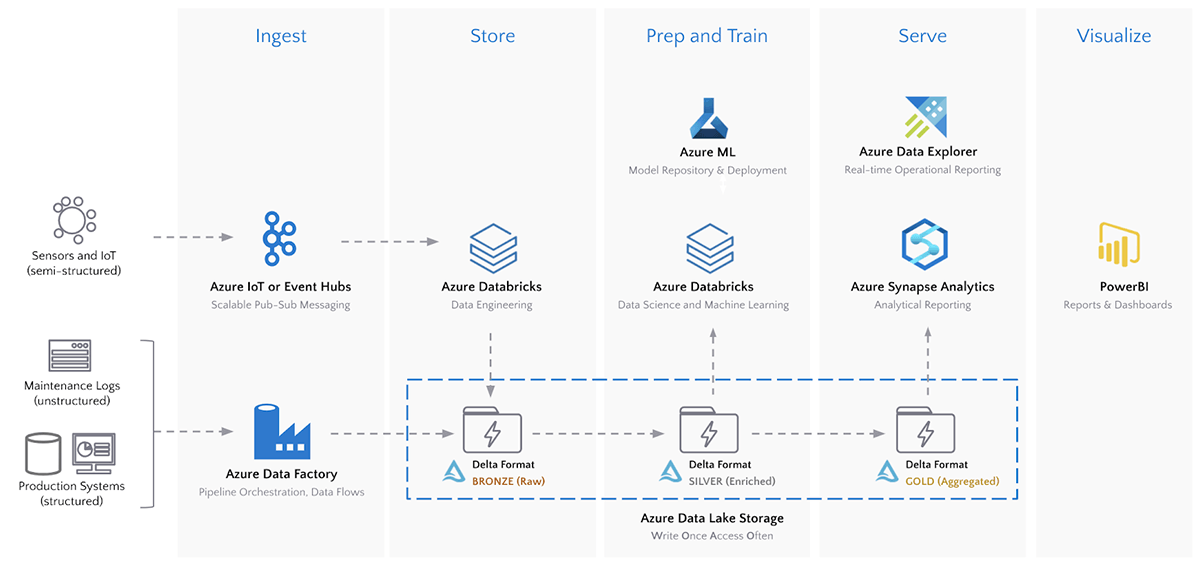
在第1部分在Azure上的现代工业物联网(IoT)分析系列中,我们介绍了大数据用例和现代工业物联网分析的目标,分享了组织用于大规模部署工业物联网的现实世界可重复架构,并探讨了Delta格式对于现代工业物联网分析所需的每个数据湖功能的好处。
我们使用Azure的树莓派物联网模拟器来模拟实时机器对机器传感器读数,并将其发送到Azure物联网中心。
我们的部署将天气传感器读数(风速和风向、温度、湿度)和风力涡轮机远程信息处理(角度和转速)发送到物联网云计算中心。Azure Databricks可以将来自物联网中心的数据直接流到ADLS上的Delta表中,并显示数据的输入与处理速率。
#使用Azure Databricks的eventubs库直接从物联网中心读取Iot_stream = (spark.readStream。格式(“eventhubs”)#直接从物联网中心读取.options (* * ehConf)#使用event - hub启用的连接字符串.load ()#加载数据.withColumn (“阅读”, F.from_json (F.col (“身体”) .cast (“字符串”),模式))#从消息中提取有效负载.select (“阅读。*”F.to_date (“reading.timestamp”) .alias (“日期”))#创建“date”字段用于分区)#将我们的物联网集线器流拆分为单独的流,并将它们都写入自己的Delta位置Write_turbine_to_delta = (iot_stream。过滤器('温度为空')#过滤涡轮遥测从其他流.select (“日期”,“时间戳”,“的deviceId”,“转”,“角”)#提取感兴趣的字段.writeStream。格式(“δ”)将流写入Delta格式.partitionBy (“日期”)#根据日期划分数据以提高性能.option (“checkpointLocation”, root_path +“/铜/ cp /涡轮”)#检查点,这样我们就可以优雅地重新启动流.start (ROOT_PATH +“/铜/数据/ turbine_raw”)#流数据到ADLS路径)达美允许我们的物联网数据在物联网中心捕获后几秒钟内查询。
%sql—当数据流到Delta时,我们可以立即从存储中直接查询数据选择*从delta.”/tmp/iiot/青铜/数据/turbine_raw”在哪里的deviceid=“WindTurbine-1”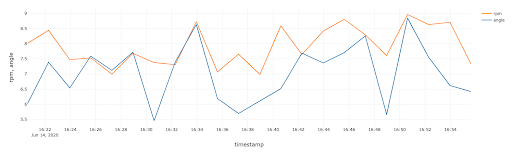
我们现在可以建立一个下游管道,丰富和汇总我们的工业物联网应用数据,用于数据分析。
Delta支持数据工程的多跳管道方法,其中数据质量和聚合随着数据流通过管道而提高。我们的时间序列数据将流经以下铜、银和金数据级别。
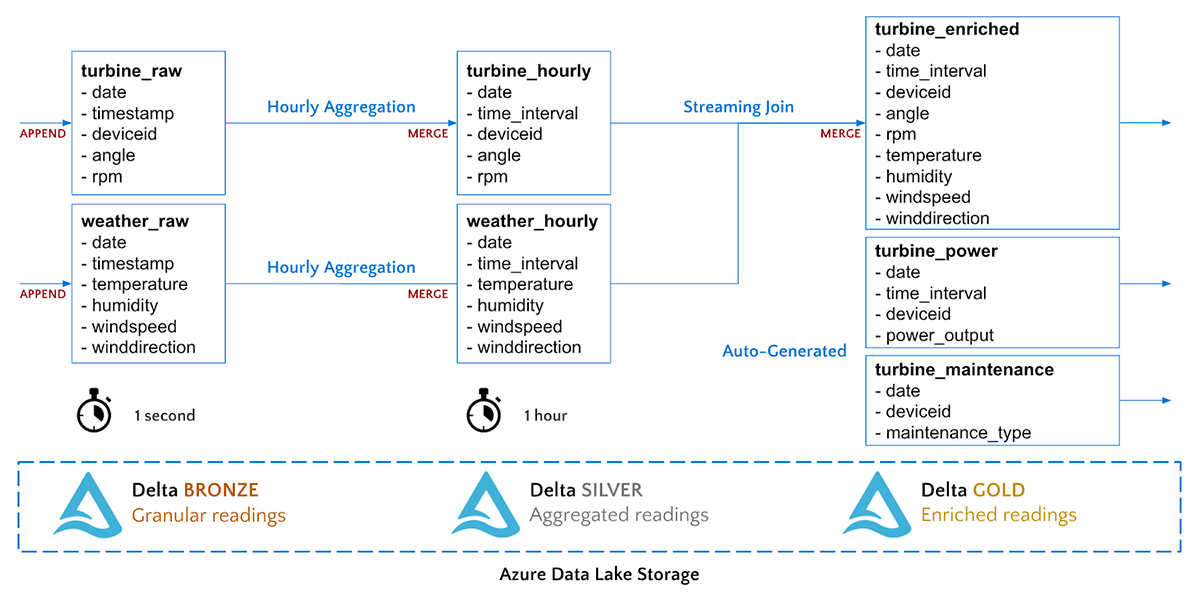
我们从青铜到白银的管道将简单地聚合我们的涡轮传感器数据到1小时间隔。我们将执行一个流MERGE命令,将聚合的记录插入到Silver Delta表中。
#创建功能来合并涡轮而且天气数据成它们的目标Delta表Def merge_records(incremental, target_path):incremental.createOrReplaceTempView(“增量”)#合并由的一个目标表格,来源表格(增量),#一个加入关键来识别匹配(的deviceid time_interval),而且操作来执行#(更新,插入,删除)当一个匹配发生或不incremental._jdf.sparkSession()。sql(f”“”MERGE INTO turbine_hourt使用增量ii.date = t。AND i.deviceId = t.deviceid AND i.time_interval = t.time_interval当匹配时,更新集合*如果不匹配,则插入*”“”)
#执行流合并成我们的数据流turbine_stream=(spark.readStream.format (“δ”).表格(“turbine_raw”#读取数据作为一个流从源表格.groupBy (“的deviceId”,“日期”F.window (“时间戳”,“1小时”)) #综合读数来每小时间隔.agg({“rpm”:“avg”、“角”:“avg”}).writeStream.foreachBatch(merge_records) #通过每一个微-批处理来一个函数.outputMode(“更新”)#合并作品与更新模.开始())我们的从银到金的管道将把两个流连接在一起,形成一个单表,用于每小时的天气和涡轮机测量。
#从Delta Silver表读取流turbine_hour = spark.readStream。格式(“δ”) .option (“ignoreChanges”,真正的) .table (“turbine_hourly”)weather_hour = spark.readStream。格式(“δ”) .option (“ignoreChanges”,真正的) .table (“weather_hourly”)#执行流连接来丰富数据turbine_enrichment = turbine_hours。加入(weather_hourly [“日期”,“time_interval”])#执行流合并到我们的黄金数据流Merge_gold_stream = (turbine_enriched.writeStream.foreachBatch (merge_records).start ())我们可以立即查询我们的Gold Delta表。

笔记本还包含一个单元,它将生成历史每小时功率读数和每日维护日志,用于模型训练。运行该单元格将:
我们现在在Azure数据湖上以高性能、可靠的格式拥有丰富的、人工智能(AI)就绪数据,这些数据可以输入到我们的数据科学建模中,以优化资产利用。
%sql——同时查询所有3个表创建或取代视图gold_readings作为选择r。*,p.power,m.maintenance作为维护从turbine_enriched r加入turbine_power p在(r.date=p.date和r.time_interval=p.time_interval和r.deviceid=p.deviceid)左加入turbine_maintenance米在(r.date=m.date和r.deviceid=m.deviceid);选择*从gold_readings
我们的数据工程管道完成了!数据现在从物联网中心流向青铜(原始)到白银(聚合)再到黄金(浓缩)。是时候对我们的数据进行一些分析了。
综上所述,我们成功地:
他们把一切联系在一起的关键技术是三角洲湖。ADLS上的Delta提供可靠的流数据管道和对大量时间序列数据的高性能数据科学和分析查询。最后,它通过将最好的Azure工具引入一次编写、经常访问的数据存储,使组织能够真正采用Lakehouse模式。
在下一篇文章中,我们将探索使用机器学习来最大化风力涡轮机的收入,同时最小化停机的机会成本。
试试笔记本托管在这里,了BOB低频彩解有关Azure Databricks的更多信息三部分培训系列并了解如何在Azure上创建现代数据架构这个网络研讨会.