


使用AWS DMS将事务性数据迁移到Delta Lake
2019年7月15日
通过阿伦Pamulapati
在
公司博客上
注意:我们还建议您阅读高效Upserts into Data Lakes with Databricks Delta,其中解释了使用…
2019年7月15日 在公司博客上
注:我们也建议你阅读高效Upserts到数据湖与Databricks Delta这解释了使用MERGE命令来执行高效的upsert和delete。
大型企业正在将事务数据从分散的异构位置的数据集市转移到集中的数据集市数据湖.业务数据越来越多地被整合到数据湖中,以消除竖井,获得洞察力并构建人工智能数据产品。然而,从各种不断变化的事务数据库构建数据湖并保持数据湖的更新是极其复杂的,可能是操作上的噩梦。
使用特定于供应商的CDC工具或Apache Spark的传统解决方案TM直接的JDBC摄取在典型的客户场景中是不实际的,如下所示:
(a)数据源通常分布在预置服务器和云中,包括来自PostgreSQL、Oracle和MySQL数据库的数十个数据源和数千个表
(b)数据湖中捕获的变更数据的业务SLA在15分钟内
(c)数据具有不同的所有权程度和数据库连接的网络拓扑结构。
在上述场景中,使用Delta lake和AWS数据库迁移服务(DMS)构建数据湖来迁移历史和实时事务数据被证明是一种出色的解决方案。本文介绍了使用AWS数据库迁移服务(AWS DMS)构建可靠数据湖的另一个简单过程三角洲湖,从多个RDBMS数据源中获取数据。然后你就可以使用数据库了bob体育亚洲版统一分析平台bob体育客户端下载对实时和历史数据进行高级分析。
Delta Lake是一个开源存储bob下载地址层,为数据湖带来可靠性。Delta Lake提供ACID事务,可扩展的元数据处理,并统一流和批处理数据。Delta Lake运行在您现有的数据湖之上,并且完全兼容Apache Spark api。
具体来说,Delta Lake提供:
AWS DMS可以将您的数据从最广泛使用的商业和开源数据库迁移到S3,用于迁移现有数据和更改数据。该服务支持从不同的数据库平台迁移,如Oracle到Amazon Aurora或Microsoft SQL Serbob体育客户端下载ver到MySQL。使用AWS数据库迁移服务,您可以持续地以高可用性复制数据,并通过将数据从任何数据库流到Amazon S3来合并数据库支持来源.
假设您有一个建立在MySQL数据库上的“person”表,该表包含应用程序用户记录的数据,列如下所示。每当一个人移动,该表就会更新,一个新的人被添加,一个现有的人可能被删除。我们将使用AWS DMS将这个表吸收到S3中,然后使用Delta Lake加载它,以展示摄取数据湖并使其与事务数据存储保持同步的示例。我们将在MySQL中演示对该表的更改数据捕获,并使用AWS DMS将更改复制到S3中,并轻松地合并到使用Delta lake构建的数据湖中。

在这个解决方案中,我们将使用DMS将数据源引入Amazon S3,以进行初始摄取和持续更新。我们将S3中的初始数据加载到Delta Lake表中,然后使用Delta Lake的upserts功能将更改捕获到Delta Lake表中。我们将在Delta Lake表上运行与原始来源同步的分析,以获得业务见解。建议的解决方案如下图所示:

在Delta Lake上的数据可用后,您可以轻松使用仪表板或BI工具生成智能报告以获得见解。您还可以更进一步,使用Databricks使用这些数据构建ML模型。
出于本文的目的,我们使用MySQL引擎创建一个RDS数据库,然后加载一些数据。在现实生活中,可能有多个源数据库;这篇文章中描述的过程仍然类似。
按照下面的步骤操作教程:创建一个Web服务器和亚马逊RDS数据库创建源数据库。使用主教程页面上的链接了解如何连接到特定的数据库并加载数据。有关更多信息,请参见:创建DB实例运行MySQL数据库引擎
记录您创建的安全组,并将所有RDS实例与其关联。称其为“TestRDSSecurityGroup”。之后,您应该能够看到RDS Instances仪表板中列出的数据库。

设置两个S3桶,如下所示,一个用于批量初始加载,另一个用于增量变更数据捕获。
在下一步中,选择“用于非生产用途的公共可访问”,以保持配置简单。此外,为了简单起见,选择您放置RDS实例的同一个VPC,并将TestRDSSecurityGroup包含在允许访问的安全组列表中。
方法中所示,可以轻松设置DMSAWS数据库迁移服务博客文章。你可以采取以下循序渐进的方法:
在DMS控制台中,选择端点,创建端点。您需要配置代表MySQL RDS数据库的端点。您还需要通过提供在前面步骤中创建的S3桶来创建目标端点。配置后,端点看起来类似于下面的截图:
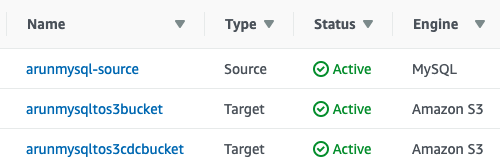
您可以依赖DMS来迁移目标Amazon S3桶中的表
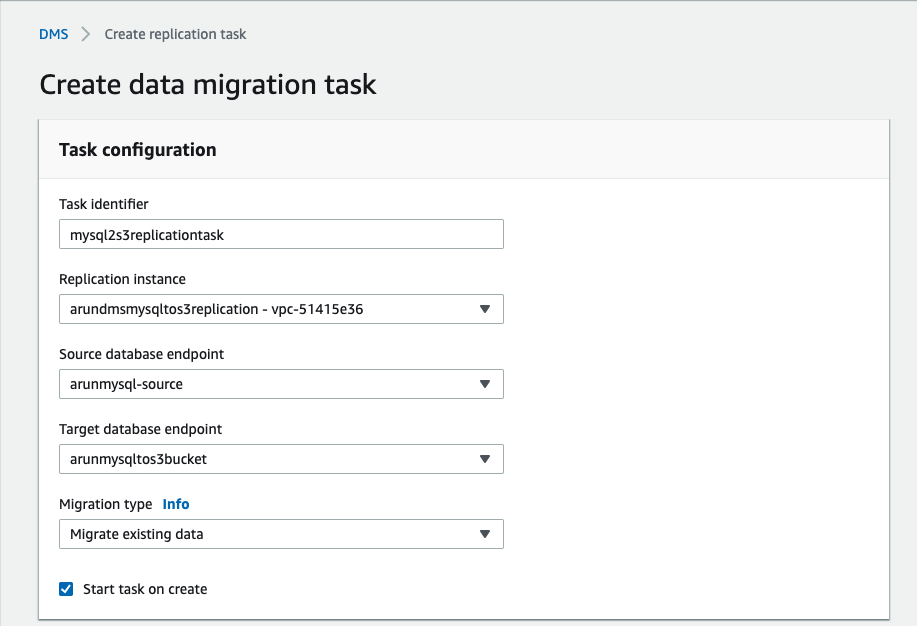
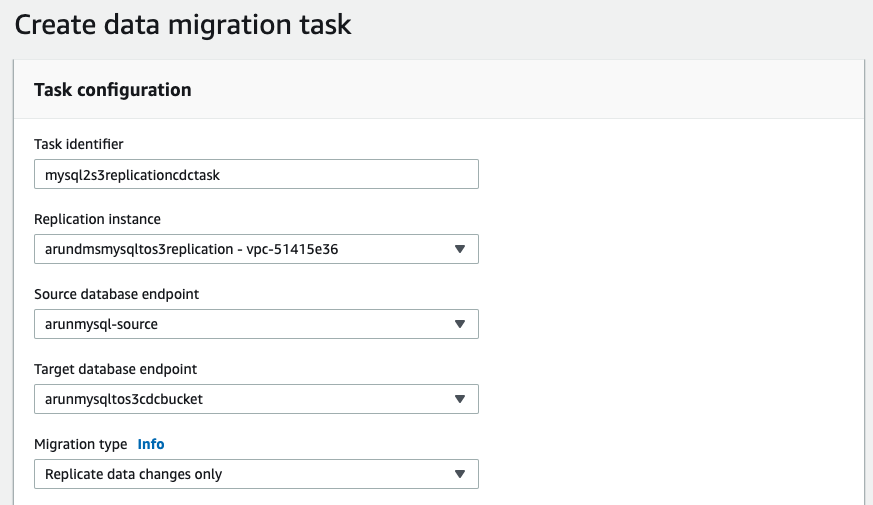
在DMS控制台中,选择“任务”,“创建任务”。填写如下截图所示字段:
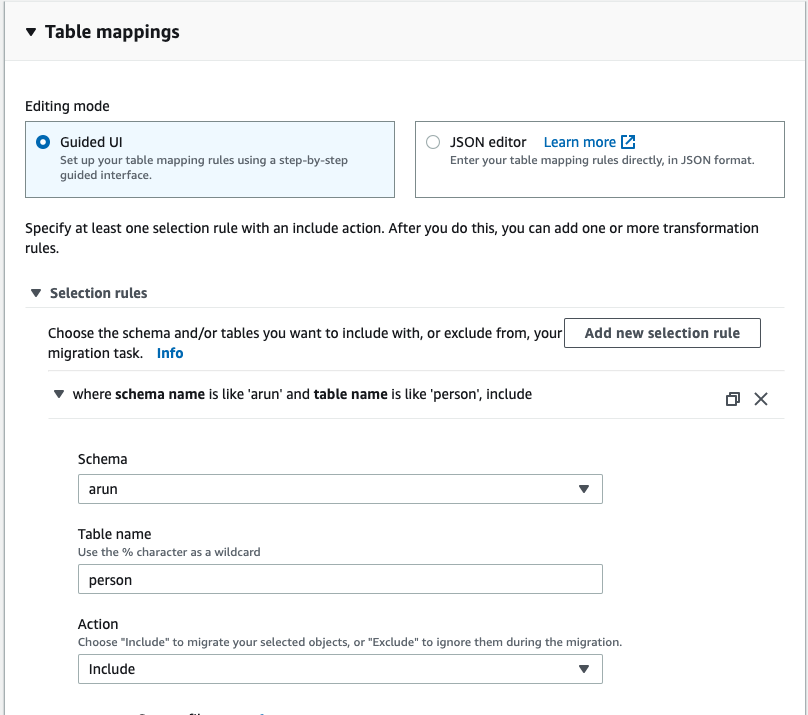
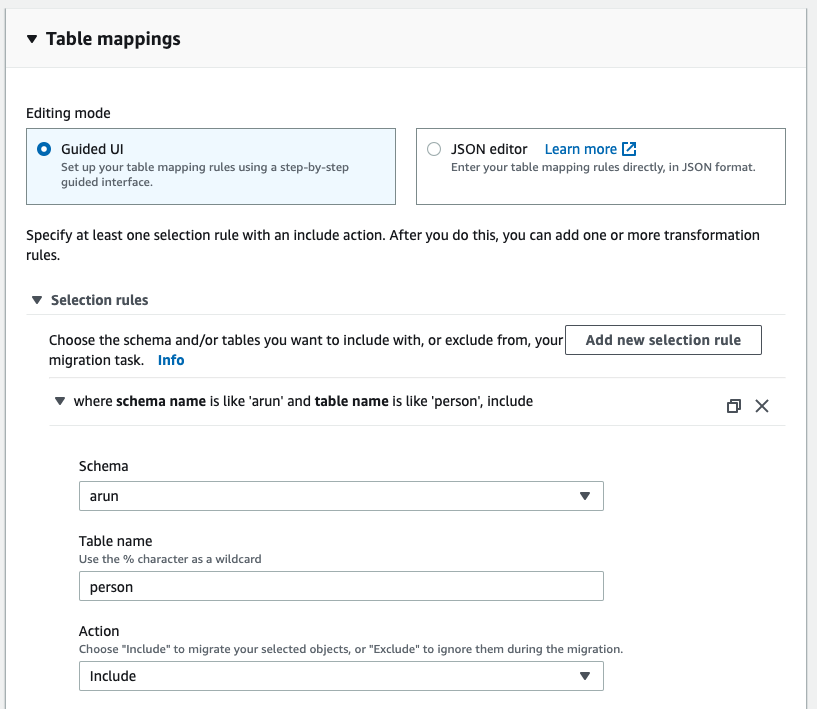
注意,如果源是RDS MySQL,并且您选择迁移数据并复制正在进行的更改,那么您需要启用bin日志保留。其他引擎有其他要求,DMS会相应地提示您。对于这种特殊情况,执行以下命令:
叫mysql。Rds_set_configuration ('binlog保留小时',24);
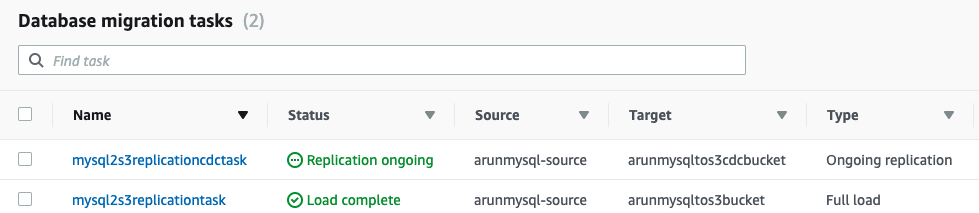
在两个任务都成功完成后,tasks选项卡现在看起来如下所示:
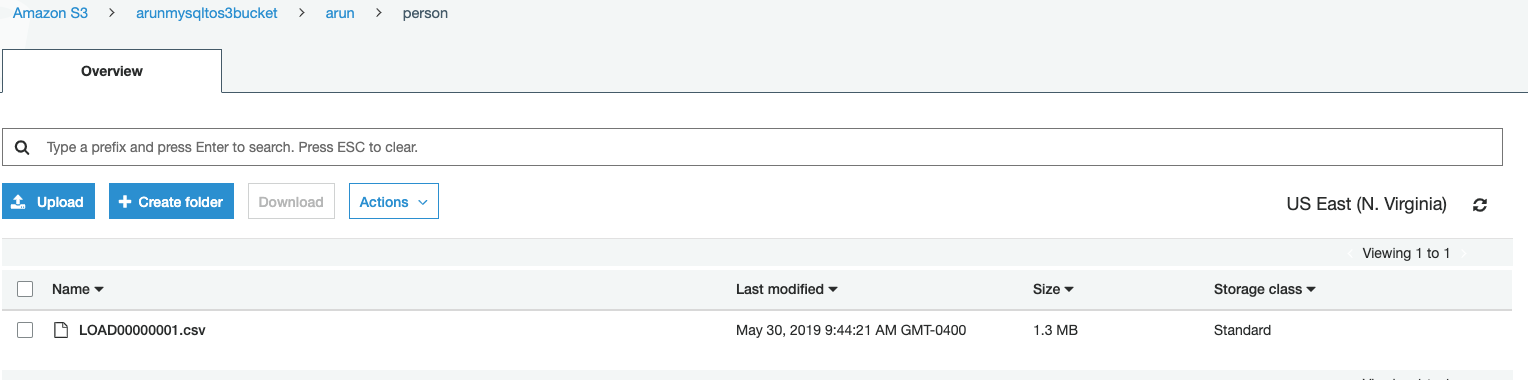
示例行:
 2.对源数据库中的person表进行一些更改,并注意这些更改已迁移到S3
2.对源数据库中的person表进行一些更改,并注意这些更改已迁移到S3INSERT into person(id,first_name,last_name,email,性别,dob,地址,城市,州)values ('1001','Arun','Pamulapati','(电子邮件保护)','Female','1959-05-03','4604 Delaware Junction','Gastonia','NC');UPDATE person set state = 'MD' where id=1000删除id = 998的person;UPDATE person set state = 'CA' where id=1000;

我们会的创建Delta Lake表从初始加载文件开始,您可以使用Spark SQL代码并将格式从parquet、csv、json等更改为delta。对于所有的文件类型,你把文件读入一个DataFrame,然后用delta格式写出来:
personDF = spark.read.option("Header",True).option("InferSchema",True).csv("/mnt/%s/arun/person/" % initialoadMountName) personDF.write.format("delta").save("/delta/person")sql("CREATE TABLE person USING DELTA LOCATION '/ DELTA /person/'")
我们将使用Delta合并为能力捕捉到三角洲湖的变更记录
personChangesDF = (spark.read.csv("dbfs:/mnt/%s/arun/person" % changesMountName, inferSchema=True, header=True, ignoreLeadingWhiteSpace=True, ignoreTrailingWhiteSpace=True))id,first_name,last_name,email,性别,dob,地址,城市,州,create_date,last_update FROM person_changes latest_changes INNER JOIN (SELECT id, max(last_update) AS MaxDate FROM person_changes GROUP BY id) cm ON latest_changes。Id = cm。id和latest_changes。last_update = cm.MaxDate)作为源Id == target。匹配时的id和源。Op = 'D'然后删除匹配时,然后更新集合*当不匹配时,然后插入*

注意:
1)你可以使用数据库工作功能来调度CDC合并基于您的sla,并将更改日志从CDC S3桶移动到存档桶后,成功合并,以保持您的合并有效负载为最新的和小的。Databricks平台中的作业是一种立bob体育客户端下载即或定期运行笔记本或JAR的方式。您可以使用UI、CLI和调用jobs API来创建和运行作业。类似地,您可以在UI中监视作业运行结果、使用CLI、查询API和通过电子邮件警报。
2)对于性能较好的初始负载较大的表首选利用Spark本地并行使用JDBC读取或使用DMS最好实践最有效地使用AWS数据库迁移服务(AWS DMS)。
在这篇文章中,我们展示了如何使用Delta Lake从RDBMS数据源中摄取和增量捕获更改,使用AWS DMS以简单的配置和最少的代码构建简单、可靠和经济的数据湖。您还使用Databricks笔记本在数据集上创建数据可视化,以提供额外的见解。