工作特性表
在本节中:
跟踪特性血统和新鲜的信息,请参阅发现特性和跟踪特性的血统。
请注意
这时,砖特性的商店不支持统一目录metastore写作。团结Catalog-enabled工作空间,您可以编写功能表默认蜂巢metastore。
数据库和功能表名称不能包含连字符(-)。
为功能创建一个数据库表
在创建任何特性表之前,您必须创建一个数据库来存储它们。
%sql创建数据库如果不存在<数据库- - - - - -的名字>
功能表存储三角洲表。当你创建一个功能表create_table(功能存储客户端v0.3.6及以上)或create_feature_table(v0.3.5下面),您必须指定数据库名称。例如,这个参数创建一个增量表命名customer_features在数据库中recommender_system。
name = ' recommender_system.customer_features '
创建一个表在砖功能存储特性
请注意
你也可以注册一个存在差值表作为一个功能表。看到注册一个现有的三角洲表特性表。
创建一个功能表的基本步骤是:
编写的Python函数计算功能。每个函数的输出应该是一个Apache火花DataFrame独特的主键。主键可以包含一个或多个列。
通过实例化一个创建一个功能表
FeatureStoreClient和使用create_table(v0.3.6及以上)或create_feature_table(v0.3.5下面)。填充功能表使用
write_table。
从databricks.feature_store进口feature_tabledefcompute_customer_features(数据):“特性计算代码返回DataFrame customer_id“主键””通过由customer_id #创建功能表键#从compute_customer_features DataFrame输出的模式从databricks.feature_store进口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_table(的名字=“recommender_system.customer_features”,primary_keys=“customer_id”,模式=customer_features_df。模式,描述=“客户特性”)#一个替代方法是使用“create_table”并指定“df”的论点。#这段代码自动保存功能的底层δ表。# customer_feature_table = fs.create_table (#……# df = customer_features_df,#……#)#使用组合键,通过所有钥匙create_table调用# customer_feature_table = fs.create_table (#……# primary_keys = (“customer_id”、“日期”),#……#)#使用write_table写数据到功能表#覆盖模式全面刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆盖”)
从databricks.feature_store进口feature_tabledefcompute_customer_features(数据):“特性计算代码返回DataFrame customer_id“主键””通过由customer_id #创建功能表键#从compute_customer_features DataFrame输出的模式从databricks.feature_store进口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_feature_table(的名字=“recommender_system.customer_features”,键=“customer_id”,模式=customer_features_df。模式,描述=“客户特性”)#一个替代方法是使用“create_feature_table”并指定“features_df”的论点。#这段代码自动保存功能的底层δ表。# customer_feature_table = fs.create_feature_table (#……# features_df = customer_features_df,#……#)#使用组合键,通过所有钥匙create_feature_table调用# customer_feature_table = fs.create_feature_table (#……#键= (“customer_id”、“日期”),#……#)#使用write_table写数据到功能表#覆盖模式全面刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆盖”)从databricks.feature_store进口feature_tabledefcompute_customer_features(数据):“特性计算代码返回DataFrame customer_id“主键””通过由customer_id #创建功能表键#从compute_customer_features DataFrame输出的模式从databricks.feature_store进口FeatureStoreClientcustomer_features_df=compute_customer_features(df)fs=FeatureStoreClient()customer_feature_table=fs。create_feature_table(的名字=“recommender_system.customer_features”,键=“customer_id”,模式=customer_features_df。模式,描述=“客户特性”)#一个替代方法是使用“create_feature_table”并指定“features_df”的论点。#这段代码自动保存功能的底层δ表。# customer_feature_table = fs.create_feature_table (#……# features_df = customer_features_df,#……#)#使用组合键,通过所有钥匙create_feature_table调用# customer_feature_table = fs.create_feature_table (#……#键= (“customer_id”、“日期”),#……#)#使用write_table写数据到功能表#覆盖模式全面刷新功能表fs。write_table(的名字=“recommender_system.customer_features”,df=customer_features_df,模式=“覆盖”)
注册一个现有的三角洲表特性表
v0.3.8和上面,你可以注册一个现有的差值表作为一个功能表。表必须存在于metastore三角洲。
请注意
来更新注册表功能,你必须使用Python API特性存储。
fs。register_table(delta_table=“recommender.customer_features”,primary_keys=“customer_id”,描述=“客户特性”)
更新一个功能表
你可以更新一个功能表添加新特性或通过修改特定行基于主键。
以下功能表元数据不能更新:
主键
分区键
名称或类型的现有功能
新功能添加到现有的功能表
您可以将新功能添加到现有特性表两种方式中的一种:
更新现有的特性计算功能和运行
write_tableDataFrame返回。这个更新功能表模式和合并新特性值基于主键。创建一个新的特性计算函数值计算新特性。这个新的计算函数必须包含返回的DataFrame功能表的主键和分区键(如果定义)。运行
write_table与DataFrame编写新功能到现有的功能表,使用相同的主键。
只更新特定的功能表中的行
使用模式=“合并”在write_table。主键的行不存在DataFrame发送的write_table电话保持不变。
fs。write_table(的名字=“recommender.customer_features”,df=customer_features_df,模式=“合并”)
安排一个工作表更新功能
确保功能特性表中总是有最新值,砖建议你创建一个工作运行一个笔记本表定期更新功能,如每天。如果你已经有一个非正常的工作,你可以将它转换成一个安排的工作确保特性值总是最新的。
代码更新表使用一个特征模式=“合并”,如以下示例所示。
fs=FeatureStoreClient()customer_features_df=compute_customer_features(数据)fs。write_table(df=customer_features_df,的名字=“recommender_system.customer_features”,模式=“合并”)
存储过去值的日常功能
用一个复合主键定义一个功能表。包括主键的日期。例如,对于一个功能表store_purchases,您可以使用一个复合主键(日期,user_id)和分区键日期为有效的读取。
然后,您可以创建代码来读取从功能表过滤日期感兴趣的时期。保持功能表,建立定期工作写功能,或流新特性值到功能表中。
创建一个流特性计算管道更新功能
创建一个流特性计算管道,通过流媒体DataFrame作为参数write_table。这个方法返回一个StreamingQuery对象。
defcompute_additional_customer_features(数据):“返回流DataFrame“‘通过#没有显示customer_transactions=火花。readStream。负载(“dbfs: /事件/ customer_transactions”)stream_df=compute_additional_customer_features(customer_transactions)fs。write_table(df=stream_df,的名字=“recommender_system.customer_features”,模式=“合并”)
从功能表读取
使用read_table读特性值。
fs=feature_store。FeatureStoreClient()customer_features_df=fs。read_table(的名字=“recommender.customer_features”,)
搜索和浏览功能表
使用该特性存储UI搜索或浏览功能表。
在侧边栏,选择机器学习>特色商店存储界面显示功能。
在搜索框中,输入的全部或部分功能表的名称,功能,或一个数据源用于特性计算。您还可以输入的全部或部分键或值的标签。搜索文本是不区分大小写的。


得到特征表元数据
表元数据API获得功能取决于砖使用运行时版本。v0.3.6和上面使用get_table。v0.3.5和下面使用get_feature_table。
#这个例子使用v0.3.6以上# v0.3.5,使用“get_feature_table”从databricks.feature_store进口FeatureStoreClientfs=FeatureStoreClient()fs。get_table(“feature_store_example.user_feature_table”)
工作特性表标签
标签是键值,您可以创建和使用搜索功能表。您可以创建、编辑和删除使用特性存储UI或标签Python API特性存储。
 如果尚未打开。标签表出现。
如果尚未打开。标签表出现。
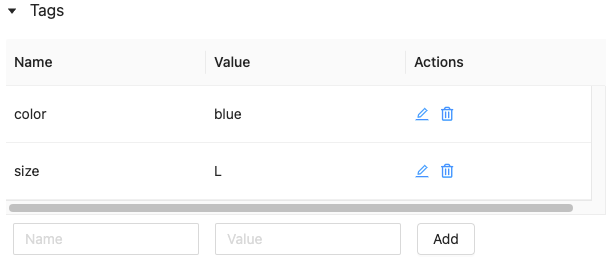
工作特性表标签使用Python特性存储API
在集群v0.4.1以上运行,您可以创建、编辑和删除标签使用Python API特性存储。
为一个功能表更新数据源
使用的数据源的功能存储自动跟踪计算功能。你也可以通过使用手动更新数据源Python API特性存储。
添加数据源使用Python特性存储API
下面是一些示例命令。有关详细信息,请参见API文档。
从databricks.feature_store进口FeatureStoreClientfs=FeatureStoreClient()#使用' source_type =“表”中添加一个表metastore作为数据源。fs。add_data_sources(feature_table_name=“点击”,data_sources=“user_info.clicks”,source_type=“表”)#使用source_type =“路径”的路径格式添加一个数据源。fs。add_data_sources(feature_table_name=“user_metrics”,data_sources=“dbfs: / FileStore / user_metrics.json”,source_type=“路径”)#使用' source_type =“定制”如果源不是一个表或一个路径。fs。add_data_sources(feature_table_name=“user_metrics”,data_sources=“user_metrics.txt”,source_type=“自定义”)
删除数据源使用Python特性存储API
有关详细信息,请参见API文档。
请注意
以下命令删除所有类型的数据源(“表”、“路径”和“自定义”)相匹配的名字来源。
从databricks.feature_store进口FeatureStoreClientfs=FeatureStoreClient()fs。delete_data_sources(feature_table_name=“点击”,sources_names=“user_info.clicks”)
删除一个功能表
你可以删除一个使用特性存储用户界面或功能表Python API特性存储。
请注意
删除功能表可以导致上游生产商和下游消费者意想不到的失败(模型、端点和安排工作)。
当你删除一个功能表使用API,底层三角洲表也下降了。当你删除一个UI功能表,你必须单独删除底层三角洲表。
删除一个表使用UI功能
在功能表页面,点击
 在功能表名和选择的权利删除。如果你没有可以管理权限功能表,你不会看到这个选项。
在功能表名和选择的权利删除。如果你没有可以管理权限功能表,你不会看到这个选项。
在删除功能表对话框中,点击删除来确认。
如果你也想的话底层三角洲表下降运行以下命令在一个笔记本上。
%sql下降表如果存在<功能- - - - - -表- - - - - -的名字>;
 在功能表名和选择的权利删除。如果你没有可以管理权限功能表,你不会看到这个选项。
在功能表名和选择的权利删除。如果你没有可以管理权限功能表,你不会看到这个选项。
支持的数据类型
支持以下功能商店PySpark数据类型:
IntegerTypeFloatTypeBooleanTypeStringType倍增式LongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType(v0.3.5及以上)DecimalType(v0.3.5及以上)MapType(v0.3.5及以上)
上面列出的数据类型支持特性类型常见的机器学习应用。例如:
你可以储存密度向量,张量和嵌入的
ArrayType。你可以存储稀疏向量,张量和嵌入
MapType。你可以存储文本
StringType。
功能界面显示元数据存储在特性数据类型:
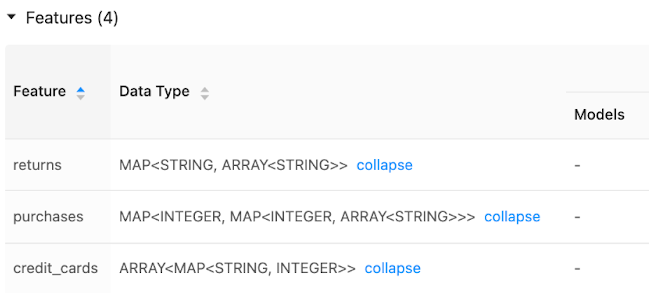
当发布到在线商店,ArrayType和MapType功能是存储在JSON格式。