创建、运行和管理Databricks作业
作业是在Databricks集群中运行非交互式代码的一种方式。例如,您可以以交互方式或计划方式运行提取、转换和加载(ETL)工作负载。中以交互方式运行作业笔记本用户界面.
您可以使用UI、CLI或调用Jobs API来创建和运行作业。您可以使用UI或API修复并重新运行失败或取消的作业。您可以使用UI、CLI、API和通知(例如,电子邮件、webhook目的地或Slack通知)监控作业运行结果。本文主要讨论使用UI执行作业任务。有关其他方法,请参见乔布斯CLI而且职位API 2.1.
您的工作可以由单个任务组成,也可以是具有复杂依赖关系的大型多任务工作流。Databricks管理所有作业的任务编排、集群管理、监控和错误报告。您可以通过易于使用的调度系统立即或定期运行作业。
您可以在JAR、Databricks笔记本、Delta Live Tables管道或用Scala、Java或Python编写的应用程序中实现任务。还支持遗留Spark Submit应用程序。您可以通过指定任务之间的依赖关系来控制任务的执行顺序。您可以将任务配置为按顺序或并行运行。下图说明了一个工作流:
摄取原始点击流数据并执行处理以会话记录。
摄取订单数据并将其与会话化的点击流数据连接起来,以创建用于分析的准备好的数据集。
从准备好的数据中提取特征。
并行执行任务以持久化特征并训练机器学习模型。


要使用Databricks作业创建第一个工作流,请参见快速入门.
重要的
只能在数据科学与工程工作空间或机器学习工作空间中创建作业。
一个工作空间被限制为1000个并发作业运行。一个
429太许多请求当您请求不能立即开始的运行时,返回响应。一个工作空间在一小时内可以创建的作业数量限制为10000个(包括“运行提交”)。此限制还会影响REST API和笔记本工作流创建的作业。
创造一个工作
做以下其中一件事:
点击
 工作流在侧栏中,单击
工作流在侧栏中,单击 .
.在侧栏中,单击
 新并选择工作.
新并选择工作.
的任务选项卡将显示创建任务对话框。
取代为你的工作添加一个名字…你的工作名称。
中输入任务的名称任务名称字段。
在类型下拉菜单,选择要运行的任务类型。
笔记本:在源下拉菜单,为笔记本选择一个位置;要么工作空间用于位于Databricks工作区文件夹中的笔记本或Git提供者用于位于远程Git存储库中的笔记本。
工作空间:使用文件浏览器找到该笔记本,单击该笔记本名称,单击确认.
Git提供者:点击编辑并输入Git存储库信息。看到在Databricks作业中使用版本控制的笔记本.
JAR:指定主类.使用包含主方法的类的完全限定名,例如,
org.apache.spark.examples.SparkPi.然后单击添加下依赖库添加运行任务所需的库。其中一个库必须包含主类。要了解BOB低频彩更多关于JAR任务的信息,请参见JAR的工作.
火花提交:在参数文本框,指定主类、库JAR的路径和所有参数,格式化为JSON字符串数组。下面的示例配置spark-submit任务来运行
DFSReadWriteTest来自Apache Spark的例子:[”——阶级”,“org.apache.spark.examples.DFSReadWriteTest”,“dbfs: / FileStore /图书馆/ spark_examples_2_12_3_1_1.jar”,“/ dbfs / databricks-datasets / README.md”,“/ FileStore / /输出例子/”]
Python脚本:在源下拉菜单,也可以为Python脚本选择一个位置工作空间对于本地工作区中的脚本,或DBFS用于位于DBFS或云存储上的脚本。在路径文本框,输入Python脚本的路径:
工作空间:在选择Python文件对话框,浏览到Python脚本,单击确认.你的脚本必须是砖回购.
DBFS: DBFS或云存储上Python脚本的URI;例如,
dbfs: / FileStore / myscript.py.Delta Live Tables管道:在管道下拉菜单,选择一个现有的Delta活动表管道。
重要的
方法只能使用触发的管道管道的任务。不支持将连续管道作为作业任务。要了解BOB低频彩有关触发管道和连续管道的更多信息,请参见连续和触发管道.
Python轮:在包名文本框中,输入要导入的包。
mywheel - 1.0 - py2.py3 any.whl——没有.在入口点文本框中,输入启动车轮时要调用的函数。点击添加下依赖库添加运行任务所需的库。SQL:在SQL任务下拉菜单,选择查询,指示板,或警报.
请注意
的SQL任务已完成公共预览.
的SQL任务需要Databricks SQL和一个无服务器或pro SQL仓库.
查询:在SQL查询下拉菜单,选择任务运行时要执行的查询。在SQL仓库下拉菜单,选择无服务器或pro SQL仓库来运行任务。
指示板:在SQL仪表板下拉菜单,选择任务运行时要更新的仪表板。在SQL仓库下拉菜单,选择无服务器或pro SQL仓库来运行任务。
警报:在SQL警告下拉菜单,选择要触发评估的警报。在SQL仓库下拉菜单,选择无服务器或pro SQL仓库来运行任务。
印度生物技术部:看在Databricks作业中使用dbt有关如何配置DBT任务的详细示例。
预览
dbt任务完成公共预览.
配置任务运行的集群。在集群下拉菜单,选择其中之一新作业集群或现有的通用集群.
新作业集群:点击编辑在集群下拉菜单并完成集群配置.
现有通用集群:选择已存在的集群集群下拉菜单。若要在新页面中打开集群,请单击
 集群名称和描述右侧的图标。
集群名称和描述右侧的图标。
有关选BOB低频彩择和配置集群以运行任务的详细信息,请参见集群配置技巧.
您可以为任务传递参数。每种任务类型对格式化和传递参数都有不同的要求。
笔记本:点击添加并指定要传递给任务的每个参数的键和值。属性手动运行任务时,可以覆盖或添加其他参数运行带有不同参数的作业选择。参数设置笔记本电脑部件由参数的键指定。使用任务参数变量作为参数值的一部分传递一组有限的动态值。
JAR:使用json格式的字符串数组来指定参数。这些字符串作为参数传递给主类的主方法。看到配置JAR作业参数.
火花提交task:参数被指定为json格式的字符串数组。符合Apache Spark Spark -submit按照惯例,JAR路径后的参数被传递给主类的主方法。
Python脚本:使用json格式的字符串数组来指定参数。这些字符串作为参数传递,可以使用argparse模块。
Python轮:在参数下拉菜单,选择位置参数以json格式的字符串数组形式输入参数,或选择关键字参数>添加输入每个参数的键和值。位置参数和关键字参数都作为命令行参数传递给Python轮任务。
访问其他选项,包括依赖库、重试策略和超时,点击高级选项.看到编辑任务.
点击创建.
若要可选地设置作业计划,请单击编辑日程在工作细节面板。看到安排一份工作.
若要允许同一作业的多个并发运行,请单击编辑并发运行在工作细节面板。看到最大并发运行数.
要接收作业事件通知,请单击编辑电子邮件通知或编辑系统通知在工作细节面板。看到通知.
单击,可选地控制作业的权限级别编辑权限在工作细节面板。看到控制对作业的访问.
 .
.
 集群名称和描述右侧的图标。
集群名称和描述右侧的图标。如需添加其他任务,单击 在刚刚创建的任务下面。属性,则提供共享集群选项新作业集群对于前一个任务。还可以在创建或编辑任务时为每个任务配置集群。有关选BOB低频彩择和配置集群以运行任务的详细信息,请参见集群配置技巧.
在刚刚创建的任务下面。属性,则提供共享集群选项新作业集群对于前一个任务。还可以在创建或编辑任务时为每个任务配置集群。有关选BOB低频彩择和配置集群以运行任务的详细信息,请参见集群配置技巧.
运行作业
点击
工作流在侧栏中。选择作业并单击运行选项卡。您可以立即运行作业,也可以将作业安排在稍后运行。
如果具有多个任务的作业中的一个或多个任务不成功,则可以重新运行不成功任务的子集。看到修复不成功的作业运行.
 .
.修复不成功的作业运行
可以通过只运行不成功任务的子集和任何依赖任务来修复失败或取消的多任务作业。由于成功的任务和依赖于它们的任何任务都不会重新运行,因此该特性减少了从不成功的作业运行中恢复所需的时间和资源。
在修复作业运行之前,可以更改作业或任务设置。不成功的任务将使用当前作业和任务设置重新运行。例如,如果将路径更改为笔记本电脑或集群设置,则该任务将使用更新的笔记本电脑或集群设置重新运行。
您可以查看所有任务运行的历史记录在任务运行细节页面。
请注意
如果一个或多个任务共享一个作业集群,修复运行将创建一个新的作业集群;例如,如果最初的运行使用作业集群
my_job_cluster,第一次修复运行使用新的作业集群my_job_cluster_v1,允许您轻松查看初始运行和任何修复运行所使用的集群和集群设置。的设置my_job_cluster_v1是否与当前设置相同my_job_cluster.只有编排两个或多个任务的作业才支持修复。
的持续时间显示的值。运行TAB包含第一次运行开始的时间到最近一次修复运行结束的时间。例如,如果运行两次失败,第三次运行成功,则持续时间包括所有三次运行的时间。
修复一个不成功的作业运行:
点击
工作在侧栏中。在的名字列中,单击作业名称。的运行TAB显示活动运行和已完成运行,包括任何不成功的运行。
中未成功运行的链接开始时间的列已完成运行(过去60天)表格的作业运行详细信息页面出现。
点击修复运行.的修复作业运行对话框将出现,列出所有不成功的任务和将重新运行的任何依赖任务。
要为要修复的任务添加或编辑参数,请在修复作业运行对话框。参数修复作业运行对话框覆盖现有值。类中的键和值,可以将参数返回到其原始值修复作业运行对话框。
点击修复运行在修复作业运行对话框。
安排一份工作
为作业定义时间表:
点击编辑日程在工作细节面板,并设置计划类型来计划.
指定时间段、开始时间和时区。可选择显示Cron语法复选框中显示和编辑日程安排Quartz Cron语法.
请注意
Databricks强制作业调度触发的后续运行之间的最小间隔为10秒,而不管cron表达式中的秒配置如何。
您可以选择遵守夏令时或UTC的时区。如果您选择了一个遵守夏令时的地区,计时工作将被跳过,或者可能会在一两个小时内出现不开火的情况夏令时开始或结束的时间.要按每小时(绝对时间)运行,请选择UTC。
作业调度器不适用于低延迟作业。由于网络或云问题,作业运行有时可能会延迟几分钟。在这些情况下,计划作业将在服务可用时立即运行。
点击保存.
工具中也可以直接安排笔记本作业笔记本用户界面.
视图的工作
点击![]() 工作流在侧栏中。出现Jobs列表。Jobs页面列出了所有已定义的作业、集群定义、计划(如果有的话)以及最后一次运行的结果。
工作流在侧栏中。出现Jobs列表。Jobs页面列出了所有已定义的作业、集群定义、计划(如果有的话)以及最后一次运行的结果。
请注意
如果你有增加工作岗位限制启用此工作空间后,在jobs列表中只显示25个作业,以提高页面加载时间。使用左右箭头浏览完整的工作列表。
您可以在“工作列表”中过滤工作:
使用关键字。如果您为这个工作空间启用了增加的作业限制特性,则只支持对名称、作业ID和作业标记字段进行关键字搜索。
只选择你拥有的工作。
选择您有权限访问的所有作业。访问此过滤器需要这样做作业访问控制启用。
使用标签.若要搜索仅使用密钥创建的标记,请在搜索框中键入密钥。要搜索用键和值创建的标记,可以根据键、值或键和值同时搜索。例如,对于带有键的标记
部门还有价值金融,你可以搜索部门或金融寻找匹配的工作。要通过键和值进行搜索,输入键和值,用冒号分隔;例如,部门:财务.
还可以单击任何列标题,按该列对作业列表进行排序(降序或升序)。启用了增加的作业限制特性后,只能按顺序排序的名字,工作ID,或创建通过.默认的排序方式是按的名字按升序排列。
视图为作业运行
点击
工作流在侧栏中。在的名字列中,单击作业名称。的运行选项卡显示活动运行和已完成运行的表。

查看作业运行的详细信息,单击该链接以在开始时间的列已完成运行(过去60天)表格要查看此作业最近一次成功运行的详细信息,请单击最近一次成功运行(自动刷新).
单击,切换到矩阵视图矩阵.矩阵视图显示作业的运行历史记录,包括每个作业任务。
的工作运行矩阵的行显示运行的总持续时间和运行的状态。控件中的工具条上方悬停,可以查看运行的详细信息,包括开始时间、持续时间和状态工作运行行。
中的每个单元格任务行表示任务和任务对应的状态。若要查看每个任务的详细信息,包括开始时间、持续时间、集群和状态,请将鼠标悬停在该任务的单元格上。
作业运行和任务运行栏用颜色编码,以指示运行状态。成功运行为绿色,不成功运行为红色,跳过运行为粉红色。各个作业运行和任务运行栏的高度提供了运行持续时间的可视化指示。

Databricks最多可维护60天的作业运行历史记录。如果需要保存作业运行,Databricks建议在结果过期之前导出结果。有关更多信息,请参见导出作业运行结果.
查看作业运行详情
作业运行详细信息页面包含作业输出和到日志的链接,其中包括关于作业运行中每个任务的成功或失败的信息。方法访问作业运行详细信息运行为工作付费。控件中查看作业运行的详细信息运行选项卡中,单击运行的链接开始时间的列已完成运行(过去60天)表格回到运行选项卡为作业,单击工作ID价值。
单击任务可查看任务运行详情,包括:
运行任务的集群
任务的Spark UI
任务日志
任务的度量
单击工作ID值返回运行为工作付费。单击作业运行ID值返回作业运行详细信息。
查看最近的作业运行情况
您可以查看您有权访问的工作空间中所有作业的当前运行和最近完成的运行列表,包括由外部编排工具(如Apache workflow或Azure Data Factory)启动的运行。查看最近作业运行的列表。
点击
工作流在侧栏中。出现Jobs列表。单击工作运行选项卡。出现“作业运行”列表。
的工作运行列表显示:
运行的开始时间。
与运行关联的作业的名称。
作业作为用户名运行。
运行是由作业计划或API请求触发,还是手动启动。
当前正在运行的作业所消耗的时间,或已完成运行的总运行时间。
运行的状态
等待,运行,跳过,成功,失败的,终止,终止,内部错误,定时出,取消了,取消,或等待为重试.
查看作业运行详细信息,单击开始时间列为运行。控件中的作业名称,查看作业详细信息工作列。
导出作业运行结果
您可以导出所有作业类型的笔记本运行结果和作业运行日志。
导出笔记本运行结果
可以通过导出作业运行结果来持久化作业运行。对于笔记本作业运行,可以这样做出口一个渲染的笔记本,以后可以进口到你的Databricks工作区。
导出带有单个任务的作业的notebook运行结果。
在作业详细信息页面上,单击查看详细信息中运行的链接运行的列已完成运行(过去60天)表格
点击导出到HTML.
导出包含多个任务的作业的notebook运行结果。
在作业详细信息页面上,单击查看详细信息中运行的链接运行的列已完成运行(过去60天)表格
单击要导出的笔记本任务。
点击导出到HTML.
导出作业运行日志
您还可以导出作业运行的日志。您可以设置作业,通过作业API自动将日志传递到DBFS或S3。看到new_cluster.cluster_log_conf对象的请求体中的创建一份新工作操作(帖子/ /创建工作)。
编辑作业
一些配置选项可用于作业,其他选项可用于个人任务.例如,只能在作业上设置最大并发运行,而必须为每个任务定义参数。
更改作业的配置。
点击
工作流在侧栏中。在的名字列中,单击作业名称。
侧面面板显示工作细节.你可以更改时间表、集群配置、通知、最大并发运行数以及添加或更改标记。如果作业访问控制启用后,还可以编辑作业权限。
标签
要向作业添加标签或键:值属性,可以添加标签当你编辑工作的时候。中的作业可以使用标记筛选工作列表;例如,你可以使用a部门标签,过滤属于特定部门的所有作业。
请注意
因为作业标记不是为存储个人身份信息或密码等敏感信息而设计的,Databricks建议仅对非敏感值使用标记。
标记还会传播到作业运行时创建的作业集群,允许您将标记与现有的作业集群一起使用集群监控.
单击,添加或编辑标签+标签在工作细节侧板。您可以将标记作为键和值或标签添加。如果需要添加标签,请在关键字段,并将价值字段是空的。
最大并发运行数
此作业的最大并行运行次数。如果作业在尝试开始新的运行时已经达到活动运行的最大次数,Databricks将跳过运行。将此值设置为高于默认值1,以同时执行同一作业的多次运行。例如,如果您频繁地触发作业,并且希望允许连续的运行彼此重叠,或者希望触发因输入参数不同而不同的多次运行,那么这就很有用。
通知
要通知此作业的运行何时开始、完成或失败,可以添加一个或多个电子邮件地址或系统目的地(例如,webhook目的地或Slack)。
请注意
添加邮件通知:
点击编辑电子邮件通知.
点击添加.
输入电子邮件地址,然后单击要发送到该地址的每种通知类型的复选框。
如需输入其他通知邮箱地址,请单击添加.
如果不希望收到跳过作业运行的通知,请单击复选框。
点击确认.
将这些电子邮件通知与您最喜欢的通知工具集成,包括:
添加系统通知:
请注意
每种通知类型只能有三个系统目的地。
点击编辑系统通知.
在选择系统目标,选择一个目的地,然后单击要发送到该目的地的每种通知类型的复选框。
如需添加其他目标,单击选择系统目标再次选择一个目的地。
点击确认.
控制对作业的访问
作业访问控制使作业所有者和管理员能够对其作业授予细粒度权限。作业所有者可以选择哪些其他用户或组可以查看作业的结果。所有者还可以选择谁可以管理作业运行(立即运行和取消运行权限)。
看到作业访问控制获取详细信息。
编辑任务
设置任务配置项。
点击
工作流在侧栏中。在的名字列中,单击作业名称。
单击任务选项卡。
任务依赖关系
方法定义作业中任务的执行顺序取决于下拉菜单。您可以将此字段设置为作业中的一个或多个任务。
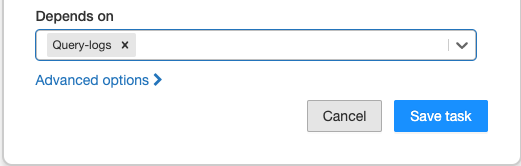
请注意
取决于如果作业仅由单个任务组成,则不可见。
配置任务依赖关系将创建任务执行的有向无环图(DAG),这是在作业调度器中表示执行顺序的常用方法。例如,考虑以下由四个任务组成的作业:
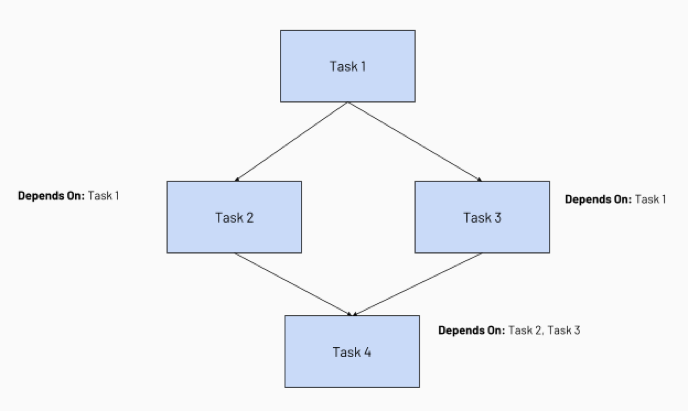
任务1是根任务,不依赖于任何其他任务。
任务2和任务3依赖于任务1先完成。
最后,Task 4取决于Task 2和Task 3是否成功完成。
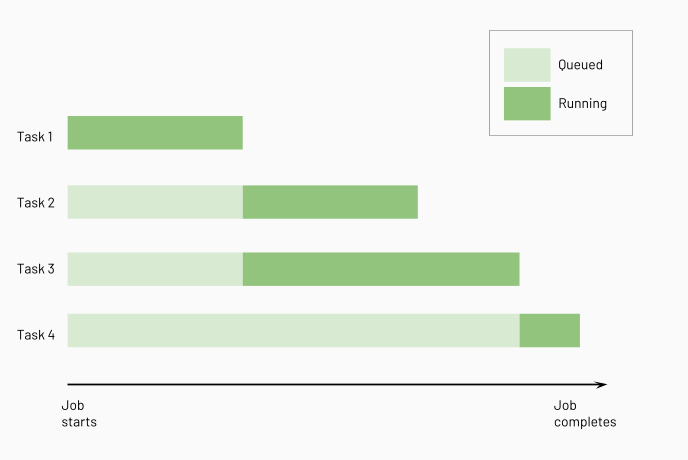
Databricks在运行下游任务之前运行上游任务,尽可能多地并行运行它们。下图说明了这些任务的处理顺序:
单个任务配置选项
单个任务有以下配置选项:
依赖库
在任务运行之前,将在集群上安装依赖库。必须设置所有任务依赖项,以确保在运行开始之前安装它们。
如需添加依赖库,单击高级选项并选择添加依赖库打开添加依赖库选择器。遵循以下建议库的依赖关系用于指定依赖项。
任务的通知
单击,添加任务成功或失败的邮件通知高级选项并选择编辑通知.在初始任务失败和任何后续重试时发送失败通知。
任务参数变量
可以将模板化变量作为任务参数的一部分传递到作业任务中。当作业任务运行时,这些变量将被适当的值替换。您可以使用任务参数值来传递作业运行的上下文,例如运行ID或作业的开始时间。
当作业运行时,被双花括号括起来的任务参数变量将被替换并追加到作为值的一部分包含的可选字符串值。例如,传递一个名为MyJobId值为my-job-6对于任何作业ID为6的运行,添加以下任务参数:
{“MyJobID”:“我的工作- {{job_id}}”}
双花括号的内容不会作为表达式计算,因此不能在双花括号内执行操作或函数。花括号内的空格没有被去掉,所以{{job_id}}不会被评估。
支持如下任务参数变量:
变量 |
描述 |
示例值 |
|---|---|---|
|
分配给作业的唯一标识符 |
1276862 |
|
分配给任务运行的唯一标识符 |
3447843 |
|
任务运行开始的日期。格式为UTC时区下的yyyy-MM-dd。 |
2021-02-15 |
|
创建并准备好集群后运行开始执行的时间戳。格式为从UTC时区的UNIX纪元开始的毫秒数,由返回 |
1551622063030 |
|
第一次尝试失败后试图运行任务的重试次数。第一次尝试时该值为0,每次重试时该值递增。 |
0 |
|
分配给具有多个任务的作业运行的唯一标识符。 |
3447835 |
|
分配给具有多个任务的作业的一部分的任务的唯一名称。 |
“clean_raw_data” |
您可以在任何任务中设置这些变量创造一个工作,编辑作业,或运行带有不同参数的作业.
还可以在作业中的任务之间传递参数任务值.看到在Databricks作业中的任务之间共享信息.
超时
一项工作的最长完成时间。如果作业在此时间内未完成,则Databricks将其状态设置为“超时”。
重试
一种策略,用于确定重试失败运行的时间和次数。单击,设置该任务的重试次数高级选项并选择编辑重试策略.重试间隔是以失败运行开始和后续重试运行之间的毫秒为单位计算的。
请注意
如果两者都配置超时而且重试,该超时时间适用于每次重试。
 并选择克隆的任务.
并选择克隆的任务. 旁边的任务路径,将该路径复制到剪贴板。
旁边的任务路径,将该路径复制到剪贴板。最佳实践
集群配置技巧
在操作作业时,集群配置非常重要。下面提供了关于选择和配置作业集群的一般指导,然后是针对特定作业类型的建议。
为您的作业选择正确的集群类型
新工作组别是作业或任务运行的专用集群。共享作业集群在第一个使用该集群的任务启动时创建并启动,在最后一个使用该集群的任务完成后终止。集群空闲时不会终止,只有在所有使用它的任务完成后才会终止。如果共享作业集群失败或在所有任务完成之前终止,则创建一个新集群。在任务启动时创建并启动作用域为单个任务的集群,在任务完成时终止集群。在生产环境中,Databricks建议使用新的共享或任务范围的集群,以便每个作业或任务在完全隔离的环境中运行。
在新集群上运行任务时,该任务被视为数据工程(任务)工作负载,取决于任务工作负载定价。在现有的通用集群上运行任务时,该任务被视为数据分析(通用)工作负载,受通用工作负载定价的约束。
如果选择已终止的现有集群,而作业所有者已终止可以重新启动许可, Databricks在作业计划运行时启动集群。
现有的通用集群最适合执行更新等任务指示板每隔一定的时间。
使用池可以减少集群启动时间
为了缩短新作业集群的开始时间,可以创建池并配置作业的集群以使用该池。
笔记本工作小贴士
笔记本单元格的总输出(所有笔记本单元格的总输出)受20MB大小限制。此外,单个单元格输出的大小限制为8MB。如果计算单元的总输出超过20MB,或者单个计算单元的输出大于8MB,则取消运行并标记为失败。
如果需要帮助查找接近或超过限制的单元格,请在通用集群上运行笔记本并使用它笔记本自动保存技术.
流媒体的任务
Spark Streaming作业的最大并发运行不应该设置为大于1。流作业应该设置为使用cron表达式运行“*****?"(每分钟)。
由于流任务是连续运行的,因此它应该始终是作业中的最后一个任务。
JAR的工作
要了解BOB低频彩有关将代码打包到JAR中并创建使用JAR的作业的详细信息,请参见在Databricks作业中使用JAR.
运行JAR作业时,请记住以下几点:
输出大小限制
作业输出(例如发送到stdout的日志输出)的大小限制为20MB。如果总输出的大小更大,则取消运行并标记为失败。
为了避免遇到这个限制,您可以通过设置spark.databricks.driver.disableScalaOutputSpark配置到真正的.缺省情况下,标志值为假.该标志控制Scala JAR作业和Scala笔记本的单元输出。如果使能该标志,Spark将不向客户端返回作业执行结果。该标志不会影响写入集群日志文件中的数据。建议仅对JAR作业的作业集群设置此标志,因为它将禁用笔记本结果。
使用终于尝试用于清理作业的块
考虑一个由两部分组成的JAR:
jobBody ()其中包含了工作的主要部分。jobCleanup ()哪些必须在之后执行jobBody ()该函数是否成功或返回异常。
举个例子,jobBody ()可以创建表,你可以使用吗jobCleanup ()放下这些桌子。
确保clean up方法被调用的安全方法是放一个终于尝试代码中的块:
试一试{jobBody()}最后{jobCleanup()}
你不应该试着清理使用sys.addShutdownHook (jobCleanup)或以下代码:
瓦尔cleanupThread=新线程{覆盖def运行=jobCleanup()}运行时.getRuntime.addShutdownHook(cleanupThread)
由于Databricks中Spark容器生命周期的管理方式,shutdown钩子不能可靠地运行。
配置JAR作业参数
使用JSON字符串数组将参数传递给JAR作业。看到spark_jar_task对象的请求体中的创建一份新工作操作(帖子/ /创建工作)。要访问这些参数,请检查字符串数组传递给主要函数。
库的依赖关系
Spark驱动程序有一些不能被覆盖的库依赖项。这些库的优先级高于与它们冲突的任何库。
要获得驱动程序库依赖项的完整列表,请在连接到相同Spark版本的集群(或具有您想要检查的驱动程序的集群)的笔记本中运行以下命令。
%sh ls /databricks/jars .
管理库依赖项
在为作业创建jar时处理库依赖关系时,一个很好的经验法则是将Spark和Hadoop列为提供依赖关系。在Maven上,添加Spark和Hadoop作为提供的依赖项,示例如下:
< >的依赖< groupId >org.apache.spark< / groupId >< artifactId >spark-core_2.11< / artifactId ><版本>tripwire> < /版本< >范围提供< / >范围< / >的依赖< >的依赖< groupId >org.apache.hadoop< / groupId >< artifactId >hadoop核心< / artifactId ><版本>1.2.1 "> < /版本< >范围提供< / >范围< / >的依赖
在sbt,将Spark和Hadoop作为提供的依赖项添加,示例如下:
libraryDependencies+ =“org.apache.spark”% %“spark-core”%“tripwire”%“提供”libraryDependencies+ =“org.apache.hadoop”% %“hadoop核心”%“1.2.1”%“提供”
提示
根据所运行的版本为依赖项指定正确的Scala版本。