
改善客户体验与事务浓缩

零售银行业格局已经发生了巨大的变化在过去五年内开放银行应用程序的可访问性,主流采用Neobanks和最近的科技巨头引入金融服务行业。根据《福布斯》最近的一篇文章千禧一代现在占全球员工总数的75%,和71%声称他们“去看牙医比建议从他们的银行”。竞争已经从9点到下午5点实体分支网络赢得了数字精明的消费者越来越沉迷于简单的观念,效率和透明度。新一代不再感兴趣通用金融部门经理的建议,但要控制自己的财务状况与个性化的见解,在真正的时间,通过舒适的移动银行应用程序。为了保持竞争力,银行必须提供一个引人入胜的移动银行的经验,通过个性化的见解,超越了传统银行的建议,制定财务目标和报告功能——所有的高级分析地理空间或自然语言处理(NLP)。
这些功能可能特别深刻的考虑到纯粹的银行已经在他们的指尖的数据量。根据2020年的研究《尼尔森报告》每天,大约10亿卡交易发生在世界各地(1亿交易仅在美国)。10亿数据点,每天可以利用来造福消费者,奖励他们的忠诚和使用他们的数据和更个性化的见解。另一方面,必须获得10亿数据点,策划、加工、分类、更符合实际的,需要一种分析环境,同时支持数据和AI和促进合作工程师、科学家和业务分析师。SQL不改善客户体验。人工智能。
在这个新的解决方案加速器(公开笔记本报告结束时这个博客),我们证明lakehouse架构使银行,开放银行聚合器和付款处理器解决零售银行业务的核心挑战:商人分类。通过使用笔记本和业界最佳实践,我们使我们的客户能够与上下文信息丰富交易(品牌、类别),可以用于客户细分等下游用例或欺诈预防。
理解卡交易
信用卡交易的动力是复杂的。每个操作涉及到销售终端,一个商人,一个付款处理器网关,收购银行信用卡处理器网络,发行银行和消费者帐户。许多实体参与交易卡的授权和结算,上下文信息从一个商人带到一个零售银行是复杂的,有时会误导和经常反直觉的对最终消费者和需要使用先进的分析技术提取清晰的品牌和商家的信息。首先,任何商家需要达成商户类别代码(MCC),一个4位数的号码用于分类的业务类型的商品或服务提供(见列表)。MCC本身通常是不够理解任何业务的真实性质(如大型零售商销售不同的商品),因为它往往是太宽或太具体。

除了一个复杂的分类,MCC有时是不同的销售终端从一个点到另一个地方,即使相同的商人。仅仅依靠MCC代码是不够的足以让一个卓越的客户体验,必须结合其他上下文,例如事务叙事和商人描述完全理解品牌,位置和购进货物的性质。但这是难题。事务的叙述和商人是一个自由形式的文本描述填写由商人没有共同的准则或行业标准,因此要求数据科学方法这数据不一致的问题。在这个解决方案加速器,我们演示文本分类技术等fasttext可以帮助企业更好地理解品牌隐藏在任何事务叙述给出一个参考的数据集的商人。距离是事务描述“星巴克伦敦1233-242-43 2021”公司“星巴克”吗?
了解一个重要方面是我们手头多少数据学习文本模式。事务数据时,遇到一个大的差距是很常见的可用数据不同的商人。这是完全正常的,它是由购物模式的客户基础。例如,它是可以预料到的,我们将更容易获得比街角小店交易仅仅由于亚马逊的事务交易发生的频率在这些各自的商人。自然,事务数据将遵循幂律分布(如下代表)的大部分数据来自几个商人。
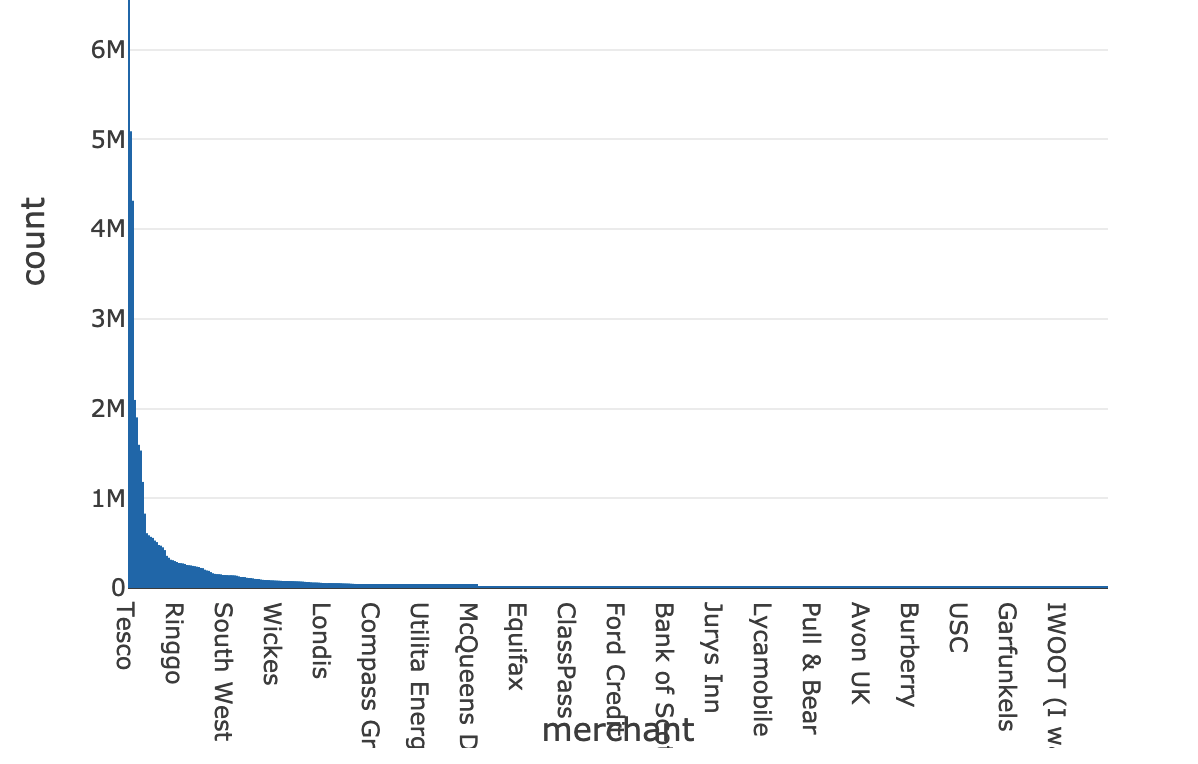
我们的模糊字符串匹配方法
接近这个问题从字符串模糊匹配的挑战就是这么简单,更大的部分描述和商人字符串不匹配。任何绳距离将是非常高的,事实上,任何相似性很低。如果我们改变了我们的角呢?有没有更好的方法来模拟这个问题?我们认为,上述问题将会更好的被文档建模(自由文本)分类而不是字符串相似性。加速器在这个解决方案中,我们演示fasttext帮助我们有效地解决description-to-merchant翻译和解锁高级分析用例。
最近一个流行的方法是将文本数据表示为数值向量,使两个著名概念出现:word2vec和doc2vec (看博客)。Fasttext带有它自己的内置逻辑,将文本转换成向量表示基于两种方法,cbow和skipgrams (看文档),根据您的数据的性质,一种表示会表现得更好。我们的重点不是解剖的内部逻辑用于文本向量化,而是实际使用的模型来解决文本分类问题当我们面对成千上万的类可以分为(商人)文本。
推广方法卡交易
数据模型的好处最大化,卫生处理和分层是关键!机器学习(ML)与清洁数据简单的尺度和性能更好。有鉴于此,我们将确保我们的数据分层对商人。我们想确保我们可以提供一个类似的数据量/商业模型借鉴。这将避免这种情况的模型会偏向某些商人仅仅因为消费者支出的频率。为此我们使用以下代码:
结果= data.sampleBy (自我.target_column sample_rates)确保火花sampleBy分层方法,它需要一个列的值会发生分层,以及地层词典标签样本映射。在我们的解决方案中,我们确保任何商人拥有超过100行可用带安全标签的数据保存在训练语料库。我们也保证零类(未被认识的商人)占10:1比例是由于高诉困惑在交易,我们的模型不能学习。我们都保持零类作为一个有效的分类选项,以避免通货膨胀的假阳性。另一个同样有效的方法是调整每个类有一个阈值概率类的我们不再信任车型标签,默认为“未知的商人”标签。这是一个更复杂的过程,因此,我们选择了一个更简单的方法。您应该只介绍复杂性毫升和AI如果它带来明显的价值。
从清洁的角度来看,我们要确保我们的模型不是由时间扼杀学习无关紧要的数据。这样的一个例子是日期和金额可能包含在事务的叙述。我们不能提取merchant-level信息基于交易发生的日期。如果我们再加上考虑,商家不遵循相同的标准表示日期时,我们立即得出结论,日期可以安全地删除这个动作的描述和模型将有助于更有效地学习。BOB低频彩为了这个目的,我们有我们的清洗策略基于的信息Kaggle博客。数据清理的参考,我们现在的全部逻辑图如何我们清洗和标准化的数据。这是一个合乎逻辑的管道这个解决方案的最终用户可以很容易地修改和/或扩展的行为,其中任何一个步骤和实现定制的经验。
正确的数据表示后,我们利用MLflow的力量,Hyperopt和Apache火花™训练fasttext模型与不同的参数。MLflow使我们能够跟踪运行许多不同的模型和比较。MLflow的关键功能是其丰富的UI,可以比较不同毫升数以百计的模型运行在许多参数和指标:
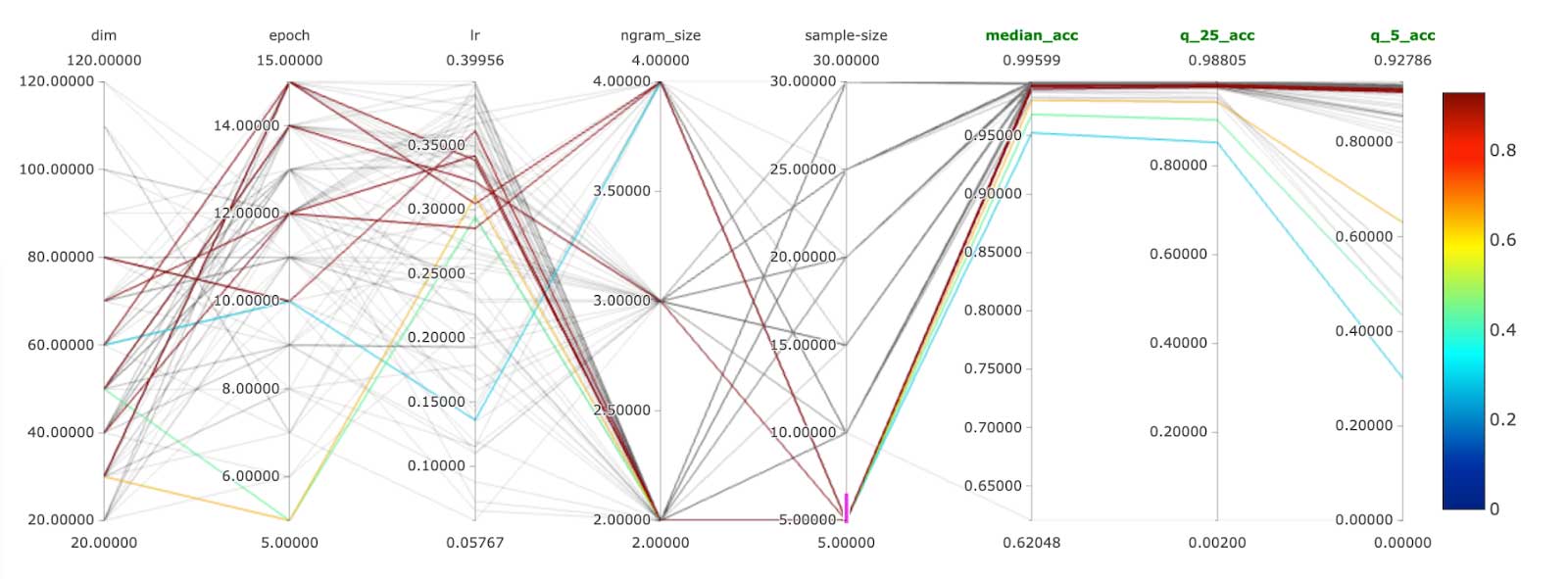
对于一个参考如何参数化和优化fasttext模型,请参考文档。在我们的解决方案中,我们使用了train_unsupervised培训方法。鉴于商人的数量我们在处理(1000 +),我们意识到我们不能正确比较模型基于一个度量值。生成一个与1000 +类混淆矩阵的性能可能不会带来预期的简单解释。我们已经选择了一个每百分位精度的方法。我们模型相比,基于性能值准确性,最差最差第25百分位和第五百分位。这给了我们一个了解我们的模型的性能分布在我们的商业空间。
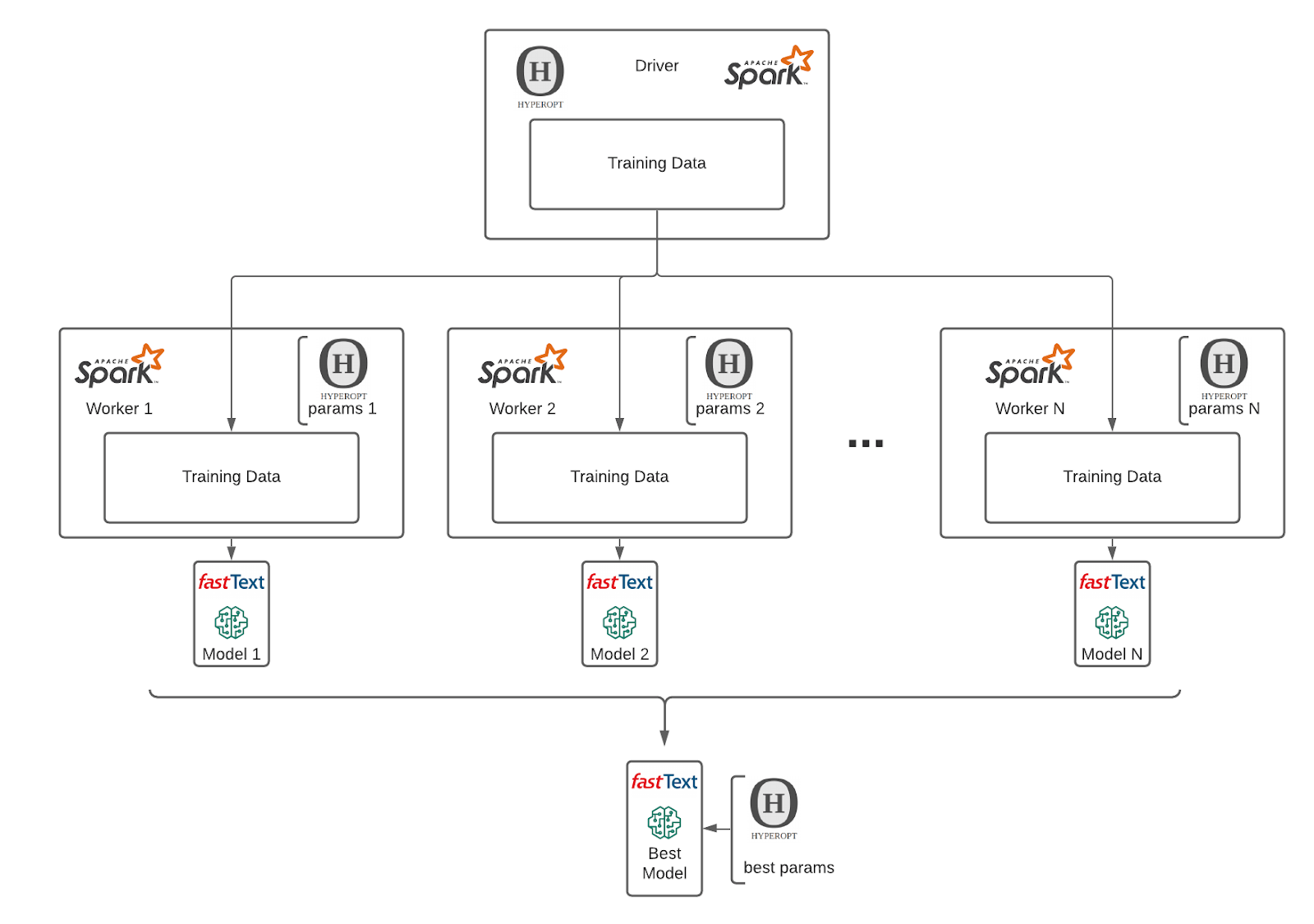
作为我们的解决方案的一部分我们实现了与MLflow fasttext模型的集成,能够负载模型通过MLflow api和大规模应用的最佳模式通过预先包装好的火花udf如下代码:
logged_model =f 'runs: /{run_id}/模型”loaded_model = mlflow.pyfunc.load_model (logged_model)loaded_model_udf = mlflow.pyfunc.spark_udf (火花,model_uri = logged_model result_type =“字符串”)
spark_results = (validation_data.withColumn (“预测”loaded_model_udf (“clean_description”)))这种程度的简单应用解决方案是至关重要的。一个可以用几行代码改历史交易数据一旦模型训练和校准。这几行代码解锁前所未有的客户数据分析。分析师们终于可以专注于交付复杂先进的数据分析用例流或批处理,如客户生命周期价值、定价、客户细分、客户保持和许多其他分析的解决方案。
性能、性能、性能!
所有这些努力背后的原因很简单:获得一个事务浓缩系统,可以自动执行的任务。和一个值得信赖的解决方案在自动运行模式下,表现在高水平/商人。我们有训练有素的几百个不同的配置和比较这些模型专注于低表演者商人。我们的第五百分位精度达到最低在93%左右的准确;我们的平均精度达到99%。这些结果给我们信心提出自动化的商家分类以最少的人力监督。
这些结果都是伟大的,但一个问题出现在我的脑海里。我们overfitted吗?过度拟合只是一个问题当我们期望我们模型的泛化,意味着当我们训练数据只代表一个非常小的样本的现实和新到达的数据非常不同于训练数据。在我们的例子中,我们有很短的文件每个商人相当简单的语法。另一方面,fasttext生成ngrams skipgrams,事务的描述,这种方法可以提取有用的知识。这两个因素结合表明,即使我们这些向量overfit,天生是不包括一些令牌从知识表示,我们将概括。简单地说,对过度拟合模型是足够健壮我们的应用程序的上下文中。值得一提的是,所有的指标为模型评价计算在一组400000个事务,这从训练数据集是不相交的。
这是有用的,如果我们没有标记的数据集
这是一个很难回答的问题,“是”或“否”。然而,作为我们实验的一部分,我们已经制定的观点。与我们的框架,答案是肯定的。我们已经完成几毫升模型训练活动与不同数量的标签行/商人。杠杆MLflow, Hyperopt和火花训练不同的模型和不同的参数和不同的模型和不同的参数在不同数据大小和交叉引用和比较他们在一套共同的指标。
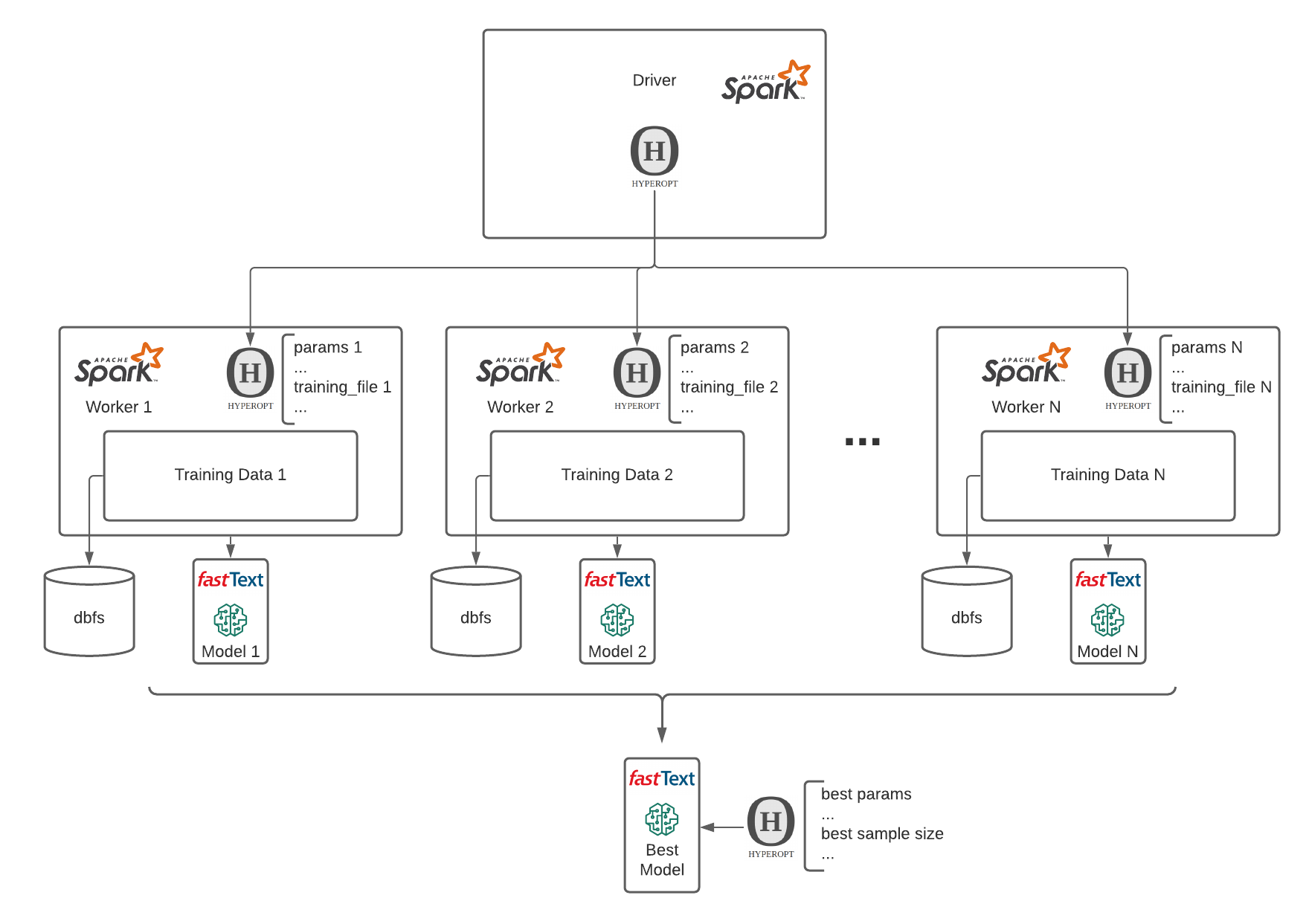
这种方法使我们回答这个问题:什么是最小的标记的行数/商人,我需要训练该模型和我的历史交易数据分数吗?答案是:低至50岁,是的,50 !
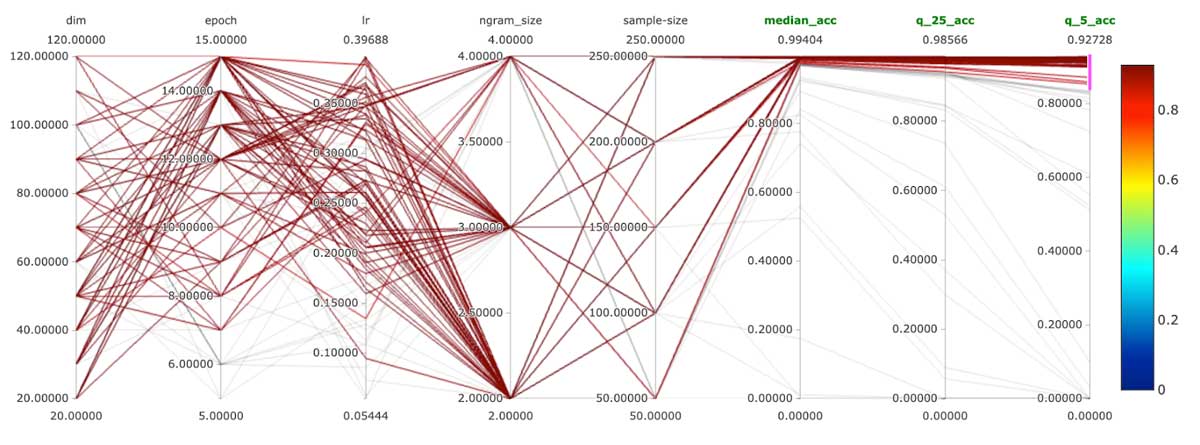
只有50记录/商人,我们保持着99%的平均精度和第五百分位最低性能降低了只有几个百分点至85%。另一方面,100条记录/商业数据集的结果是91%的准确率最低的第五百分位。这只表明特定的品牌有更多的困惑的语法描述和可能需要更多的数据。底线是,系统操作在伟大的平均性能和合理的性能边界情况仅有50行/商人。这使得商家的进入障碍分类非常低。
事务浓缩优越的订婚
而零售银行业正处于转变的基础上提高消费者的期望在个性化和用户体验,银行和金融机构可以学习大量从其他行业,从批发到零售的消费者参与策略。在媒体行业,像Netflix公司,亚马逊和谷歌有设置表为新进入者和遗留球员无摩擦,在所有渠道上个性化的体验。行业已经完全从“内容为王”的经验,专业的基于用户偏好和细粒度的部分信息。建立一个个性化的体验,消费者获取价值构建信任和确保你仍然是一个选择的平台在市场拥有无限数量的供应商和消费者的选择。bob体育客户端下载
学习先锋媒体行业,零售银行业务的公司,专注于银行经验而不是事务数据不仅能够吸引年轻一代的心灵和思想,但将创建一个移动银行体验这样的人,想回去。在这个模型中以个人客户,任何新的信用卡交易将产生额外的数据点,可以进一步利用效益最终消费者,推动更多的个性化,更多的客户互动,更多的交易,等等——所有同时减少生产和不满。
尽管这里讨论的商家分类技术没有解决个性化金融的全貌,我们相信这个博客中概述的技术能力是实现这一目标最重要的。一个简单的UI为客户提供上下文信息(如上图),而不是一个简单的SQL转储”在一个移动设备将朝着这个转变的催化剂。
在未来解决方案加速器,我们计划利用这个能力进一步推动个性化和可行的见解,如客户细分、消费目标,和行为消费模式(检测生活事件),学习更多的从我们的终端消费者,因为他们越来越投入,确保这些新见解的增值效益。
在这个加速器中,我们展示了零售银行需要极大地改变他们的事务数据的方法,从一个OLTP模式对OLAP数据仓库的方法在数据湖,和需要lakehouse架构应用毫升的产业规模。我们也处理的非常重要的因素进入障碍实现这个解决方案的有关训练数据量。与我们的方法,进入门槛从未降低(50交易的商人)。
试试以下笔记本砖来加速你的数字的银行今天和策略联系我们了解更BOB低频彩多关于我们如何帮助客户提供类似的用例。