Apache火花™教程:开始使用Apache火花砖
概述
随着组织创建更多的多样化和更加数据产品和服务,越来越多的机器学习的需要,可用于开发个人化操作,建议,和预测的见解。Apache火花机器学习库(MLlib)允许数据科学家专注于他们的数据问题和模型,而不是解决周围的复杂分布式数据(如基础设施、配置等)。
模块在本教程中,您将学习如何:
- 加载示例数据
- 准备ML算法和可视化数据
- 运行一个线性回归模型
- 评价一个线性回归模型
- 想象一个线性回归模型
我们也提供一个样的笔记本你可以导入访问和运行的所有代码示例包含在模块。
加载示例数据
开始使用机器学习最简单的方法是使用一个砖中可用数据集的例子/ databricks-datasets在砖工作区文件夹访问。例如,访问文件相比,城市人口的房屋平均销售价格,您可以访问该文件/ databricks-datasets /样本/ population-vs-price / data_geo.csv。
#使用火花CSV和选项指定数据源:# -文件的第一行是标题#——自动推断出数据的模式data = spark.read。格式(“csv”).option (“头”,“真正的”).option (“inferSchema”,“真正的”).load (“/ databricks-datasets /样本/ population-vs-price / data_geo.csv”)data.cache ()#缓存数据更快的重用查看这些数据以表格格式,而不是出口这些数据的第三方工具,您可以使用显示()命令你的砖笔记本。
显示器(数据)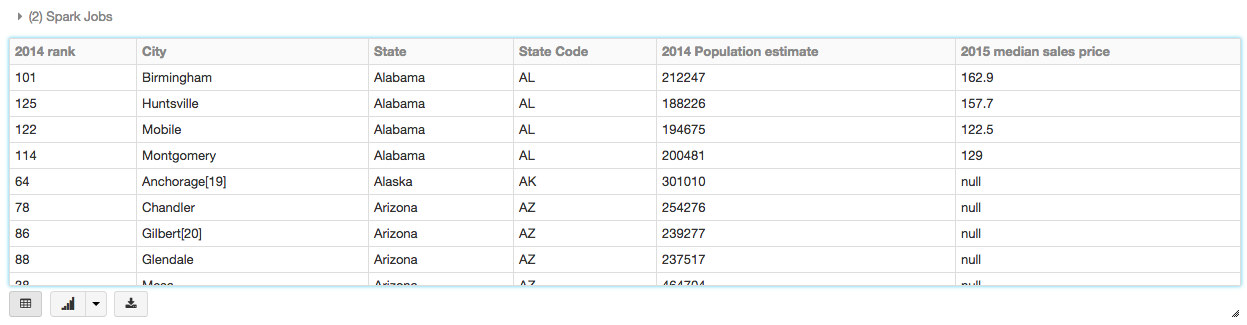
准备ML算法和可视化数据
在监督学习,如回归算法——你通常定义一个标签和一组特性。在这个线性回归的例子中,标签是2015年平均销售价格和功能是2014人口的估计。即使用特性(人口)预测的标签(销售价格)。
第一行用缺失值和重命名功能下降和标签列,取代空间_。
数据=data.dropna () #下降行与失踪值exprs=[坳(列).alias (column.replace (' ',“_”))为列在data.columns]简化的创造功能,注册一个UDF转换特性(2014 _population_estimate)到一个列向量VectorUDT类型和应用于列。
从pyspark.ml.linalg进口向量,VectorUDTspark.udf.register (“oneElementVec”,λd: Vectors.dense ([d]), returnType = VectorUDT ())tdata = data.select (* exprs) .selectExpr (“oneElementVec (2014 _population_estimate)功能”,“2015 _median_sales_price标签”)然后显示新的DataFrame:
显示器(tdata)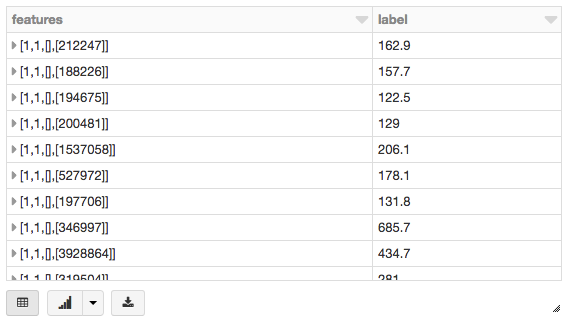
运行线性回归模型
在本节中,您使用不同的正则化参数运行两种不同的线性回归模型来确定这两个模型预测销售价格(标签)基于人口(特性)。
构建模型
#进口LinearRegression类从pyspark.ml.regression进口LinearRegression#定义LinearRegression算法lr = LinearRegression ()#适合2模型,使用不同的正则化参数模型= lr。fit(数据,{lr.regParam:0.0})modelB = lr。fit(数据,{lr.regParam:100.0})使用这个模型,你也可以通过使用预测变换()函数,添加一个新列的预测。例如,下面的代码将第一个模型(模型),并向您展示这两个标签(原销售价格)和预测(预测销售价格)基于特征(人口)。
#做出预测predictionsA = modelA.transform(数据)显示器(predictionsA)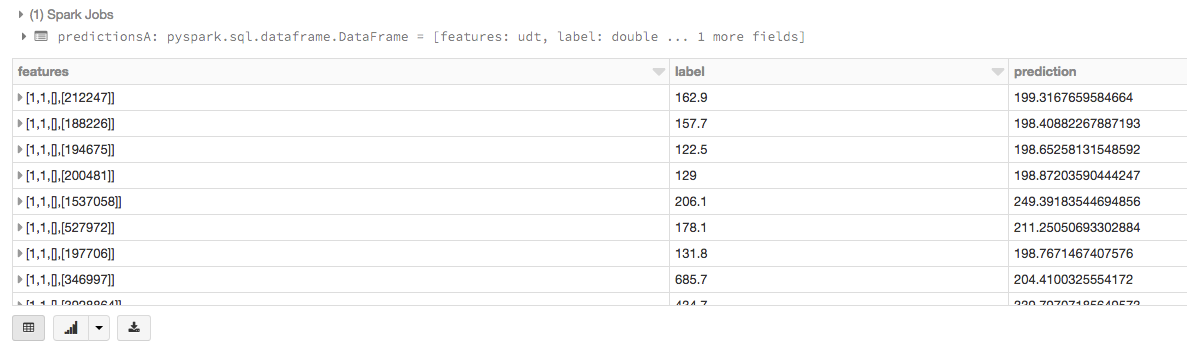
评估模型
进行回归分析,计算均方根误差使用RegressionEvaluator。这是Python代码来评估两个模型及其输出。
从pyspark.ml.evaluation进口RegressionEvaluator评估者= RegressionEvaluator (metricName =“rmse”)RMSE = evaluator.evaluate (predictionsA)打印(“模型:根均方误差= "+str(RMSE))#模型:根均方误差= 128.602026843
predictionsB = modelB.transform(数据)RMSE = evaluator.evaluate (predictionsB)打印(“ModelB:根均方误差= "+str(RMSE))# ModelB:根均方误差= 129.496300193可视化模型
作为许多机器学习算法是典型的,你要想象的散点图。因为砖支持大熊猫和ggplot,下面的代码创建了一个线性回归图使用熊猫DataFrame (pydf)和ggplot显示散点图和两个回归模型。
#进口numpy,熊猫,ggplot进口numpy作为np从熊猫进口*从ggplot进口*#创建Python DataFrame流行=数据。地图(λp: (p.features [0])).collect ()价格=数据。地图(λp: (p.label)) .collect ()predA = predictionsA.select (“预测”)。地图(λr: [0]).collect ()predB = predictionsB.select (“预测”)。地图(λr: [0]).collect ()#创建一个熊猫DataFramepydf = DataFrame ({“流行”:流行,“价格”:价格、“predA”:predA,“predB”:predB})可视化模型#创建散点图和两个回归模型使用ggplot(标度指数)p = ggplot (pydf aes (“流行”,“价格”)+geom_point(颜色=“蓝”)+geom_line (pydf aes (“流行”,“predA”),颜色=“红色”)+geom_line (pydf aes (“流行”,“predB”),颜色=“绿色”)+scale_x_log10 scale_y_log10 () + ()显示器(p)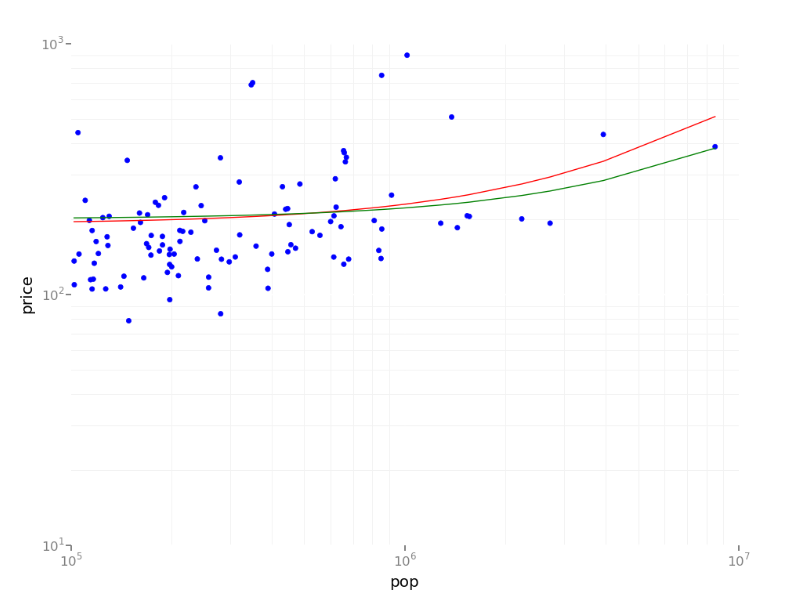
我们也提供一个样的笔记本你可以导入访问和运行的所有代码示例包含在模块。
