
可伸缩的协同过滤与Apache MLlib火花



推荐系统是最受欢迎的应用机器学习。这个想法是为了预测客户是否会像某些项:产品、电影或歌曲。对推荐系统规模是一个关键问题,因为计算复杂度增加的大小公司的客户基础。在这篇文章里,我们将讨论如何Apache火花MLlib使建筑从数十亿记录的推荐模型只需要几行Python (Scala / Java api也可用)。
从pyspark.mllib。建议导入肌萎缩性侧索硬化症
训练和测试数据加载到元组(用户、产品等级)
def parseRating(线):
字段= line.split ()
返回(int(字段[0]),int[1](字段),浮动(字段[2]))
培训= sc.textFile (“…”) . map (parseRating) .cache ()
测试= sc.textFile (“…”) . map (parseRating)
火车推荐模型
模型= ALS。培训(培训、等级= 10迭代= 5)
作出预测的(用户、产品)对测试数据
预测= model.predictAll(测试。地图(λx (x [0], [1])))
引擎盖下面发生了什么?
推荐算法通常分为:
(1)基于内容的过滤:建议用户类似的物品。一个例子将会扮演一个Megadeth歌曲后金属乐队的歌。
(2)协同过滤:基于相似用户的推荐项目,例如,推荐视频游戏后有人买一个游戏机,因为其他的人买了游戏机还买了视频游戏。

火花MLlib实现了协同过滤算法交替最小二乘(ALS),实现在许多机器学习库和在学术界和产业界广泛研究和使用。ALS模型评级矩阵的乘法(R)煤用户(U)和产品(V)的因素,这些因素和学习通过最小化的重建误差观测到的评级。未知的评级可以随后被乘以计算这些因素。通过这种方式,公司可以推荐的产品基于预测评级和增加销售和客户满意度。
ALS是一种迭代算法。在每个迭代中,该算法或者修复因子矩阵,解决了另一个,继续这个过程,直到收敛。MLlib ALS的阻塞特性实现算法,利用火花的有效支持分布式,迭代计算。它使用本地LAPACK实现高性能和尺度数十亿评级商品集群。
可伸缩性、性能和稳定性
最近我们做了一个实验在引发大规模MLlib基准ALS的实现。基准使用m3.2xlarge EC2实例上进行设立的火花EC2脚本。我们跑火花的开箱即用配置。帮助了解最先进的,我们也从GitHub Mahout建造和测试它。这个基准测试都可以在EC2上使用的脚本https://github.com/databricks/als-benchmark-scripts。
我们跑了5次迭代的ALS的副本亚马逊的评论数据集,其中包含3500万评级从660万用户240万的产品。对于每个用户,我们创建pseudo-users具有相同的评级。即每评级(userId, productId,评级),我们生成(userId +我productId评级)0
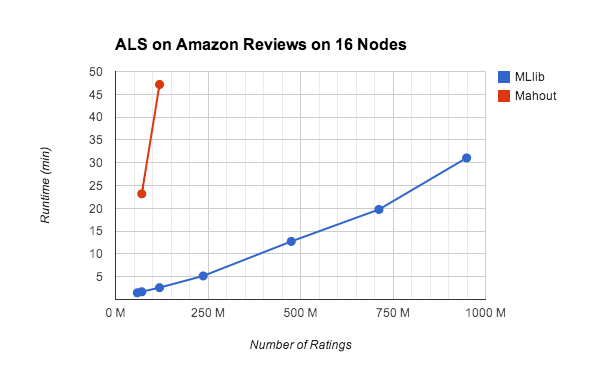
当前版本的Mahout Hadoop上运行MapReduce的调度开销和缺乏支持迭代计算大大减缓ALS。Mahout最近宣布转向火花执行引擎,这将有希望解决性能问题。
火花MLlib展示了出色的性能和可伸缩性,见上面的图表。MLlib也可以扩展到更大的数据集和更多的节点,由于其容错设计。和50个节点,我们跑10迭代MLlib ALS的100份亚马逊评论数据集只有40分钟。与EC2实例的总成本不到2美元。用户可以使用火花MLlib减少模型训练时间和ALS的成本,这是历史上非常昂贵的运行,因为该算法的通信和计算密集型的。
| #评级 | #用户 | #产品 | 时间 |
| 35亿年 | 6.6亿年 | 240万年 | 40分钟 |
我们相信在砖和更广泛的火花社区机器学习框架需要高性能、可伸缩的,并且能够覆盖范围广泛的工作负载包括数据探索和特征提取。MLlib无缝集成与其他组件,提供最佳性能,大大简化了操作的复杂性的容错运行引擎。也就是说,我们的工作没有完成,我们正在做机器学习更容易。请继续关注更多令人兴奋的特性。
注意:博客更新7月24日,2014年,以反映新的性能优化,将包含在火花MLlib 1.1。运行时为3.5 b评级从90分钟MLlib MLlib 1.1中1.0 - 40分钟。