



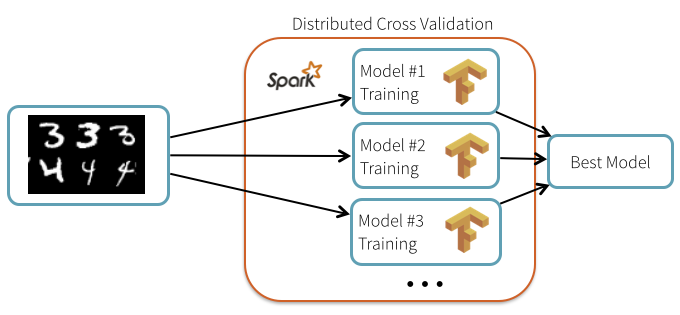
与Apache火花和TensorFlow深度学习
神经网络看到壮观的进步在过去的几年里,他们现在最先进的图像识别和自动翻译。TensorFlow谷歌发布的一个新框架为数值计算和神经网络。在这篇文章中,我们将演示如何使用TensorFlow并引发一起训练和应用深度学习模型。
你可能想知道:什么是Apache火花的大多数高性能深度学习实现时使用这只单节点?要回答这个问题,我们穿过两个用例并解释如何使用火花和一群机改善深度学习与TensorFlow管道:
- Hyperparameter调优:使用火花来找到最佳的hyperparameters神经网络训练,导致10倍减少训练时间和错误率低34%。
- 大规模部署模式:使用火花训练神经网络模型应用到大量的数据。
Hyperparameter调优
深度学习机器学习的一个例子(ML)技术人工神经网络。他们把一个复杂的输入,如一个图像或一个录音,然后应用复杂的数学变换对这些信号。该转换的输出是一个向量的数字被其他ML算法更容易操作。人工神经网络执行这个转换通过模仿人类大脑的视觉皮层的神经元(在一个相当简单的形式)。
就像人类学会解释他们所看到的,人工神经网络需要训练来识别特定模式“有趣”。例如,这些可以是简单的模式,如边缘,圈,但他们可以复杂得多。在这里,我们将使用一个经典数据集由NIST和训练一个神经网络识别这些数字:

TensorFlow图书馆自动化创建的神经网络训练算法的各种形状和大小。建立一个神经网络的实际过程,然而,更复杂的不仅仅是在数据集上运行一个函数。通常有许多非常重要的hyperparameters(配置参数从一个外行人的角度),从而影响模型是如何训练的。选择正确的参数会导致高绩效,而糟糕的参数会导致长时间的训练和糟糕的性能。机器学习在实践中,从业者多次运行相同的模型不同hyperparameters为了找到最好的。这是一个经典的技术称为hyperparameter调优。
在构建神经网络时,有许多重要hyperparameters仔细选择。例如:
- 每一层的神经元数量:神经元太少会降低网络的表达能力,但是太多的将大大增加运行时间和返回嘈杂的估计。
- 学习速率:如果它太高了,神经网络只会专注于过去几个样本见过和无视所有的经验积累。如果太低,需要太长时间达到一个良好的状态。
有趣的是,尽管TensorFlow本身并不是分布式hyperparameter调优过程高度平行,可以分布式使用火花。在这种情况下,我们可以使用火花广播公共元素,如数据和模型描述,然后安排个人重复计算跨一个机器集群容错的方式。
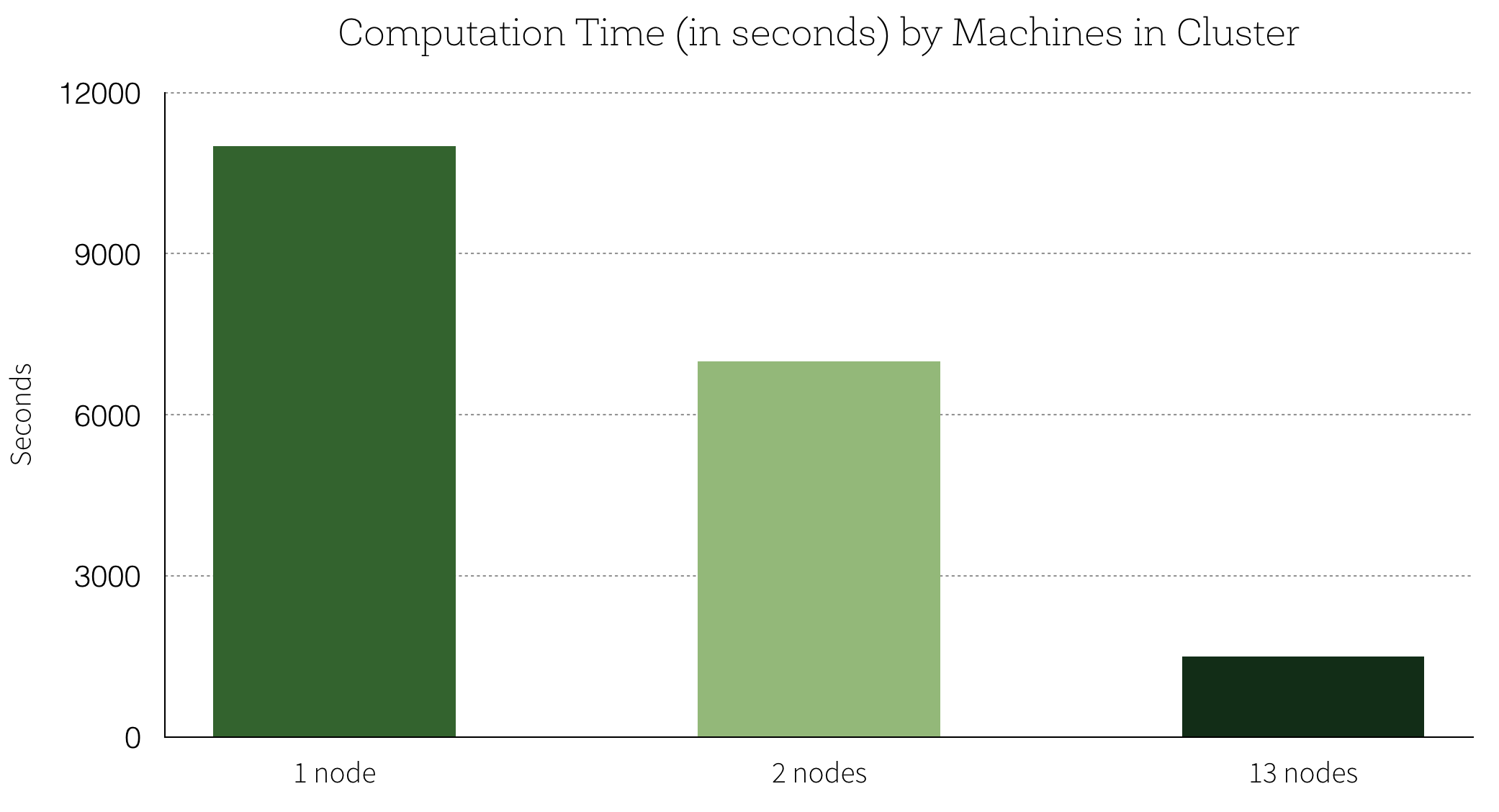
使用火花提高准确性如何?hyperparameters的缺省设置的精度是99.2%。我们最好的结果与hyperparameter调优测试集上有99.47%的准确率,这是一个减少34%的测试误差。分布计算线性扩展添加到集群节点的数目:使用13-node集群,我们能够训练13并行模型,转化为7 x加速训练模型相比,一次在一台机器上。这是一个图形的计算时间(以秒为单位)对机器集群的数量:
更重要的是,我们得到了深入的感性训练过程的各种hyperparameters培训。例如,我们的阴谋最终测试性能对学习速率,不同数量的神经元:
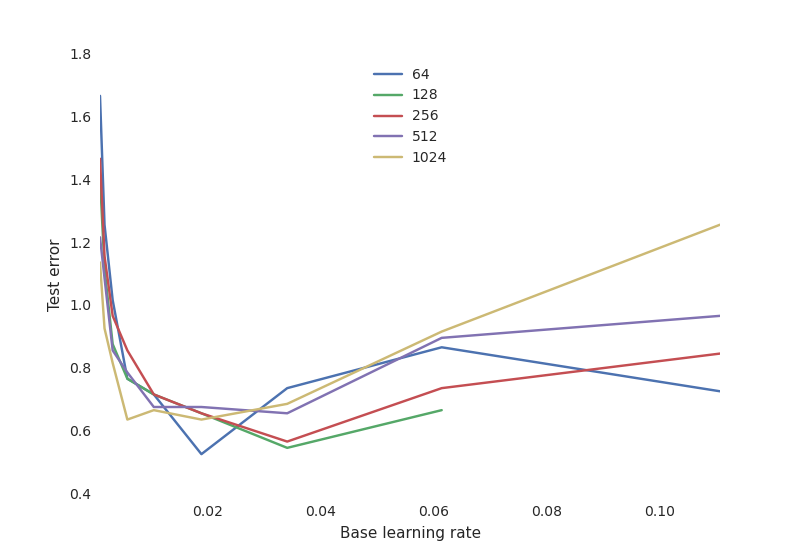
这显示了一个典型的神经网络的权衡曲线:
- 学习速率是至关重要的:如果太低,神经网络没有学到任何东西(高测试误差)。如果它太高了,培训过程可能在某些配置随机振荡甚至发散。
- 神经元的数量并不重要对于获得良好的性能,与许多神经元和网络学习速率敏感得多。这是奥卡姆剃刀原则:简单的模型往往是“足够好”对于大多数用途。后如果你有时间和资源去丢失1%的测试错误,你必须愿意投入大量的资源,培训,和找到适当的hyperparameters将的区别。
通过使用一个稀疏的样本参数,我们可以零的最有前途的参数集。
我怎么使用它呢?
自从TensorFlow每个工人可以使用所有的核心,我们只运行一个任务一次每个工人,我们批一起来限制竞争。TensorFlow图书馆可以安装在火花集群作为一个常规的Python库,之后TensorFlow网站上的说明。以下笔记本下面展示如何安装TensorFlow和让用户重新运行这篇文章的实验:
大规模部署模型
TensorFlow模型可以直接嵌入管道数据集上执行复杂的识别任务。作为一个例子,我们显示如何标签一组股票的图片已经训练的神经网络模型。
模型首先分布式集群的工人,用火花的内置广播机制:
gfile。FastGFile (“classify_image_graph_def。pb, rb) f:
model_data = f.read ()
model_data_bc = sc.broadcast (model_data)
然后在每个节点上加载这个模型应用于图像。这是一个草图在每个节点上运行的代码:
def apply_batch (image_url):
#创建了一个新的计算模型和进口TensorFlow图
用tf.Graph () .as_default g ():
graph_def = tf.GraphDef ()
graph_def.ParseFromString (model_data_bc.value)
特遣部队。import_graph_def (graph_def name = ")
#从URL加载图像数据:image_data = urllib.request。urlopen (img_url超时=1.0).read ()#一个张量流会话加载运行与tf.Session ()作为税:softmax_tensor = sess.graph.get_tensor_by_name (softmax: 0的)预测= sess.run (softmax_tensor, {“DecodeJpeg /内容:0”:image_data})返回预测这段代码可以更有效的通过批处理图片。
这是一个形象的例子:

这是这张图片的解释根据神经网络,这是相当准确的:
(0.88503921),“珊瑚礁”
(戴水肺的潜水员,0.025853464),
(“脑珊瑚”,0.0090828091),
(“潜水”,0.0036010914),
(“海角,岬,头,前陆”,0.0022605944)])
期待
我们已经展示了如何结合火花和TensorFlow训练神经网络部署在手写数字识别和图像标记。尽管我们使用的神经网络框架本身只在单节点工作,我们可以用火花分发hyperparameter优化过程和模型部署。这不仅减少了训练时间,也提高了准确性和给我们一个更好的理解各种hyperparameters感性。
虽然这只是用于Python的支持,我们期待TensorFlow之间更深层次的集成和火花的其他框架。
免费试着砖
相关的帖子