火花流
返回术语表什么是Spark Streaming?
Apache Spark Streaming是一个可扩展的容错流处理系统,本机支持批处理和流工作负载。Spark Streaming是Spark核心API的扩展,它允许数据工程师和数据科学家处理来自各种来源的实时数据,包括(但不限于)Kafka、Flume和Amazon Kinesis。处理后的数据可以推送到文件系统、数据库和实时仪表板。它的关键抽象是离散流,或者简而言之,DStream,它表示分成小批的数据流。DStreams是建立在rdd (Spark的核心数据抽象)之上的。这允许Spark Streaming与任何其他Spark组件(如MLlib和Spark SQL)无缝集成。Spark Streaming不同于其他系统,这些系统要么有专门为流设计的处理引擎,要么有类似的批处理和流api,但在内部编译到不同的引擎。Spark针对批处理和流的单一执行引擎和统一编程模型比其他传统的流系统有一些独特的优势。Spark流的四个主要方面
- 从失败和掉队中快速恢复
- 更好的负载平衡和资源使用
- 将流数据与静态数据集和交互式查询相结合
- 与高级处理库(SQL、机器学习、图形处理)的本地集成
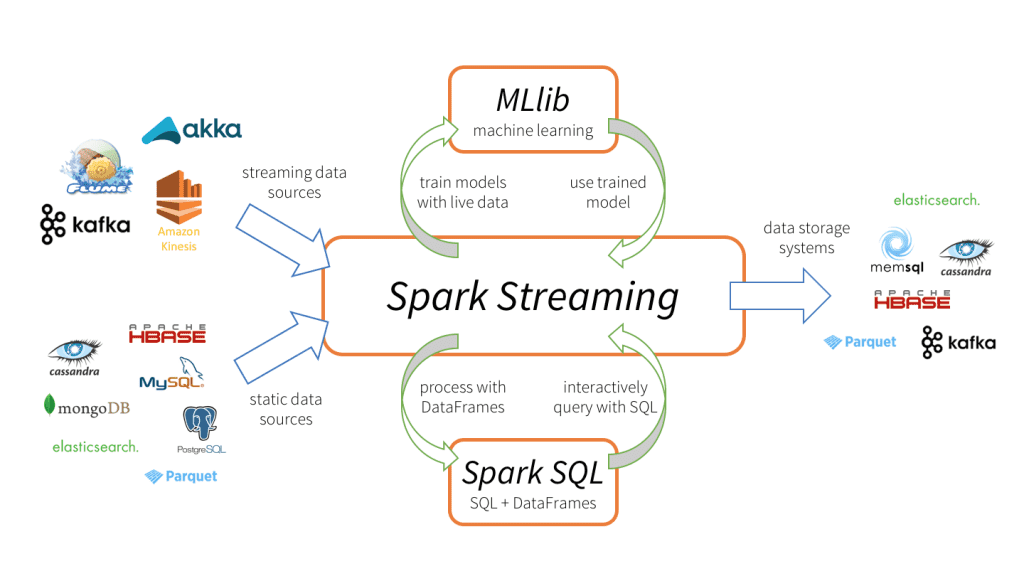 这种不同数据处理能力的统一是Spark Streaming迅速被采用的关键原因。这使得开发人员可以很容易地使用一个框架来满足他们所有的处理需求。
这种不同数据处理能力的统一是Spark Streaming迅速被采用的关键原因。这使得开发人员可以很容易地使用一个框架来满足他们所有的处理需求。额外的资源
返回术语表
