
大规模建设最快的DNASeq管道


2018年9月10日 在工程的博客
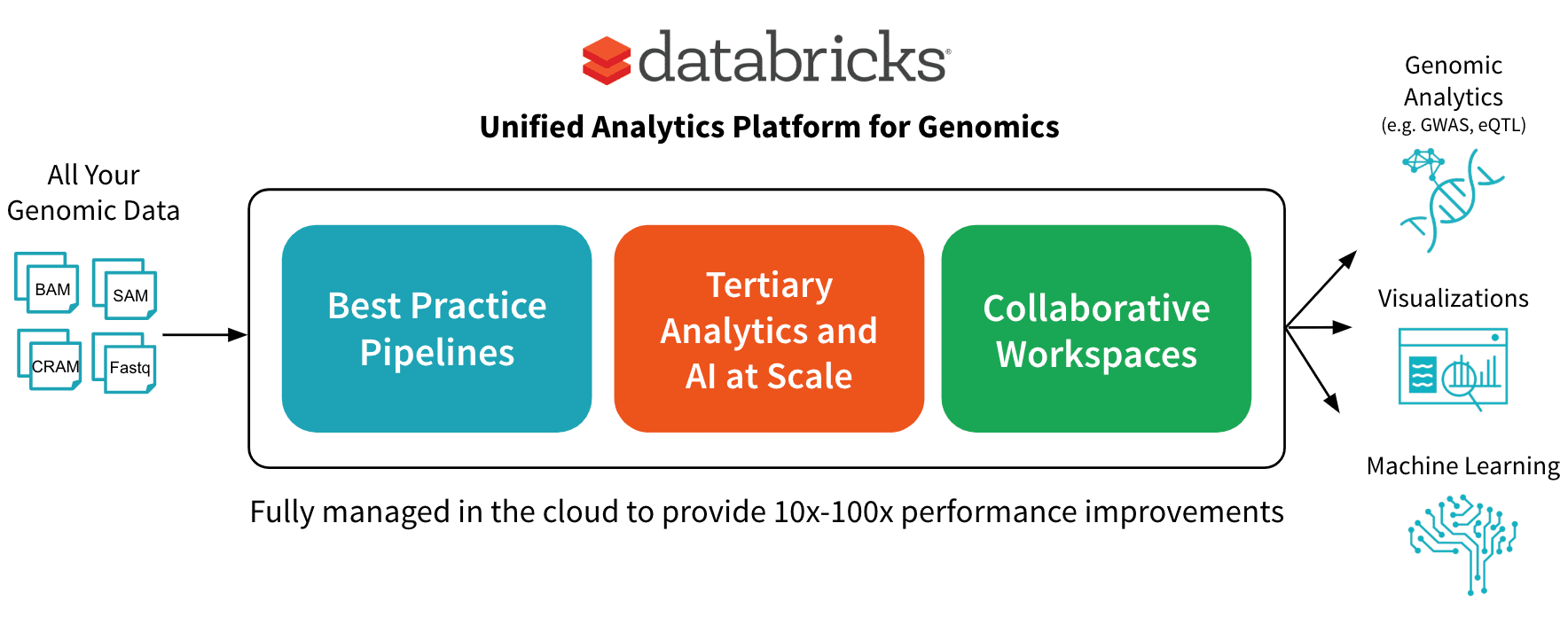
今年6月,我们宣布了bob体育亚洲版统一为基因组学分析平台bob体育客户端下载用一个简单的目标:加快发现协作互动基因组数据处理平台,在大规模分析和人工智能。bob体育客户端下载在这篇文章中,我们将详细的一个组件平台:一个可伸缩的DNASeq管道与GATK4整合速度一流。bob体育客户端下载
进行大规模的序列数据
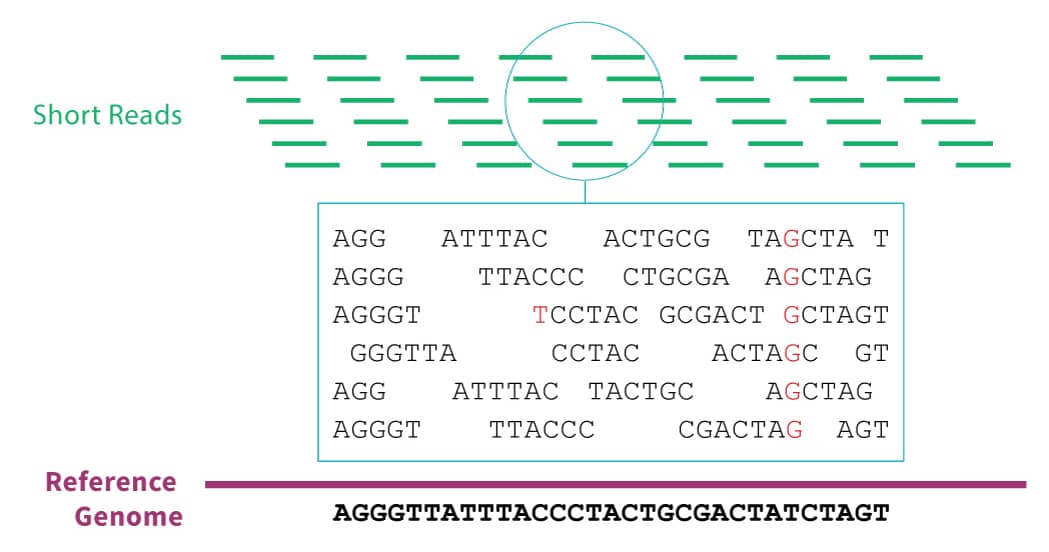
绝大多数的基因组数据来源大规模并行测序技术。在这种技术中,样本的DNA必须先切成短段长度约100个碱基对。定序器将发出每一部分的基因序列。为了正确排序错误,我们通常要求每个位置的基因组是由至少30段。以来在人类基因组中约有30亿个碱基对,这意味着测序后,我们必须重新组装30亿/ 100 * 30 = 9亿短读之前我们就可以开始真正的分析。这是一个不小的努力。
因为这个过程是常见的任何人使用DNA数据,编写一个良好的方法是很重要的。GATK团队广泛研究所领导的方式描述最佳实践用于处理DNASeq数据,很多人今天GATK本身或GATK-compliant管道运行。
在高级别上,这个管道由3个步骤组成:
- 每个短阅读参考基因组对齐
- 统计技术应用于区域与一些变体读来确定一个真正的可能性变化的参考
- 注释基因变体网站等信息,如果有的话,它的影响
挑战处理DNASeq数据
虽然DNASeq管道组件的特点,我们发现,我们的许多客户面对共同挑战扩展他们的管道不断增长的数据。这些挑战包括:
- 基础设施管理:许多我们的客户运行这些管道内部的高性能计算(HPC)集群。然而,HPC集群不是弹性——你不能根据需求迅速增加。在最好的情况下,增加数据量导致长队列的请求,因此漫长的等待时间。在最坏的情况下,客户纠结于昂贵的停机,影响效率。甚至在公司他们的工作负载迁移到云中,人们花尽可能多的时间写配置文件进行价值分析。
- 数据组织:Bioinformaticians习惯于处理多种文件格式,如BAM, FASTQ, VCF。然而,随着样本的数量达到某一阈值时,管理个人文件变得不可行。规模分析,人们需要简单抽象来组织他们的数据。
- 性能:每个人都关心他们的管道的性能。传统上,每个基因组的价格吸引最考虑,尽管临床用例成熟,速度是越来越重要。
当我们看到这些挑战重复在不同的组织中,我们认识到一个机会来利用我们的经验与原始创造者Apache的火花TM领先的引擎对于大型数据处理和机器学习,和砖平台,帮助我们的客户DNASeq管道在运行速度和规模不创建操作头痛。bob体育客户端下载
我们的解决方案
我们已经建立了第一个可用的horizontally-scalable管道与GATK4整合最佳实践。我们使用火花有效切分每个样本的输入数据并将其传递给单一节点等工具BWA-MEM对校准和GATK HaplotypeCaller变体。我们的管道运行数据砖工作,所以平台处理基础设施供应和配置无需用户干预。bob体育客户端下载
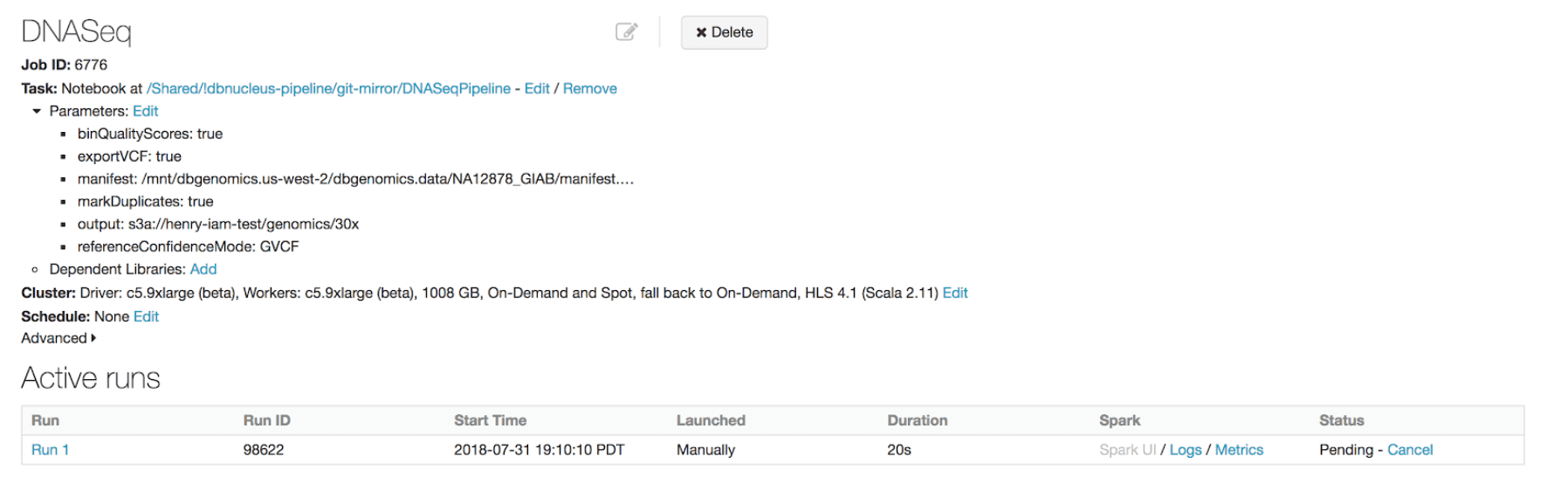
随着新数据到达时,用户可以利用我们的REST api和砖CLI启动一个新的运行。
当然,这个管道只是第一步获得生物见解从基因组数据。简化下游分析,除了输出VCF文件等熟悉的格式,我们写出对齐的读取,称为变体,高性能的带注释的变体砖三角洲湖拼花表。以来所有样本的数据可以在一个单一的逻辑表,它是简单的扭转和加入对有趣的遗传变异的来源,如医学图像和电子医疗记录无需争论成千上万的个人文件。研究人员可以利用这些联合数据集搜索就像一个人的遗传密码和属性之间的相关性是否有某种疾病的家族史。
基准测试我们DNASeq管道
精度
自DNASeq管道的输出为重要的研究和临床应用,准确性是至关重要的。结果从我们的管道相对于策划实现高精度高信任度变体调用。注意,这些结果不包括任何变体分数调整或过滤,这将进一步提高精度通过消除误报。
| 精度 | 回忆 | F分数 | |
|---|---|---|---|
| 单核苷酸多态性 | 99.34% | 99.89% | 99.62% |
| INDEL | 99.20% | 99.37% | 99.29% |
呼吁和谐vs GIAB NA24385高信心PrecisionFDA真理的挑战数据集(根据hap.py)
性能
对于我们的基准测试,我们相比DNAseq管道Edico基因组的FPGA实现对代表全基因组和全外显子组数据集从瓶中基因组项目。我们还测试了管道对GIAB 300 x覆盖数据集显示其可伸缩性。每次运行包括最佳实践质量控制措施如重复标记。这个表不包括变异注释时间因为不是所有平台包括它的盒子。bob体育客户端下载
在这些实验中,砖集群直接阅读和写作与S3。运行Edico或OSS GATK4,我们输入数据下载到本地文件系统。下面的下载时间不包括在运行时。根据Edico的文档,系统可以从S3流输入数据,但我们无法得到它的工作。我们使用以来,砖现货实例集群终端会自动恢复点实例。下面的计算成本只包括AWS成本;bob体育客户端下载平台/许可费用排除在外。
30 x覆盖整个基因组
| bob体育客户端下载 | 引用信心代码 | 集群 | 运行时 | 大约计算成本 | 速度提高 |
|---|---|---|---|---|---|
| 砖 | VCF | 13 c5.9xlarge(416芯) | 24 m29s | 2.88美元 | 3.6倍 |
| Edico | VCF | 1 f1.2xlarge (fpga) | 1 h27m | 2.40美元 | - - - - - - |
| 砖 | GVCF | 13 c5.9xlarge(416芯) | 39 m23 | 4.64美元 | 3.8倍 |
| Edico | GVCF | 1 f1.2xlarge (fpga) | 2 h29m | 4.15美元 | - - - - - - |
30 x覆盖全外显子组
| bob体育客户端下载 | 引用信心代码 | 集群 | 运行时 | 大约计算成本 | 速度提高 |
|---|---|---|---|---|---|
| 砖 | VCF | 13 c5.9xlarge(416芯 | 6 m36s | 0.77美元 | 3.0倍 |
| Edico | VCF | 13 c5.9xlarge(416芯 | 19 m31 | 0.54美元 | - - - - - - |
| 砖 | GVCF | 13 c5.9xlarge(416芯) | 7锰 | 0.86美元 | 3.5倍 |
| Edico | GVCF | 1 f1.2xlarge | 25 m34s | 0.71美元 | - - - - - - |
300 x覆盖整个基因组
| bob体育客户端下载 | 引用信心代码 | 集群 | 运行时 | 大约计算成本 | 速度提高 |
|---|---|---|---|---|---|
| 砖 | GVCF | 50 c5.9xlarge(1600芯) | 2 h34m | 69.30美元 | (没有这种规模的竞争解决方案) |
在大致相同的计算成本,我们的管道达到更高的速度,通过横向扩展和GATK4一致。随着数据量或时间敏感性增加,很容易添加额外的计算能力通过增加集群规模加速分析在不牺牲准确性。
技术和优化
分片变量调用
尽管GATK4包括火花实现常用的HaplotypeCaller,目前处于测试阶段和标记为不安全的真正的用例。在实践中,我们发现实现不同意单一节点管道以及遭受长和不可预知的运行时。规模不同的召唤,我们实现了一个新的切分方法上的火花SQL。我们添加了一个催化剂发电机有效的地图每个短读一个或多个衬垫垃圾箱,每个本覆盖了5000个碱基对。然后,我们再分配和排序本id和调用单节点HaplotypeCaller每个垃圾箱。
火花SQL的简单转换
我们的第一个实现使用亚当项目等简单的转换不同变体表示之间的转换和分组成对读取结束。这些转换通常使用引发的抽样API。通过重写它们作为火花SQL表达式,我们节省CPU周期和内存消耗减少。
优化基础设施
最后,我们设法减少数据移动开销,几乎所有的CPU时间运行的核心算法,如BWA-MEM HaplotypeCaller。在这一点上,而不是优化这些外部应用程序,我们专注于优化配置。因为我们控制管道的包装,我们可以做这一步一旦以便我们所有的用户受益。
最重要的优化以减少内存开销,直到我们能利用高CPU虚拟机,每个核心的最低价格,但最少的内存。一些有用的技巧包括压缩GVCF输出带参考区域尽可能早和修改SnpEff变异注释库,这样可以执行人线程之间共享内存数据库。
所有这些优化(以及更多)是我们DNASeq内置管道提供开箱即用的准备解决方案处理和分析大规模基因组数据集在业界领先的速度、精度和成本。
试一试!
我们DNASeq管道目前为私人预览我们的一部分bob体育亚洲版统一为基因组学分析平台bob体育客户端下载。填写预览申请表如果你感兴趣的平台旋转页面或访问我们的基因组的解决方案bob体育客户端下载BOB低频彩。