









Lakehouse使计算机视觉应用程序与数据
计算机视觉应用的潜在改变零售和制造业务,探索在博客解决看不见的质量、操作和安全…
2021年12月17日, 在工程的博客
计算机视觉应用的潜在改变零售和制造业务,探索在博客解决看不见的质量、操作和安全挑战Lakehouse使计算机视觉,不能被夸大。说,许多技术挑战阻止组织实现这一潜力。在我们多方技术系列的第一个介绍性的部分在计算机视觉的应用程序的开发和实现,我们深入挖掘这些挑战和探索摄入的基本模式用于数据,模型训练和部署。
图像数据的独特性质意味着我们需要仔细考虑我们如何管理这些信息资产,和前线训练模型的集成应用程序意味着我们需要考虑一些非传统的部署路径。不存在放之四海而皆准的解决方案,每一个计算机视觉挑战,但许多技术和技术开发的企业已经率先使用计算机视觉系统来解决实际业务问题。通过利用这些,作为探索在这篇文章中,我们可以更迅速地从示范操作化。
第一步发展的大多数计算机视觉应用程序(在设计和规划)是图像数据的积累。图像文件被camera-enabled设备和传输到中央存储库中,在他们准备用于训练模型。
重要的是要注意,许多流行的格式,比如PNG和JPEG,支持嵌入式元数据。基本元数据,如图像的高度和宽度,支持像素值转化为二维表示。额外的元数据,例如文件格式交换信息(Exif)元数据,可以嵌入提供额外的细节镜头,它的配置,可能它的位置(假设该设备配备GPS传感器)。
当建立一个图像库、元数据以及图像统计,有用数据科学家,因为他们筛选数以千计甚至数以百万计的图像通常积累在计算机视觉的应用程序,处理他们的土地Lakehouse存储。如利用常见的开源库枕头元数据和统计数据可以提取和保存在一个可查询的表Lakehouse环境更容易访问。组成图像的二进制数据也可以保存到这些表连同原始文件的路径信息存储环境。
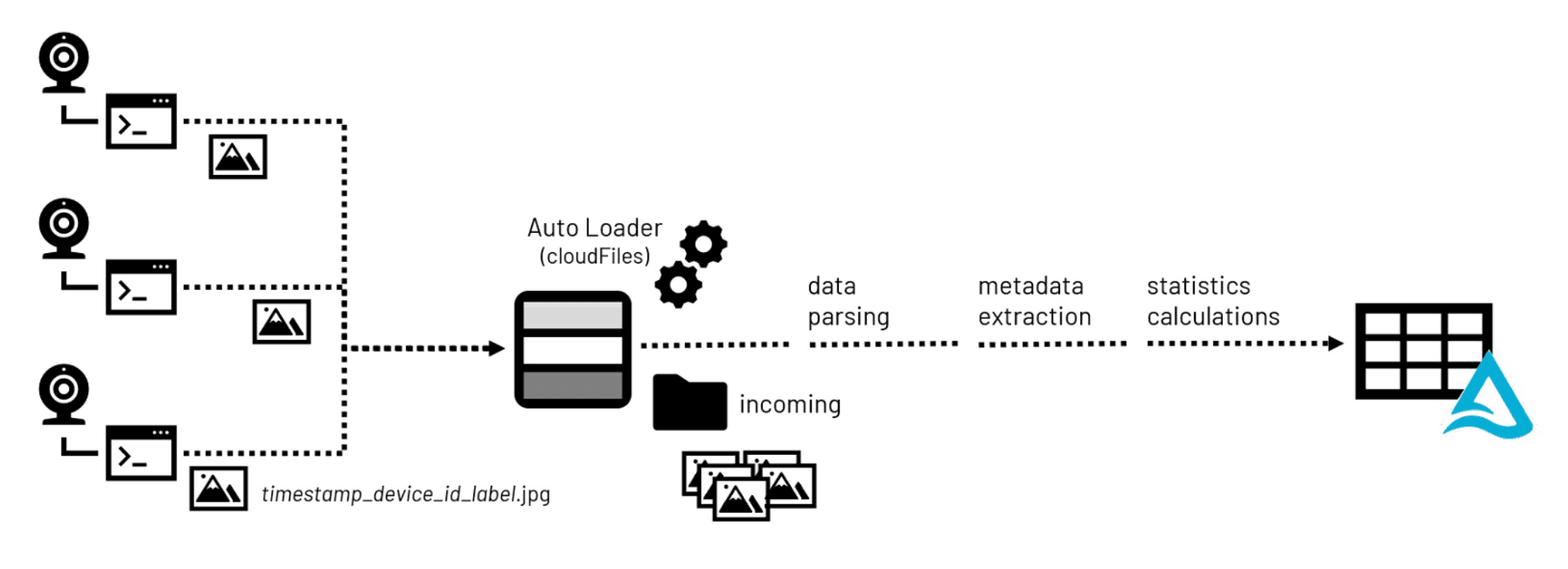
单独的图像文件的大小结合大量的火车需要一个健壮的模型意味着我们需要仔细考虑如何处理他们在模型训练。技术常用于数据收集模型等科学练习输入一个熊猫dataframe不会经常工作在企业范围内由于对个人电脑的内存限制。火花™dataframes,分发数据量在多个计算机集群配置为一个计算节点,不是由大多数计算机视觉库访问另一个解决这个问题是必要的。
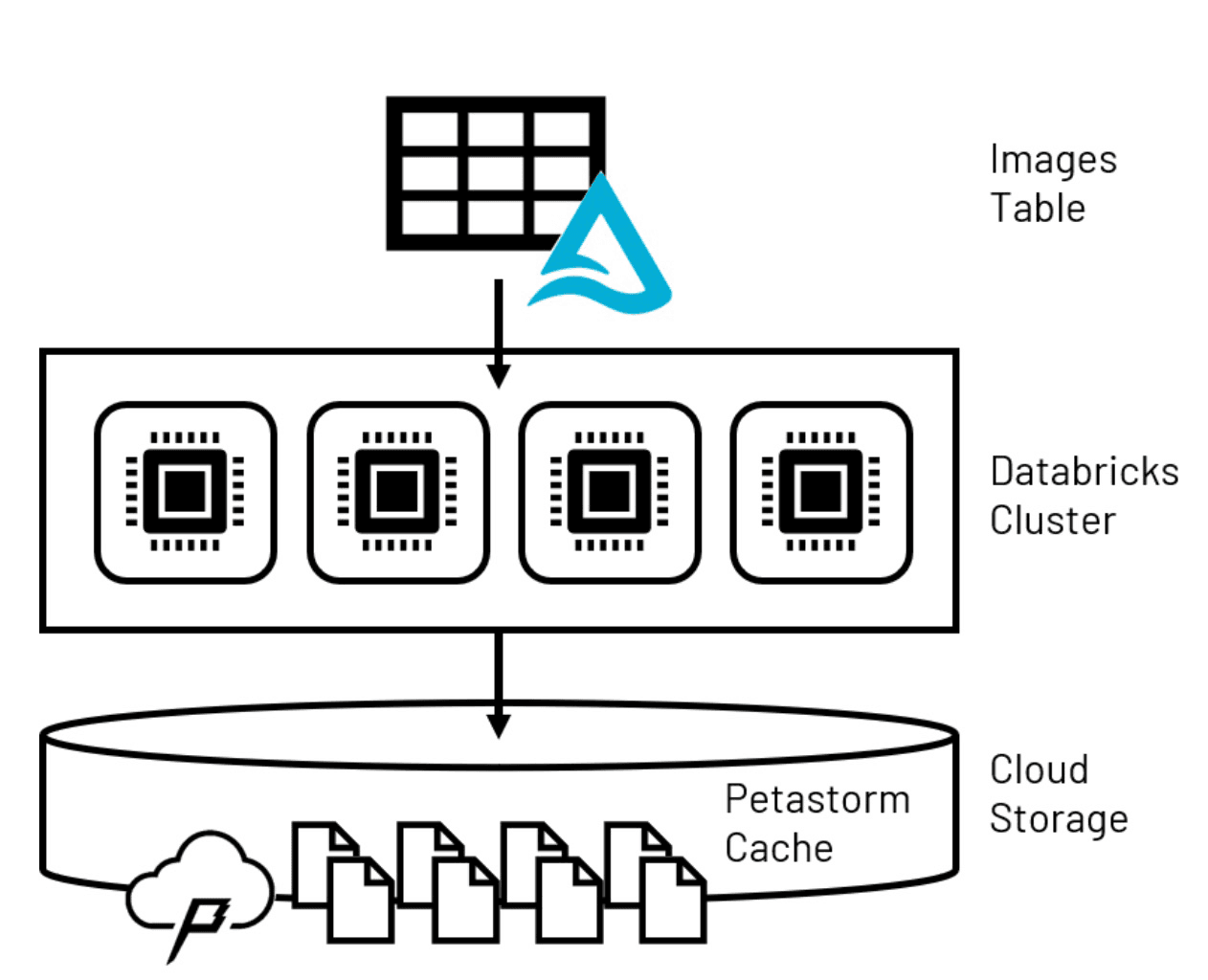
为了克服第一个模型训练的挑战,Petastorm数据缓存技术建立专门为大型培训先进的深度学习模型类型,可以使用。Petastorm允许检索大量数据从Lakehouse和它在一个临时的地方,基于存储缓存。模型利用Tensorflow和PyTorch,深层神经网络发展的两个最流行的库和普遍采用在计算机视觉应用,可以阅读一小部分批次的数据从缓存中遍历Petastorm大数据集。
数据量可控的,下一个挑战是加速度模型的训练。机器学习模型通过迭代学习。这意味着通过培训将包括一系列重复输入数据集。互相传递,模型学习优化权重带来更好的预测精度的各种特性。
模型的学习算法是由一组称为hyperparameters参数。这些hyperparameters往往难以设定的值仅基于领域知识,所以典型的模式,发现最优hyperparameter配置训练多个模型,以确定哪些表现最好。这一过程,称为hyperparameter调优,意味着迭代的迭代。
通过很多迭代技巧的工作及时分发hyperparameter调优运行在集群的计算节点,这样他们可能以类似的方式执行。利用Hyperopt,之间的电波,可以委托这些运行的Hyperopt软件可以评估hyperparameter值导致这结果,然后明智地设置为下一波hyperparameter值。多次波,软件收敛于最优的一组hyperparameter值远远超过如果一个详尽的评估值执行了。
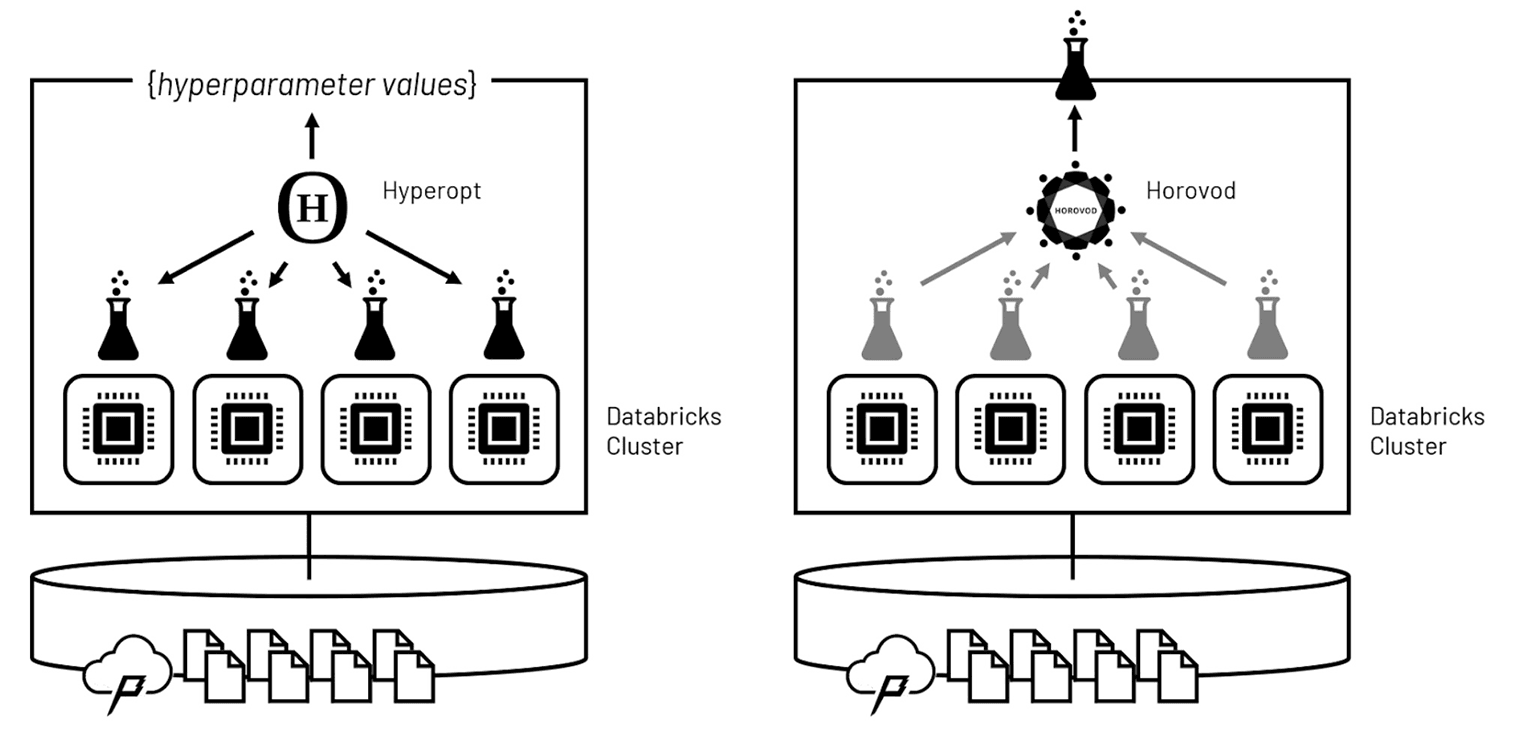
一次最优hyperparameter值已经确定,Horovod可用于跨集群分发最终模型的训练。Horovod坐标的独立训练模型在每个集群的计算节点使用重叠输入训练数据的子集。重量从这些并行运行每个经过完整的输入设置合并,重新平衡和模型是基于他们的集体学习。最终的结果是一个优化模型,使用集体集群的计算能力训练。
与计算机视觉模型,目标通常是将模型预测到一个空间,一个操作员通常执行目视检查。虽然集中式得分后台的图片可能有意义在某些场景中,更常见的情况是,当地(边缘)设备将负责捕捉图像和调用训练模型实时生成了输出。根据模型的复杂性,本地设备的容量和容忍延迟和/或网络中断、边缘部署通常采取两种形式。
microservices部署,作为网络服务模型。这个服务可能驻留在一个集中的位置或跨多个位置更紧密地与一些边缘设备的数量。然后在设备上运行的应用程序配置为发送图片到服务接收所需的成绩作为回报。这种方法的优点是为应用程序开发人员提供更大的灵活性为模型托管和访问资源的服务远远超过通常可以在设备的优势。它的缺点是需要额外的基础设施,有网络延迟和/或中断的风险影响的应用程序。
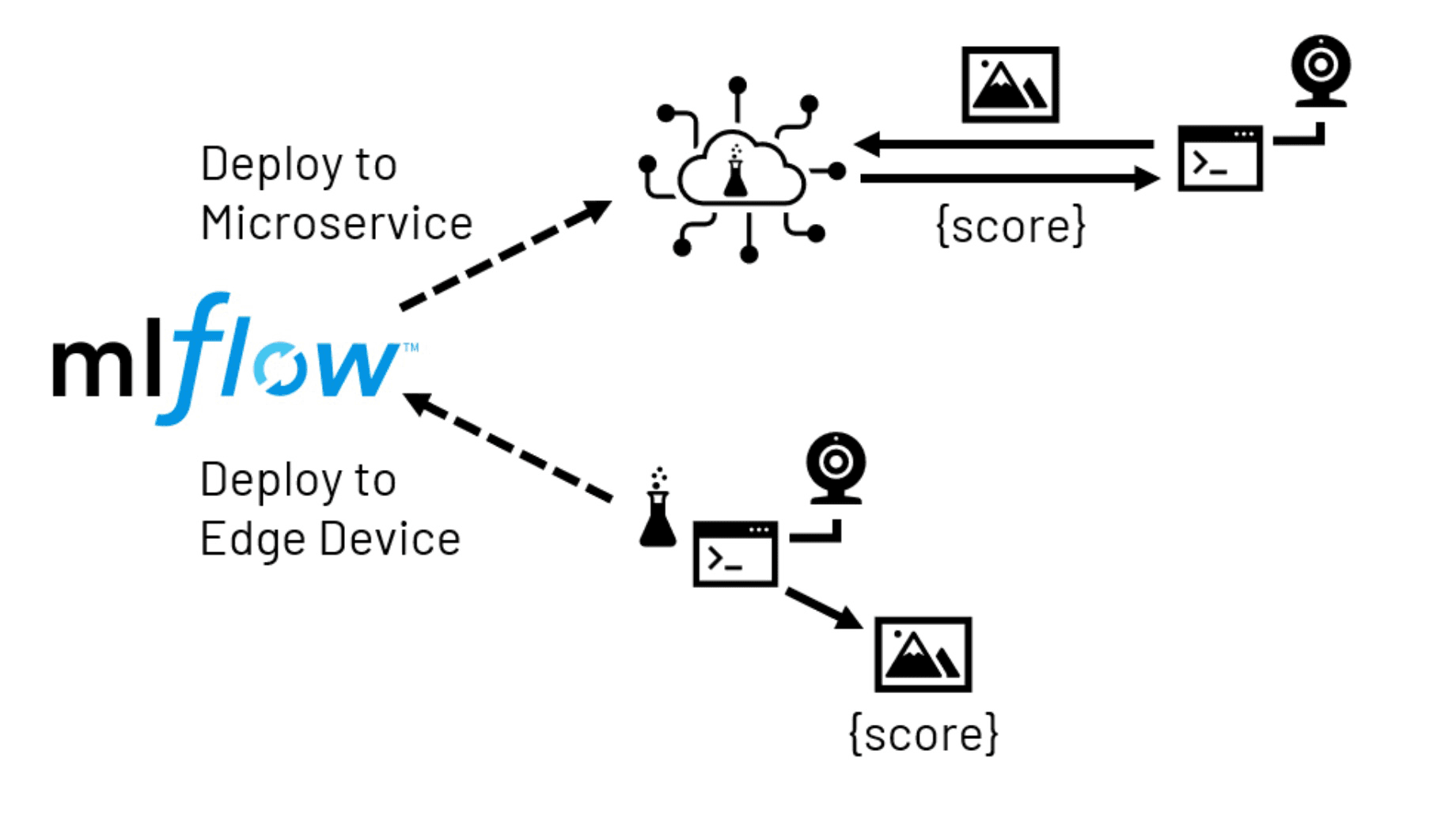
边缘部署,先前训练模型直接发送到本地设备。这就消除了担忧网络模型已经交付,但有限的硬件资源在设备上可以施加约束。此外,许多边缘设备利用显著不同的处理器的系统模型是训练有素的。这可以创建软件的兼容性问题,可能需要仔细研究之前的资源部署。
在这两种场景中,我们可以利用MLflow模型管理存储库,帮助我们的包装和交付模型。
演示如何将这些不同的挑战可能会解决,我们已经开发出一系列笔记本利用数据捕获从PiCamera装备覆盆子π设备。由这个设备已经拍摄的图像传输到云存储环境中,这些图像摄取、模型训练和部署模式可以证明使用砖毫升的运行时,它已预设与上面描述的所有功能。看到这个演示背后的细节,请参阅以下笔记本: