
扩大金融时间序列分析超越pc和熊猫:按需网络研讨会,幻灯片和常见问题现在可用!


2019年10月18日 在工程的博客
2019年10月9日,我们举办了一场网络直播研讨会超越个人电脑和熊猫的金融时间序列分析-与Databricks的行业金融服务领导者军政府Nakai和Databricks的解决方案架构师Ricardo Portilla合作。这是一个现场网络研讨会展示的内容在这个博客-数字化金融时间序列分析。
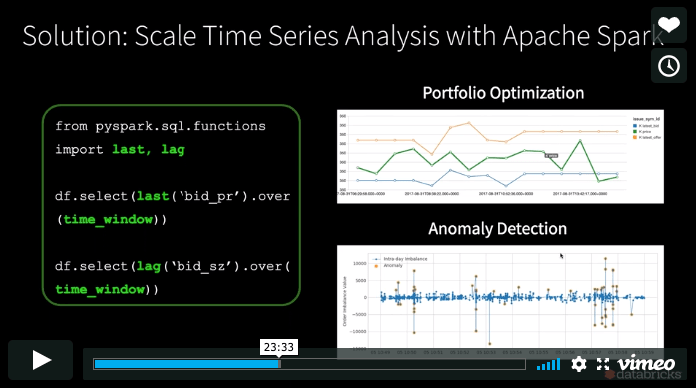
请参阅这里是本次网络研讨会的幻灯片.
基本经济数据、金融股tick数据和替代数据诸如地理空间或事务数据的集合都是按时间进行索引的,通常以不规则的间隔进行索引。解决投资风险、欺诈、交易成本分析和合规等金融业务问题,最终取决于能够并行分析数百万个时间序列。基于rdbms的旧技术在分析交易策略或对多年历史数据进行监管分析时不容易扩展。
在本次网络研讨会中,我们回顾了:
- 如何使用Apache Spark™在数十万个计时器上并行构建时间序列函数。
- 最后,如果你是一个Pandas (Python数据分析库)用户希望将规模数据准备提供给金融异常检测或其他统计分析,我们使用了一个市场操纵的例子来展示Koalas如何使规模对典型的数据科学工作流程透明。
我们使用 这本笔记本在数据库里
如果你想免费访问统一数据分析平台bob体育客户端下载试试我们的笔记本,你可以访问免费试用.
最后,我们进行了问答环节,以下是问答环节。
问:BI工具传统上查询数据仓库,现在它们可以连接到Databricks吗?
A:问得好。有两种方法。是的,您可以将BI工具直接连接到Databricks来查询数据湖。让我们看看下面这张幻灯片。
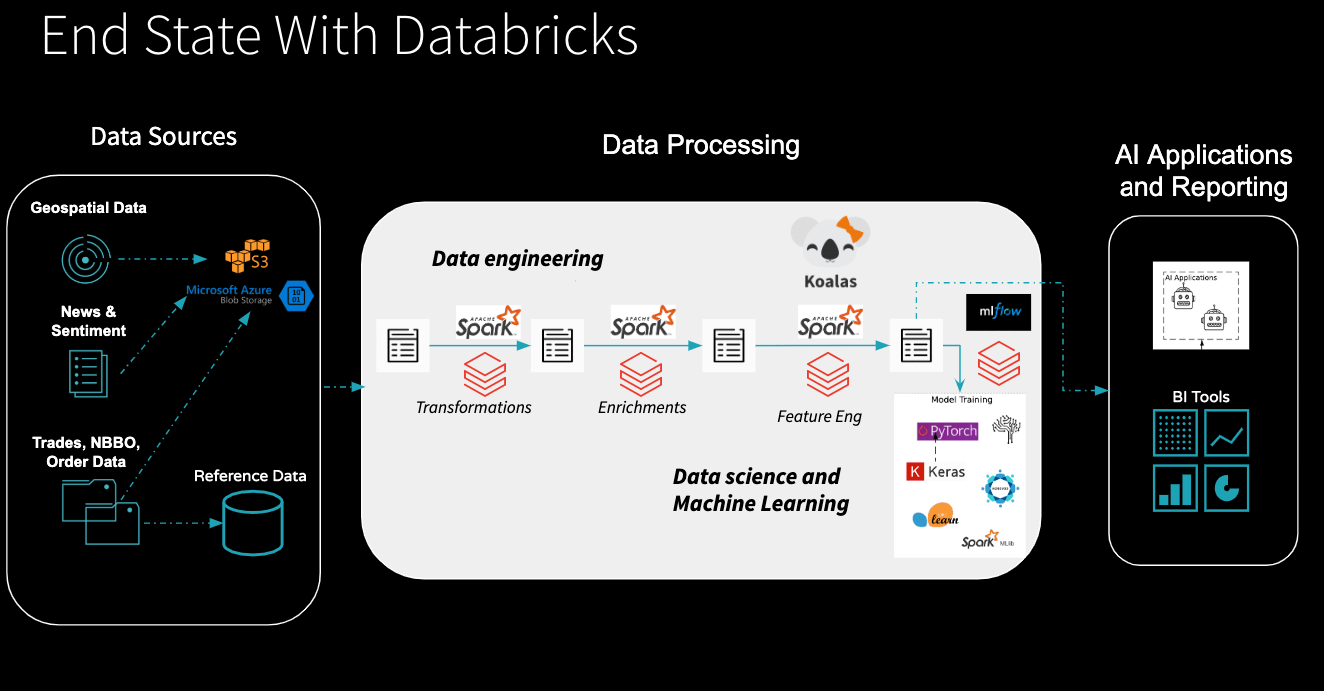
如果查看图表,BI工具指向Apache Spark创建的一个托管表。如果您有一个特定于某一行业务的聚合表(假设您创建了一个包含全天聚合交易窗口的表),则可以使用BI工具(如Tableau、Looker等)进行查询。如果您需要非常低的延迟,例如,您需要为c级创建仪表板,那么您可以查询数据仓库。
Q:有没有一种方法可以有效地分布时间序列的建模,或者这只是分布式的基于熊猫的数据操作来准备数据集。具体来说,我用了相当多的SARIMAX。我正在试图弄清楚如何分配候选SARIMAX模型的交叉验证。
答:这个演示更侧重于操作方面,但Spark绝对可以分发超参数调优和交叉验证等内容。如果你定义了一个网格或者你想做一个随机贝叶斯搜索,你需要做的是,定义独立的问题或者划分你的问题。一个很好的例子就是预测。假设,我想迭代100个不同的组合,我想改变我们是指定每日季节性还是每年季节性,然后乘以我在ARIMA模型中使用的所有不同的参数。然后我需要做的就是定义网格,Spark基本上可以为每个不同的输入向量参数执行一个任务。所以实际上你可以同时进行1000到5000个预测。这将是并行化预测等事情的首选方法。
问:Koala是开源的吗bob下载地址?考拉和你一起工作吗scikit-learn?
是的,考拉是开源软件。考拉绝对适合scikit-learn.如果你看一下笔记本博客在这里,您可以有效地转换这些数据结构中的任何一个,并可以直接将其提供给scikit-learn。唯一的区别是,在你把它转换成机器学习模型之前,你可能必须直接转换结构。也就是说,你可能必须在最后一步转换成熊猫。但它应该在其他方面起作用。这两个numpy数据结构充当桥接。
问:作为一个团队,如果我们在Databricks工作,我们如何进行代码审查或版本控制?
这篇博客文章实际上指出了这样做的机制。如果你想在性能、计算、MLFlow等方面利用Databricks。我们发布了Databricks Connect。它允许您在本地IDE上工作。如果您这样做了,您就可以使用标准工具将代码检入到版本控制中,然后像往常一样使用Jenkins进行部署。第二个选择是Databricks笔记本本身与Git集成,因此您可以直接将工作保存在笔记本中。
问:有没有资源、演示、教程来处理面向地理空间的时间序列数据?例如,可以查看过去5年的房地产数据,并将其与交通数据结合起来,以显示住房密度如何影响交通模式。
答:这里强调的技术是多用途的。对于AS-OF连接,您当然可以使用所描述的数据集。这只是调整正确的时间戳,然后选择一个分区列的问题。我们将特别考虑后续关于地理空间的博客,可能会更深入地讨论可用于有效连接地理空间数据的技术或库。但是现在as - of连接应该适用于您想要使用的任何数据集,只要您只是试图合并它们以获得上下文as - of数据。