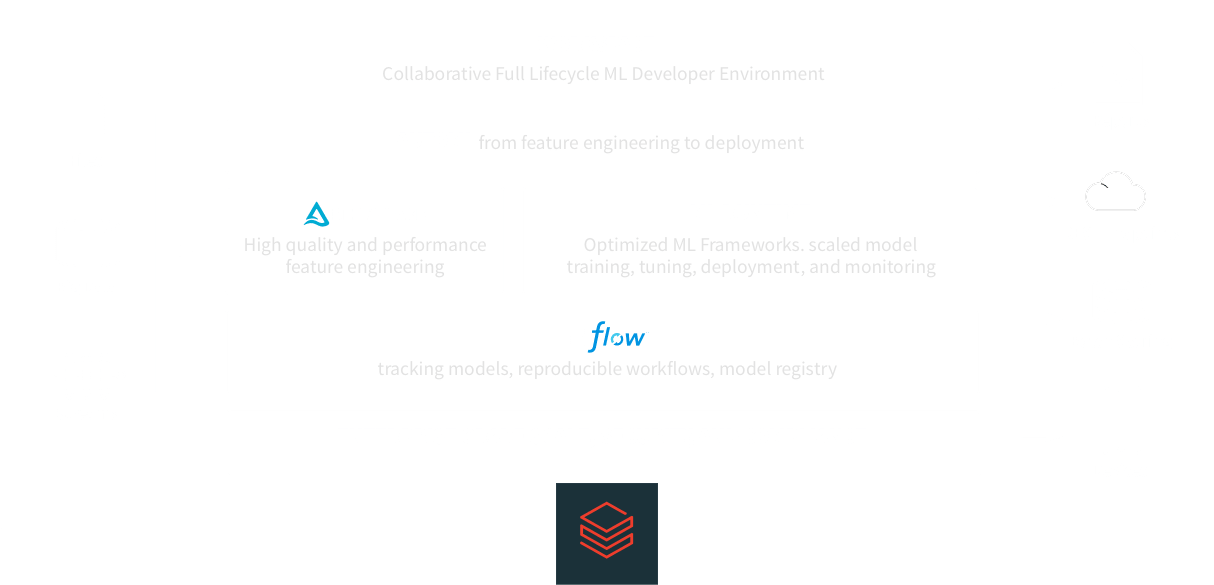
构建毫升模型是很困难的。将它们转移到生产困难。维护数据质量和模型精度的只是几个挑战。砖独特的流线毫升发展,从数据准备模型训练和部署规模。
表面上
DOPO

看到砖帮助合作准备数据,构建、部署和管理先进的ML模型,
从实验到生产,以前所未有的规模。




所有你需要完成工作是一个点击在工作区:数据集,毫升环境,笔记本,文件,实验中,模型,都可以安全地在一个地方。
协作笔记本和多语言支持(Python, R, Scala, SQL)更容易作为一个团队,共同工作,Git集成,版本控制,基于角色的访问控制,帮助你保持控制。或者干脆使用熟悉的工具如Jupyter实验室,PyCharm, IntelliJ, RStudio砖受益于无限的数据存储和计算。
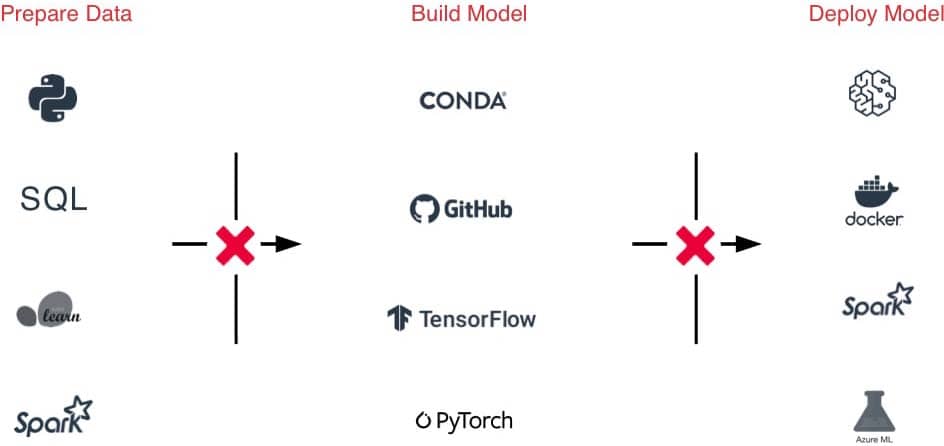
机器学习实践者火车模型在各种各样的数据形式和格式:小型或大型数据集,DataFrames、文本、图像、批处理或流。都需要特定的管道和转换
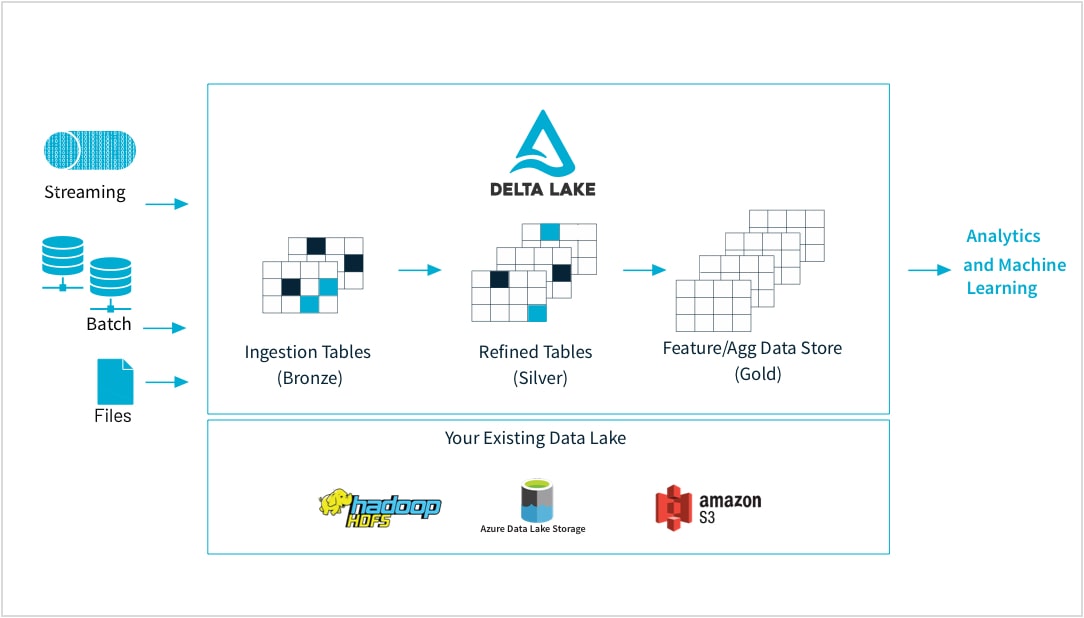
砖可以让您从任何来源摄取原始数据,合并批处理和流数据,安排转换、版本表和执行质量检查以确保原始数据和准备其余的组织分析。现在你可以在任何数据无缝地、可靠地工作,CSV文件或湖吸入大量数据,基于您的需要。
毫升框架发展正在以疯狂的速度使它具有挑战性维持毫升环境。砖毫升运行时提供了准备使用和优化毫升环境包括最受欢迎的ML框架(scikit-learn、TensorFlow等…)和Conda支持。
内置的AutoML像hyperparameter调优结果帮助更快,简化缩放帮助你毫不费力地从小型到大型数据所以你不必受限于计算有多少可用了。例如,火车速度的深度学习模型在整个集群分布计算HorovodRunner和挤压集群中的每个GPU的性能通过运行TensorFlow CUDA-optimized版本。

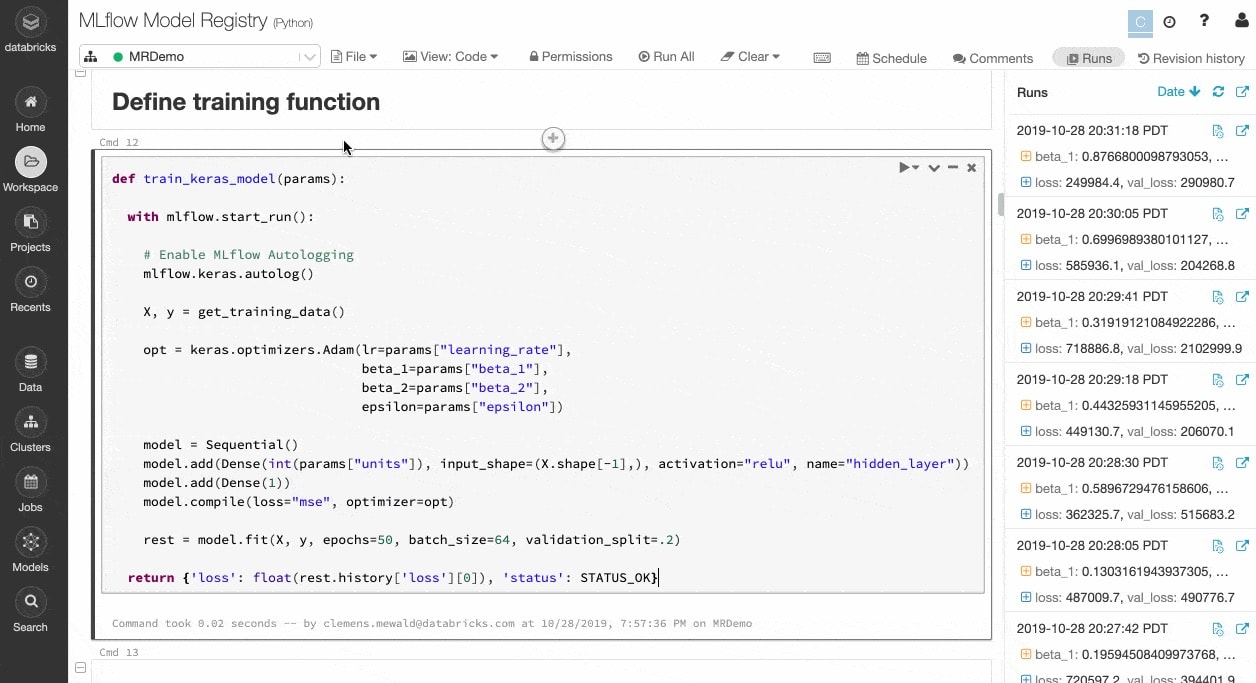
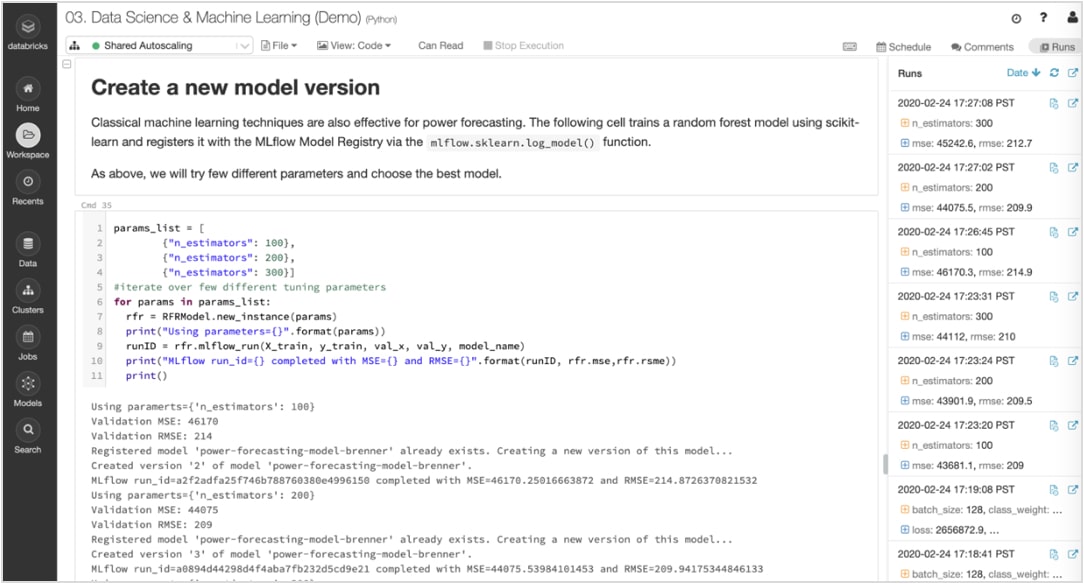
ML算法有许多可配置参数,是否单独或作为一个团队工作,很难跟踪哪些参数,代码和数据进入每个实验产生一个模型。
MLflow自动跟踪你的实验以及构件(如数据、代码、参数和结果为每个从笔记本内部训练。所以你可以很快看到乍一看之前的运行,比较结果,回到前一个版本的代码。一旦你已经确定了生产的最佳版本的模型,它在一个中央存储库提交注册部署和简化的传递。
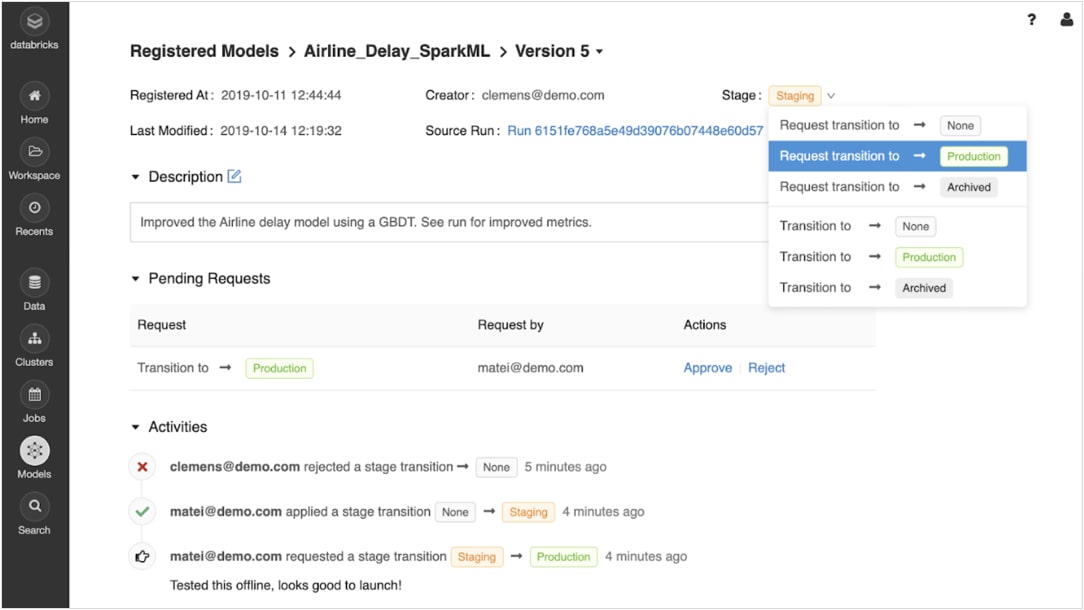
训练模型注册后,您可以通过生命周期的协作管理它们MLflow模型注册表。
模型可以通过不同阶段版本化和移动,如实验、分期、生产和存档。利益相关者可以评论和提交请求改变阶段。所有的生命周期管理与审批和管理工作流集成和基于角色的访问控制。
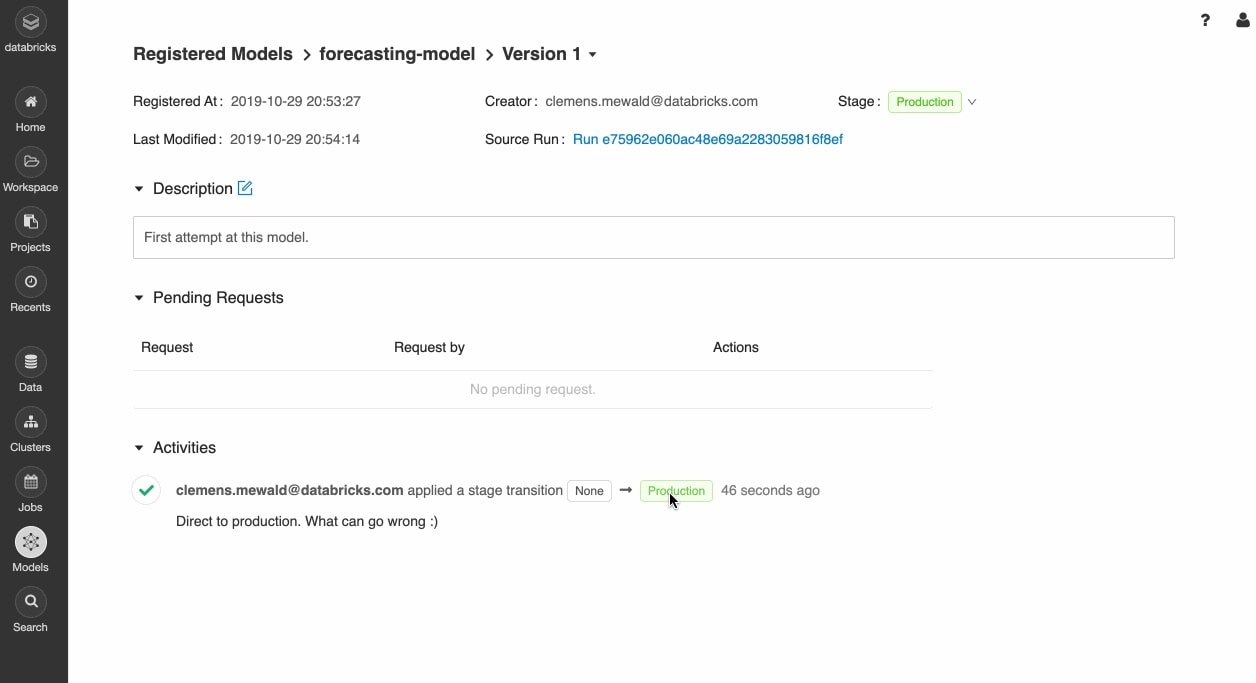
快速部署批量生产模型推理在Apache引发™,或REST api使用内置集成和码头工人容器,Azure毫升,亚马逊SageMaker。
实施生产模型使用工作调度器和auto-managed集群规模根据需要根据业务的需要。
迅速推动您的模型的最新版本生产和监控模型与三角洲湖和MLflow漂移。
![]()
砖,Quby已经能够兑现自己的任务:利用机器学习来改善他们的客户的舒适和生活,帮助减少能源消耗。
Pronto每cominciare ?