
对数据作业的访问控制

使用Databricks全面的访问控制系统端到端保护您的生产工作负载
Databricks为集群和工作空间提供基于角色的访问控制,以保护基础设施和用户代码。今天,我们很高兴地宣布Databricks job也具有基于角色的访问控制功能,这样用户就可以轻松地控制谁可以访问作业输出并控制其生产工作负载的执行。
Databricks作业由内置调度器、要运行的任务、日志、运行输出、警报和监视策略组成。Databricks Jobs允许用户轻松调度笔记本电脑,S3中的jar,来自S3的Python文件并提供支持spark-submit.用户还可以从外部系统(如气流或Jenkins)触发他们的工作。
计划生产作业的敏感性
在运行生产工作负载时,用户希望控制谁可以访问部分计划作业和操作。例如:
- 确保工作输出:Databricks Jobs的一个显著优势是,它允许用户轻松地安排笔记本,并查看不同运行的结果,如下所示。这些输出可能包含个人身份信息(PII)数据或其他敏感信息。用户只希望特定的同事查看这些信息,而不给予他们任何其他工作控制。
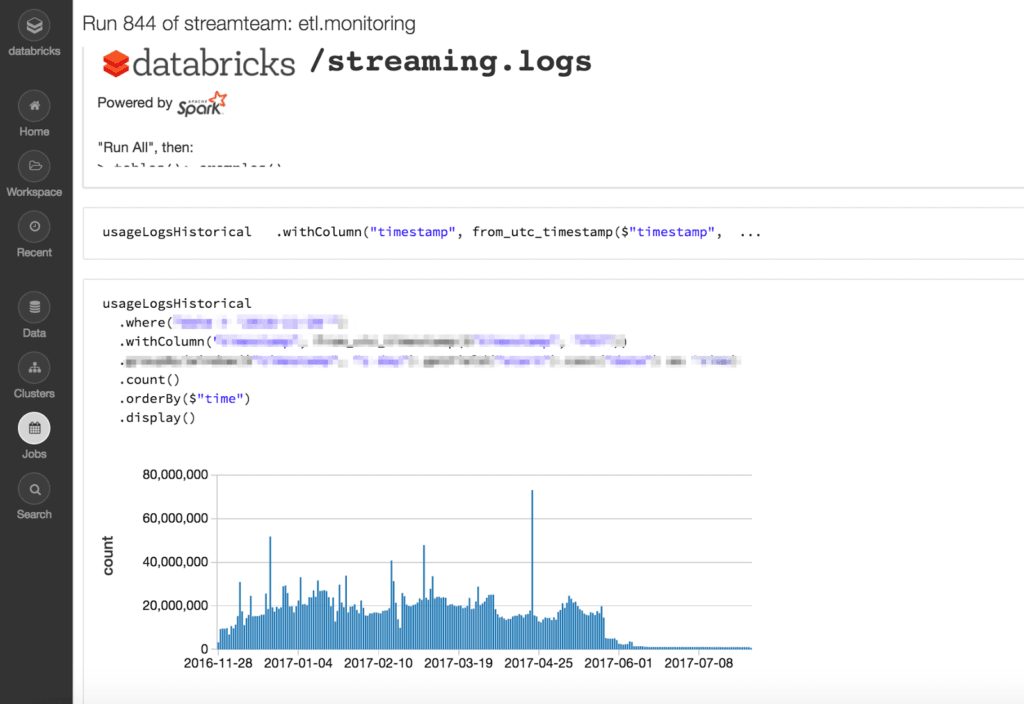
- 确保日志:日志可能包含敏感信息,用户不希望没有权限的用户查看日志。
- 控制作业执行:作为作业的所有者,您希望限制对团队成员的访问,以便只有他们可以取消任何糟糕的运行或触发一些手动运行以进行故障排除。
- 控制对作业属性的访问:Databricks Jobs提供了许多很棒的功能,如自定义警报、监视、作业运行超时等。用户不希望其他人更改其作业的属性。
- 工作所有权:每个Databricks作业都有一个所有者,所有预定的运行都代表他执行。当一个所有者离开一个组织时,需要有一种简单的方法来转换所有权,这样工作就不会成为孤儿。
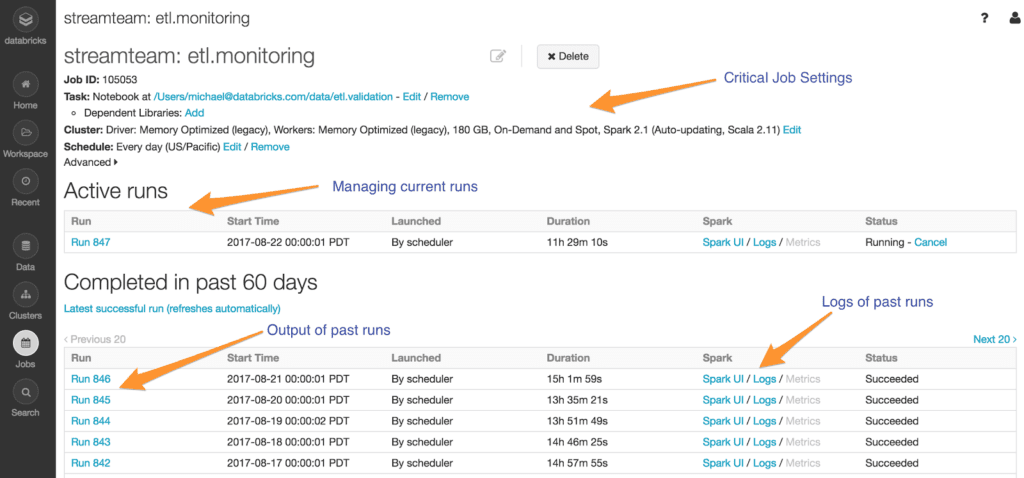


在Databricks中保护您的生产工作负载
我们很高兴为Databricks Jobs引入细粒度访问控制,以保护您的生产工作负载的不同方面不受组织中无权限用户的影响。
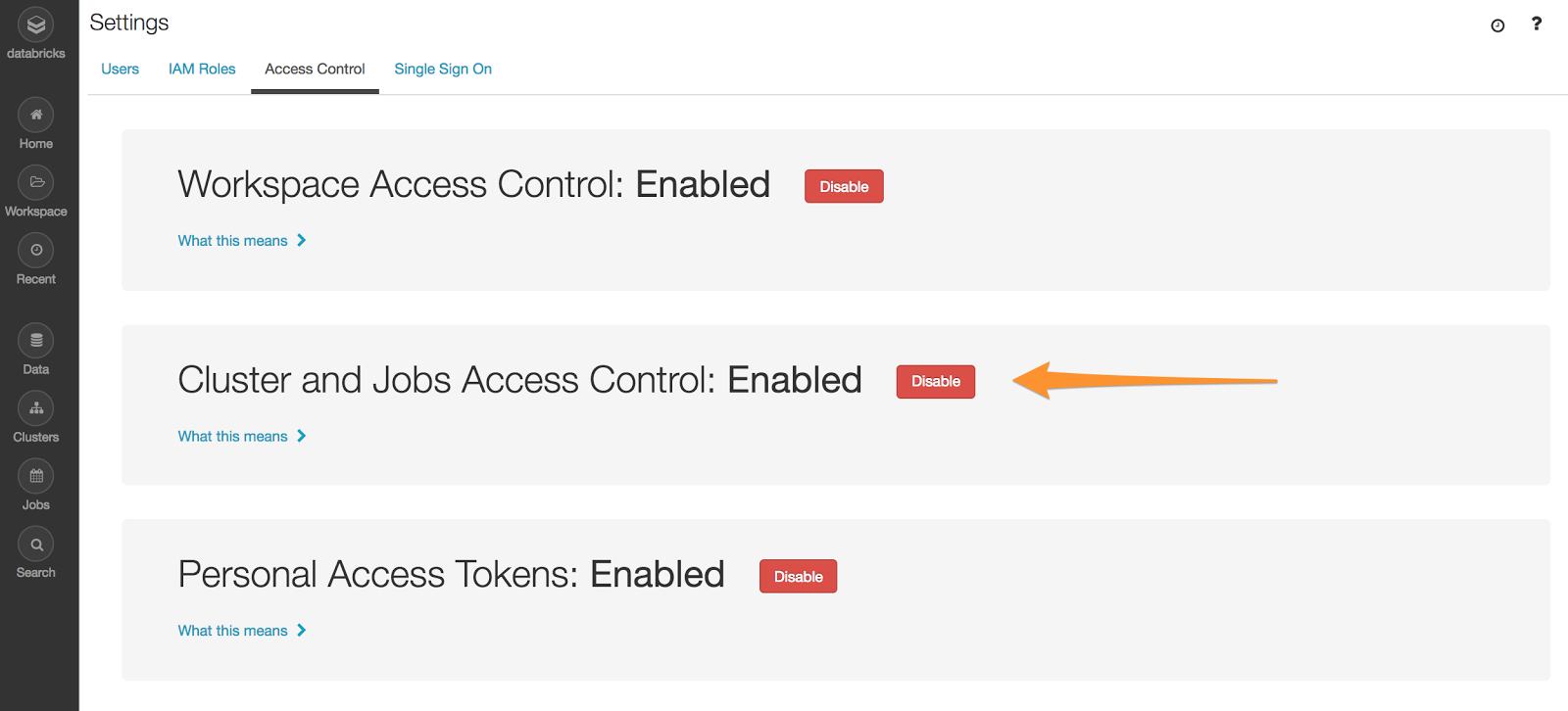
启用作业访问控制
管理员可以在管理控制台中启用作业和集群的访问控制。
权限级别
启用作业acl后,每个用户或组可以在Databricks作业上拥有五种不同权限级别中的一种。管理员或作业所有者可以向其他用户或组授予其中一个或多个权限。权限级别形成了一个谱系,其中具有较高权限级别的用户可以执行较低级别允许的任何操作。下表按顺序列出了权限级别及其所包含的内容。
| 权限 | 权限允许什么? |
| 默认的 | 仅允许用户查看作业设置和运行元数据。用户无法查看任何其他敏感信息,如作业输出或日志。 |
| 可以查看 | 允许用户只查看作业输出和日志以及作业设置。用户无法控制作业的执行。 |
| 管理运行 | 允许用户查看输出,还可以取消和触发单独的运行。 |
| 老板 | 允许用户编辑作业设置。 |
| 管理 | 允许用户更改作业所有者。 |
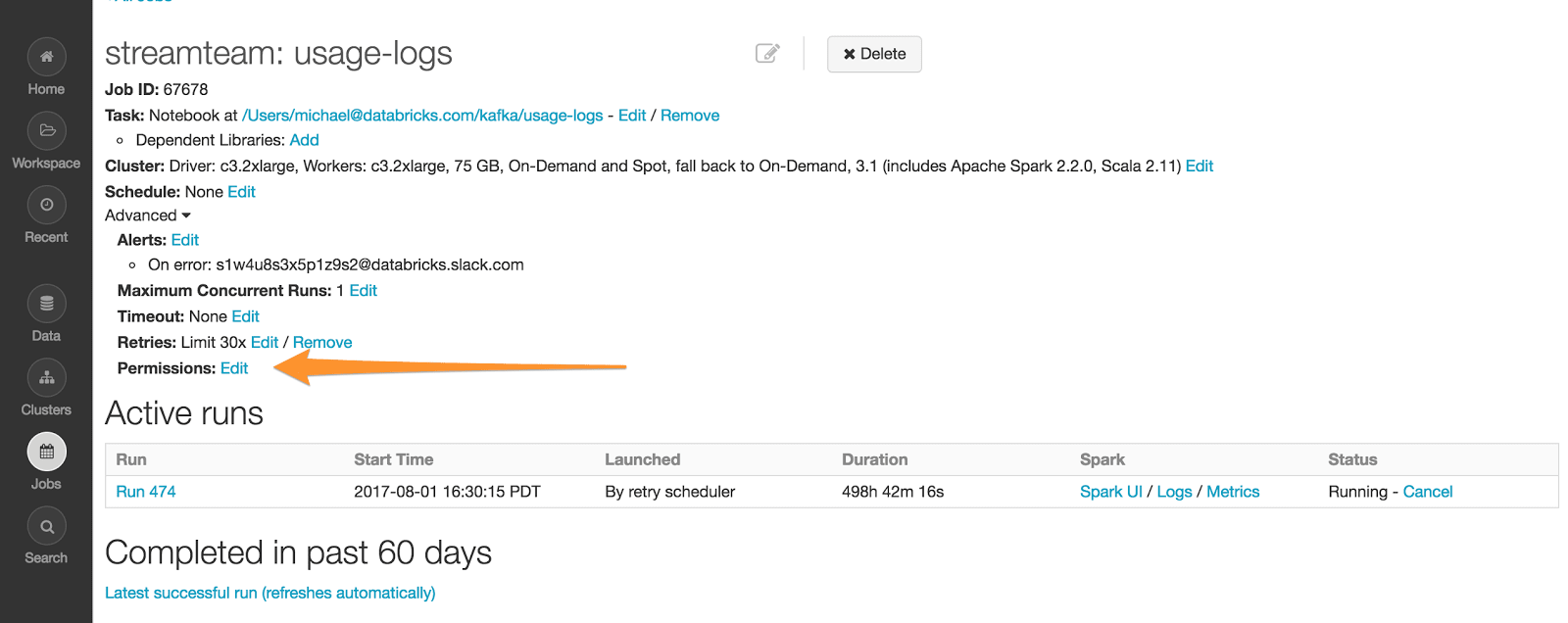
这些权限可以从任务详细信息页面的“高级”部分给出,如下所示:
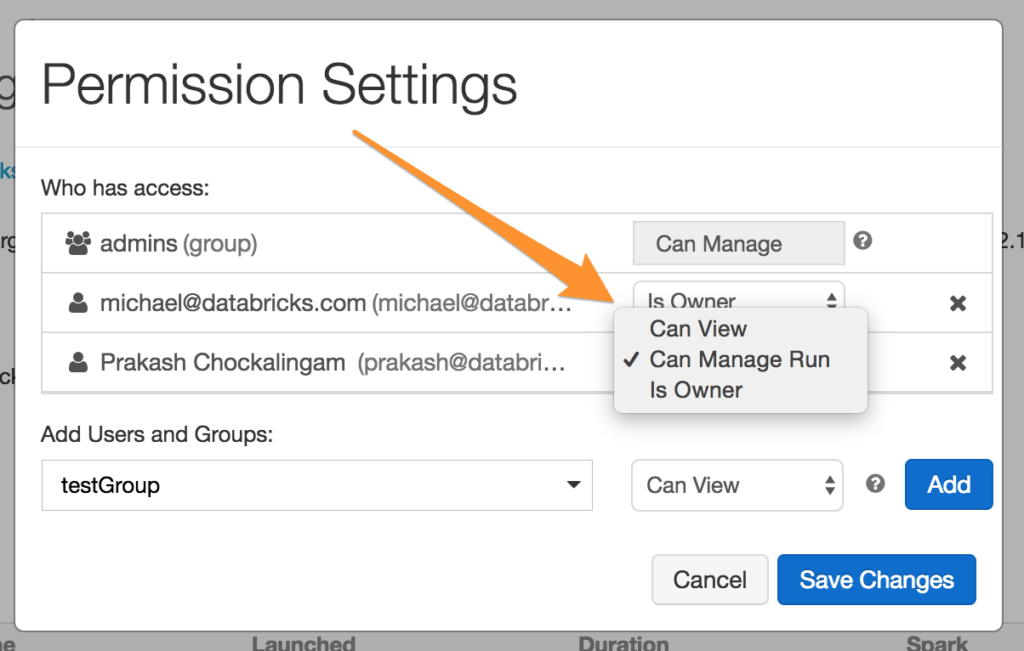
工作的所有权
只有作业所有者才能更改作业设置。如果作业所有者离开组织或希望转移所有权,管理员可以轻松切换该作业的所有者。这项工作只能有一个所有者。
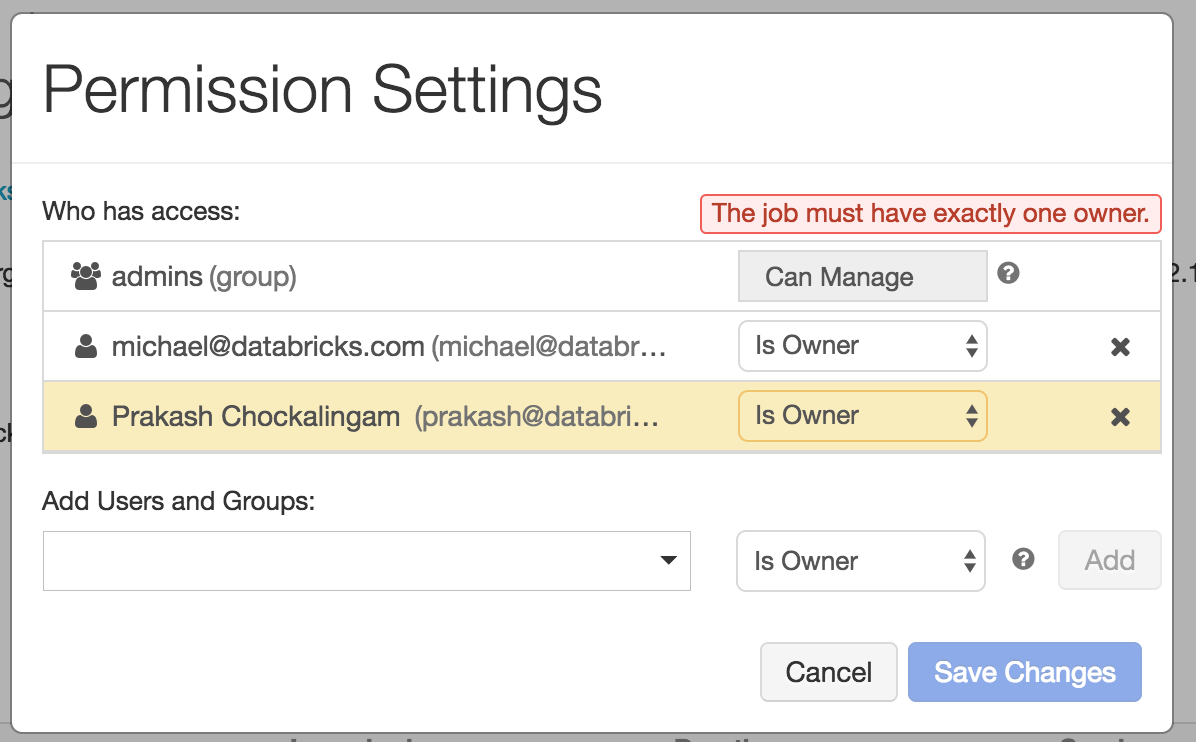
用户角色和操作
下表总结了不同的用户角色以及允许他们执行的操作。
| 用户角色→ 行动↓ |
默认的 | 有查看权限用户 | 具有管理运行权限的用户 | 工作的老板 | 管理员 |
| 查看作业设置 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 查看当前和历史作业输出 | ✅ | ✅ | ✅ | ✅ | |
| 查看当前日志和历史日志 | ✅ | ✅ | ✅ | ✅ | |
| 触发新的运行 | ✅ | ✅ | ✅ | ||
| 取消当前运行 | ✅ | ✅ | ✅ | ||
| 修改集群和作业设置 | ✅ | ✅ | |||
| 修改作业权限 | ✅ | ✅ | |||
| 删除作业 | ✅ | ✅ | |||
| 把主人换给别人 | ✅ |
端到端的全面门禁系统
用户可以通过利用Databricks提供的所有访问控制机制来控制对基础设施、代码和数据的访问:
- 集群acl:所有作业都需要集群,用户可以分别为用户和组提供细粒度的访问控制,以确定他们对运行生产作业的底层基础设施拥有哪些权限。
- 工作区acl:用户可以从Databricks工作空间调度笔记本。使用工作区acl,用户可以控制谁可以读取/运行/修改他们的生产代码。
- acl数据:通过Amazon的IAM角色提供对数据的访问控制。Databricks还支持对IAM角色的访问控制,以便管理员可以控制哪些用户有权使用Databricks中的哪些IAM角色。
- 乔布斯acl:如上所述,对作业本身的访问控制使用户能够从无特权的用户手中保护自己的生产作业。
接下来是什么?
开始在Databricks上运行您的Spark作业注册免费试用Databricks.
如果你有任何问题,你可以问如果您有问题,请联系我们.