



使用数据库池加速数据管道和快速扩展集群
数据工程团队在Databricks上部署简短的自动化作业。他们希望集群能够快速启动、执行作业并终止。数据分析……
数据工程团队部署短,自动工作在砖上。他们希望集群能够快速启动、执行作业并终止。数据分析团队运行大型自动伸缩,交互式集群在砖上。他们希望这些集群能够适应增加的负载并快速扩展,以最大限度地减少查询延迟。数据库很高兴地宣布砖池,一个托管的虚拟机实例缓存,使集群启动和扩展速度快4倍。
如果没有池,Databricks将根据请求从云提供商获得虚拟机(VM)实例。这很划算,但速度慢。没有空闲的虚拟机实例需要支付,但是对于每个集群创建和自动伸缩事件,Databricks必须从云中请求虚拟机并等待它们初始化。下图显示了数据工程作业集群和交互式数据分析集群的典型生命周期。
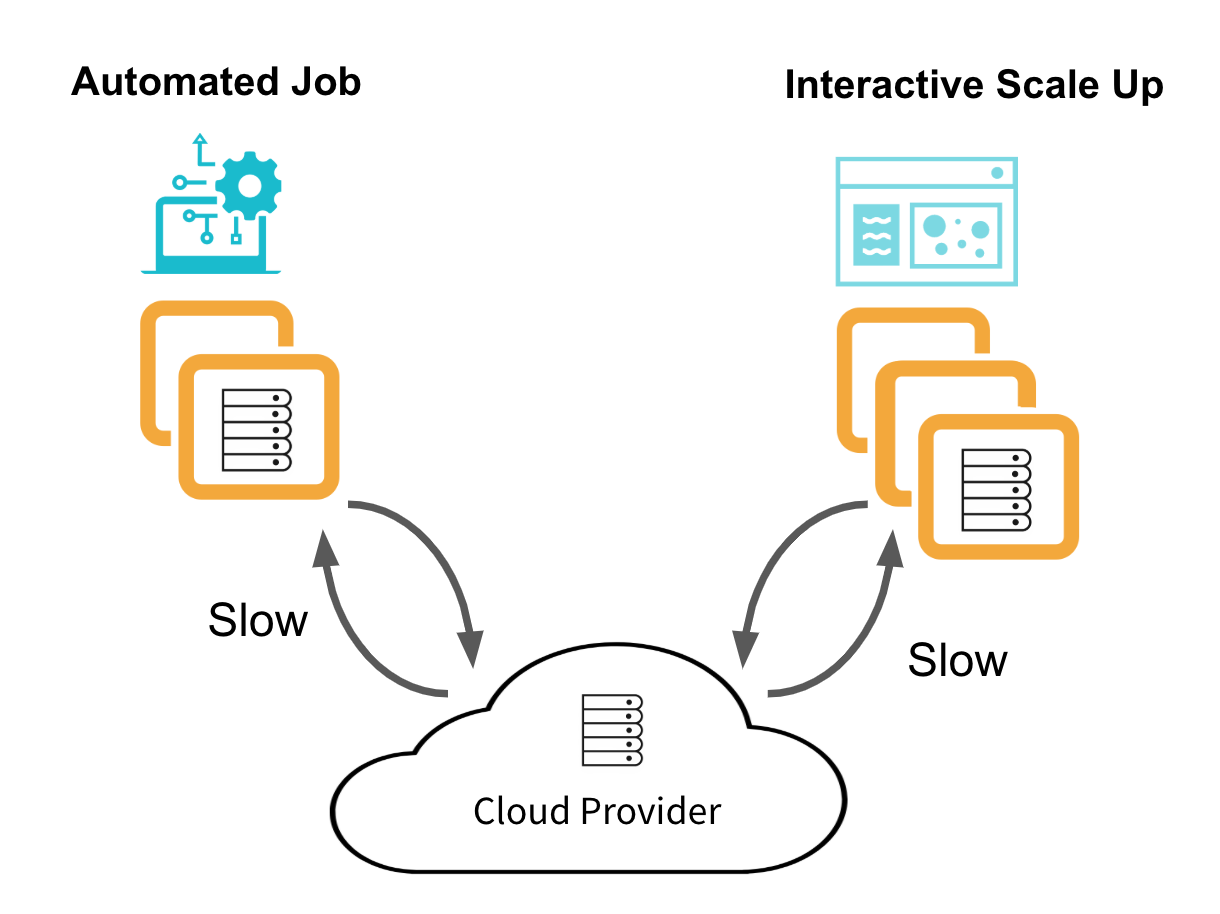
这对于运行短期作业的数据工程师来说是不够的。集群开始时间可以支配作业的总执行时间。这对数据分析师来说也不够。在运行大型查询时,等待集群扩展会降低工作效率。
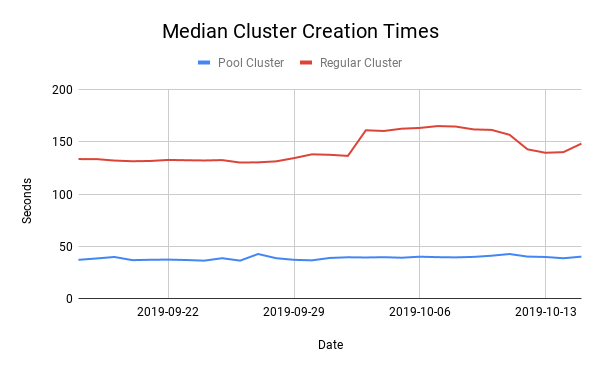
下图显示了Databricks集群的中位数开始时间。如果没有池(红色部分),每个集群创建请求都必须从云中获取新的虚拟机,在这些虚拟机上初始化守护进程服务,然后下载砖运行时(DBR)给他们。这些步骤导致集群创建时间的中值为145秒。那是两分半钟!使用池(蓝色部分),集群创建将跳过这些步骤,耗时不到40秒。集群自动伸缩也跳过了这些步骤,提供了类似的性能提升。
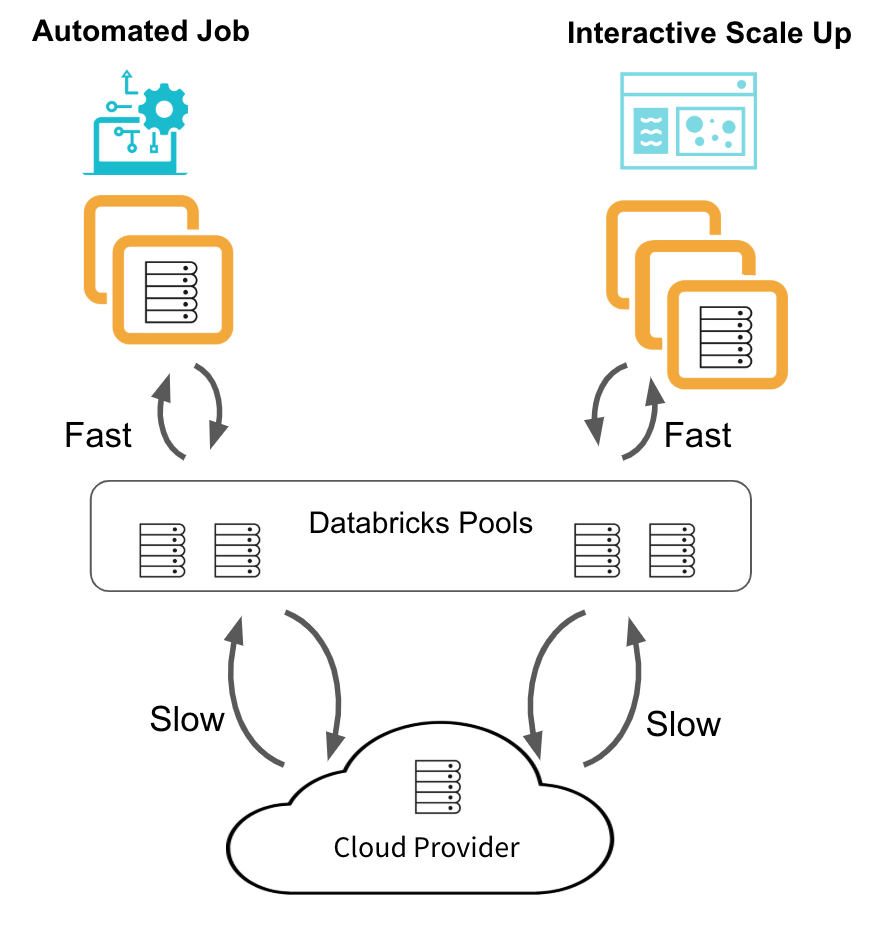
Databricks引入了池,虚拟机实例的托管缓存,以实现集群启动和自动伸缩时间从几分钟到几秒的减少,
当连接到某个池的集群需要虚拟机实例时,它会检查池,而不是向云提供商请求新实例。如果池中有足够的空闲实例,集群将获取它们并快速启动或扩展。如果没有足够的空闲实例,则通过从云提供程序分配新实例来扩展池,以满足集群的请求。这将降低请求的速度,因此在池中维护足够的空闲实例非常重要。当一个池集群释放实例时,它们将返回到池中,供其他集群使用。只有附加到池的集群才能使用该池的空闲实例。
下图显示了使用Databricks Pools的数据工程作业集群和交互式数据分析集群的典型生命周期。
将空闲的虚拟机实例保存在Databricks池中对性能有好处,但不是免费的。Databricks不向Databricks集群不使用的空闲实例收取DBUs费用,但云提供商的基础设施成本确实适用。
有一些建议的方法来管理这个成本。首先,手动编辑池的大小以满足您的需求。如果您只在工作时间运行交互式工作负载,请确保池的“最小空闲”实例计数在工作时间之后设置为零。或者,如果您的自动化数据管道在夜间运行了几个小时,那么在管道启动前几分钟设置“最小空闲”计数,然后将其恢复为零。或者,始终保持“最小空闲”为零,但设置“空闲实例自动终止”超时以满足您的需要。池上运行的第一个作业将缓慢启动,但在超时时间内运行的后续作业将快速启动。作业完成后,池中的所有实例都将在空闲超时后终止,从而避免了云提供商的成本。
您也可以通过设置虚拟机池的最大容量来预算虚拟机资源。这限制了连接到池的集群使用的所有空闲实例和实例的总和。
开始使用Databricks Pools很容易。单击群集图标![]() 在侧边栏中,选择pools选项卡并单击“Create Pool”按钮。
在侧边栏中,选择pools选项卡并单击“Create Pool”按钮。
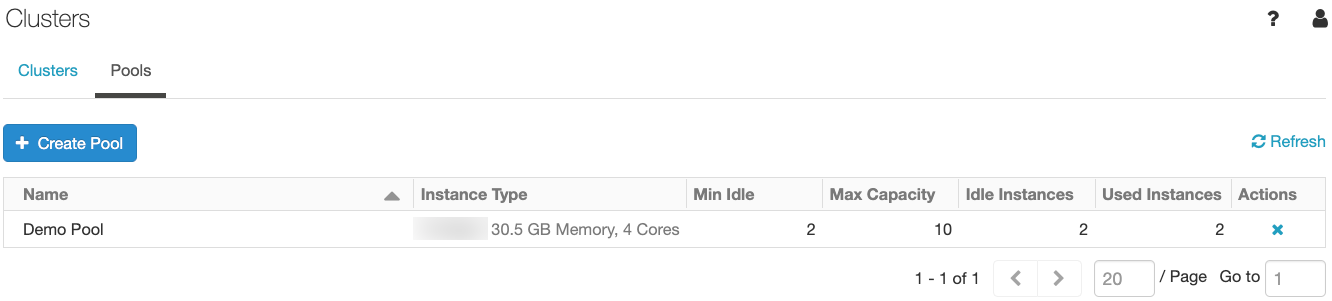
在你创建在池中,您可以看到集群正在使用的实例的数量,空闲且准备使用的实例数量,以及挂起的实例数量(即空闲但尚未准备好)。

为了使用池中的空闲实例,请从集群创建模板中的下拉菜单中选择池。这既适用于交互式集群,也适用于自动化作业集群。选择池后,集群将为驱动程序和工作节点使用池的实例类型。
假设池中有足够的空闲实例(在池创建过程中通过“Min idle”字段设置),集群将在40秒内启动。在集群运行时,池将回填更多空闲实例,以保持空闲实例的最小数量。一旦集群使用完实例,它们将返回到池中供下一个集群使用。超过最小空闲数的空闲实例在“空闲实例自动终止”超时时间(默认为60分钟)内处于空闲状态后将被终止。
Databricks Pools提高了数据工程师和数据分析师的工作效率。通过使用池,Databricks客户消除了缓慢的集群启动和自动伸缩时间。数据工程师可以减少在数据管道中运行短作业所需的时间,从而为下游团队提供更好的sla。数据分析团队可以更快地向外扩展集群,以减少查询执行时间,提高下游报告的近时性。池允许团队快速迭代和创新,并使他们更接近实时分析。所有这些都是可能的,同时降低了Databricks的许可成本,使得该特性的部署变得简单。
要了解如何部署该特性,请在这里阅读Databricks Pools文档。如果你还没有Databricks,开始一个试验在这里并使用快速入门指南在这里。
相关资源
https://docs.www.neidfyre.com/clusters/instance-pools/index.html
//www.neidfyre.com/glossary/what-is-databricks-runtime