
星型模式
免费试着砖
星型模式是什么?
一个星型模式是一个多维数据模型用来组织数据在数据库中,这样很容易理解和分析。明星模式可以应用于数据仓库,数据库,数据集市和其他工具。星型模式设计是优化查询大型数据集。
由拉尔夫·金伯尔引入在1990年代,明星模式有效地存储数据,维护历史,和更新数据通过减少重复重复的业务定义,使其快速聚合和过滤数据仓库中的数据。
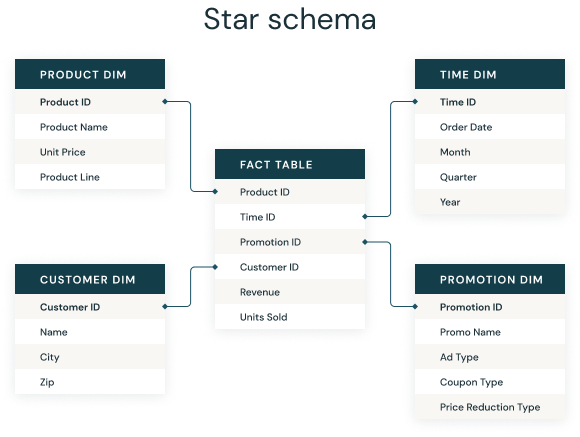
事实表和维度表
应该用星型模式正规化业务数据到维度(如时间和产品)和事实(如交易金额和数量)。
一个星型模式只有一个事实表的中心,包含业务“事实”(如交易金额和数量)。事实表连接到多个其他维度表“维度”时间,或产品。明星模式使用户能够切割数据但是他们认为合适的,通常通过加入两个或两个以上的事实表和维度表在一起。
非正规数据
明星模式denormalize数据,这意味着添加冗余列一些维度表进行查询和处理数据的速度更快,更容易。目的是为了贸易一些冗余(重复数据)的数据模型来提高查询速度,避免计算昂贵的连接操作。
在这个模型中,事实表规范化,但是没有尺寸表。也就是说,事实表的数据只存在事实表,但维表可能包含冗余的数据。
星型模式的好处
- 事实/维度模型像明星模式简单的理解和实现,使最终用户更容易找到他们所需要的数据。他们可以应用到数据集市和其他数据资源。
- 的简单查询因为他们减少依赖连接访问数据时,归一化模型相比就像雪花模式。
- 能很好的适应适应OLAP模型。
- 提高查询性能规范化数据相比,因为明星模式试图避免计算昂贵的连接。
星型模式如何不同于3 nf(第三范式)?
3 nf或第三范式,通过标准化的方法减少数据冗余。它是一种常见的标准被认为是完全规范化的数据库。它通常比星型模式表由于数据规范化。从另一方面,倾向于更复杂的查询,由于大型表之间的连接数量的增加。
