火车毫升与砖AutoML UI模型
本文演示了如何训练使用的机器学习模型AutoML和砖机器学习的UI。AutoML UI步骤通过训练一个分类的过程中,回归或预测模型的数据集。
访问界面:
在侧边栏,选择New > AutoML实验。
您还可以创建一个新的AutoML实验的实验页面。
的配置AutoML实验页面显示器。在这个页面中,您配置AutoML过程,指定数据集,问题类型、目标或标签列预测,指标用来评估和实验运行,和停止条件。
需求
看到需求AutoML实验。
设置分类或回归问题
您可以设置一个分类或回归问题使用AutoML UI使用以下步骤:
在计算字段中,选择一个集群运行砖运行时毫升。
从毫升问题类型下拉菜单,选择回归或分类。如果你想预测一个连续的数值为每个观察,如年度收入,选择回归。如果你想分配每个观察到一组离散的类,如良好的信用风险或不良信贷风险,选择分类。
下数据集中,选择浏览。
导航到表你想使用和点击选择。表的模式出现了。
点击预测目标字段。出现一个下拉清单中显示的列模式。选择你想要的列模型来预测。
的实验名称字段显示了默认的名称。改变它,输入新名称。
您还可以:
指定额外的配置选项。
建立了预测问题
你可以建立一个预测问题使用AutoML UI使用以下步骤:
在计算字段中,选择一个集群运行砖运行时的10.0毫升或以上。
从毫升问题类型下拉菜单,选择预测。
下数据集,点击浏览。导航到表你想使用和点击选择。表的模式出现了。
点击预测目标字段。出现一个下拉菜单清单列所示的模式。选择你想要的列模型来预测。
点击时间列字段。出现一个下拉显示数据集列的类型
时间戳或日期。选择列包含时间序列的时间。对于multi-series预测,选择列(s),识别个人的时间序列时间序列标识符下拉。AutoML组数据,这些列不同时间序列和火车模型为每个独立系列。如果你离开这一领域的空白,AutoML假设数据集包含一个时间序列。
在预测的时间跨度和频率字段,指定时间段的数量在未来的AutoML应该计算预测的值。在左边的框中,输入整数周期预测的数量。在正确的盒子,选择单位。. .注意:使用Auto-ARIMA,时间序列必须有规律的频率(也就是说,任意两个点之间的时间间隔必须在整个时间序列相同)。频率必须匹配频率API调用中指定的单位或AutoML UI。AutoML处理丢失的时间步骤填写这些值的前一个值。
在砖运行时的10.5毫升以上,您可以保存预测结果。为此,指定一个数据库中输出数据库字段。点击浏览从对话框中选择一个数据库。AutoML将预测结果写入数据库中有一个表。
的实验名称字段显示了默认的名称。改变它,输入新名称。
您还可以:
指定额外的配置选项。
使用现有的功能表从砖特性的商店
在砖运行时11.3 LTS毫升以上,您可以使用功能表数据砖特性存储扩展输入训练数据集的分类和回归问题。
在砖运行时12.2 LTS毫升以上,您可以使用功能表数据砖特性存储扩展输入训练数据集所有AutoML问题:分类、回归分析和预测。
创建一个功能表,请参阅创建一个表在砖功能存储特性。
在配置AutoML实验完成之后,您可以选择一个功能表有以下步骤:
点击加入功能(可选)。
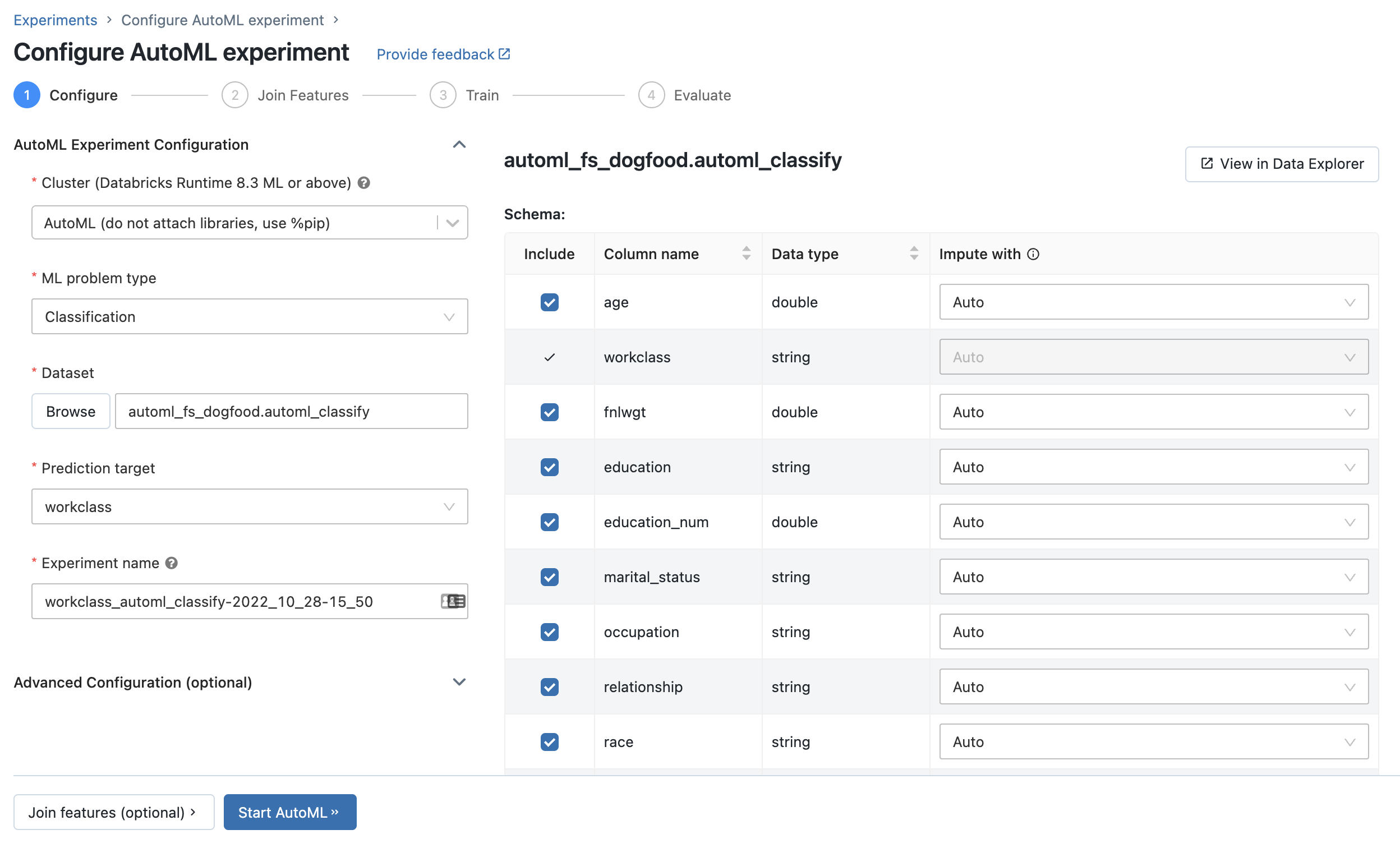
在加入附加功能页面,选择一个功能表功能表字段。
为每一个功能表主键,选择对应的查找的关键字。查找关键应列在训练数据集你提供AutoML实验。
为时间序列特征表,选择对应的时间戳查找的关键字。同样,时间戳查找关键应列在训练数据集你提供AutoML实验。
添加更多的功能表,单击添加另一个表并重复上述步骤。


高级配置
打开高级配置(可选)部分访问这些参数。
的评价指标主要指标用于分数。
在砖运行时的10.3毫升以上,可以排除培训框架考虑。默认情况下,AutoML火车模型使用框架下上市AutoML算法。
您可以编辑停止条件。默认停止条件:
预测实验,120分钟后停止。
在砖运行时10.5毫升和下面的分类和回归实验,停止后60分钟或完成200次试验之后,无论发生早。砖运行时的11.0毫升以上,试验的数量并不是作为一个停止条件。
在砖运行时10.1毫升以上的分类和回归实验,AutoML包含早期停止;它停止训练和调优模型如果验证指标不再是改善。
在砖运行时的10.1毫升以上,你可以选择一个时间列将数据进行训练、验证和测试按时间顺序(仅适用于分类和回归)。
在数据目录字段,您可以输入一个DBFS训练数据集保存的位置。如果你离开这个领域空白,保存作为训练数据集MLflow工件。
列选择
请注意
这个功能只用于分类和回归问题
在砖运行时的10.3毫升以上,您可以指定哪些列AutoML应该使用培训。排除一个列,取消它包括列。
你不能把列选为预测目标或作为时间列将数据。
默认情况下,所有的列都包括在内。
归责缺失值
在砖运行时10.4 LTS毫升以上,您可以指定null值是如何估算的。在UI中,从下拉的选择方法转嫁与列在表模式。
默认情况下,AutoML基于列类型选择一个归责方法和内容。
请注意
如果你指定一个非默认归责方法,AutoML不执行语义类型检测。
运行试验和监测结果
AutoML实验开始,点击开始AutoML。实验开始运行,AutoML培训页面出现。刷新表运行,点击 。
。
从这个页面中,您可以:
在任何时候停止实验。
打开数据探索的笔记本。
监控运行。
导航到页面任何跑。
砖运行时的10.1毫升以上,AutoML显示警告潜在问题的数据集,如不支持的列类型或高基数列。
请注意
砖做的最好的指示潜在的错误或问题。然而,这可能不全面、不可能抓住问题或者错误,你可能会搜索。请确认进行你自己的评论。
看到任何警告数据集,点击警告选项卡页面上的训练,或者在实验在实验完成后页。
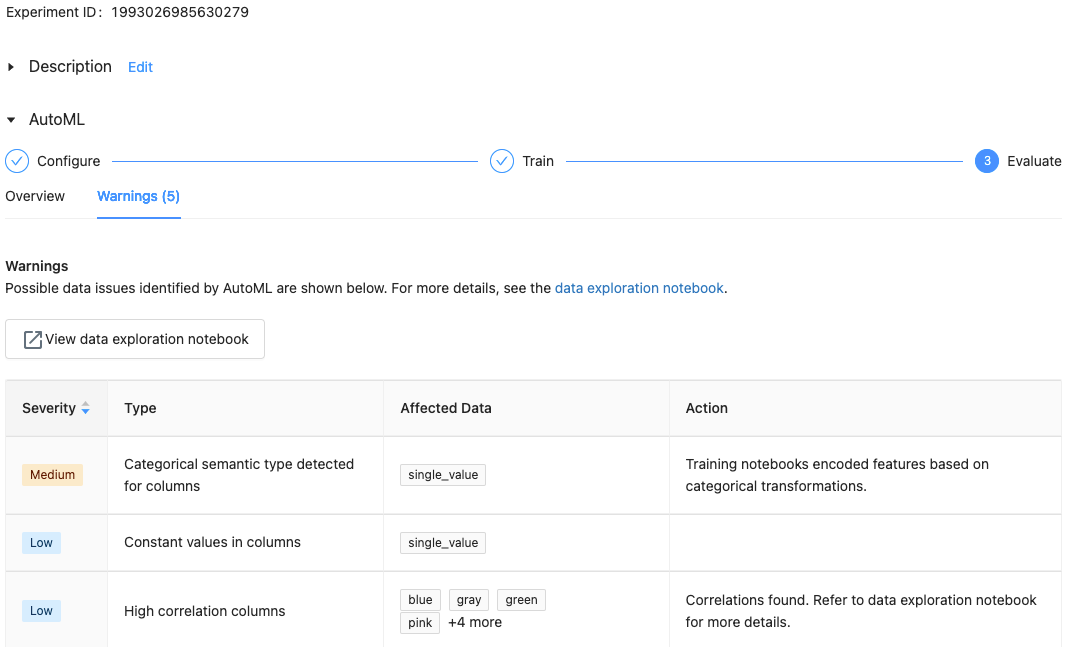
当实验完成后,您可以:
注册和部署模型与MLflow之一。
选择查看笔记本的最佳模型审查和编辑创建的最佳模式的笔记本。
选择视图数据探索的笔记本打开数据探索的笔记本。
搜索、过滤和排序的运行运行表。
看到任何运行的细节:
打开笔记本包含源代码的试运行,点击源列。
查看运行结果,点击模型列或开始时间列。试验运行页面出现显示信息(如参数、指标和标记)和工件产生的运行,包括模型。这个页面还包含代码片段,您可以使用与模型进行预测。
回到这个AutoML实验后,发现它在桌子上实验页面。每个AutoML实验的结果,包括数据探索和培训笔记,存储在一个databricks_automl文件夹中主文件夹的用户运行实验。
注册和部署模型
你可以注册和部署模型与AutoML界面:
选择的链接模型列模型的登记。当一个运行完成后,最好的模型(基于主要指标)是第一行。
的构件部分运行页面创建模型的运行显示。
选择
 注册模型模型注册。
注册模型模型注册。选择
 模型在侧边栏导航到注册中心模型。
模型在侧边栏导航到注册中心模型。选择您的模型在模型的表的名称。的注册页面模型显示器。从这个页面,你可以服务模型模型服务。
 注册模型
注册模型名为“pandas.core.indexes.numeric没有模块
当提供一个模型使用AutoML与模型构建服务,你可能会得到错误:没有模块命名“pandas.core.indexes.numeric。
这是由于一个不相容的熊猫版本AutoML和模型服务端点之间的环境。您可以通过运行解决这个错误add-pandas-dependency。py脚本。脚本编辑让和conda.yaml为你记录包括适当的模型熊猫依赖版本:熊猫= = 1.5.3
包括修改脚本
run_idMLflow运行你的模型的记录。注册模型MLflow模型注册表。
试服务MLflow模型的新版本。