





使用Facebook Prophet和Apache Spark进行大规模细粒度时间序列预测:针对Spark 3更新
时间序列预测的进步使零售商能够产生更可靠的需求预测。现在的挑战是在……
2021年4月6日 在工程的博客
时间序列预测的进步使零售商能够产生更可靠的需求预测。现在的挑战是及时地产生这些预测,并以允许企业对产品库存进行精确调整的粒度级别进行预测。利用Apache火花™而且Facebook的先知面对这些挑战,越来越多的企业发现他们可以克服过去解决方案的可伸缩性和准确性限制。
直接到预测加速器在这篇文章中引用。要查看Spark 2.0的此解决方案,请阅读这里是博客原创文章。
在这篇文章中,我们将讨论时间序列预测的重要性,可视化一些样本时间序列数据,然后构建一个简单的模型来展示Facebook Prophet的使用。一旦你能够轻松地构建单个模型,我们将结合Facebook Prophet和Spark的魔力,向你展示如何同时训练数百个模型,允许你以迄今为止很少实现的粒度级别为每个单独的产品-商店组合创建精确的预测。
为了更好地预测产品和服务的需求,提高时间序列分析的速度和准确性对零售商的成功至关重要。如果商店中放置了太多的产品,货架和储藏室空间就会紧张,产品可能会过期,零售商可能会发现他们的财务资源被积压在库存中,使他们无法利用制造商产生的新机会或消费者模式的转变。如果商店里的产品太少,顾客可能无法购买他们需要的产品。这些预测错误不仅会立即导致零售商的收入损失,而且随着时间的推移,消费者的挫折感可能会驱使他们转向竞争对手。
一段时间以来,企业资源规划(ERP)系统和第三方解决方案已经为零售商提供了基于简单时间序列模型的需求预测能力。但随着技术的进步和行业压力的增加,许多零售商正在寻求超越线性模型和更传统的算法。
提供的新功能,例如Facebook的先知,正在从数据科学界兴起,公司正在寻求将这些机器学习(ML)模型应用于其时间序列预测需求的灵活性。
 这种摆脱传统预测解决方案的趋势,要求零售商等不仅要在需求预测的复杂性方面发展内部专业知识,还要在及时生成数十万甚至数百万ML模型所需的工作的有效分配方面发展专业知识。幸运的是,我们可以使用Spark来分发这些模型的训练,从而可以预测产品和服务的需求,以及每个地点对每种产品的独特需求。
这种摆脱传统预测解决方案的趋势,要求零售商等不仅要在需求预测的复杂性方面发展内部专业知识,还要在及时生成数十万甚至数百万ML模型所需的工作的有效分配方面发展专业知识。幸运的是,我们可以使用Spark来分发这些模型的训练,从而可以预测产品和服务的需求,以及每个地点对每种产品的独特需求。
为了演示使用Facebook Prophet为单个商店和产品生成细粒度的需求预测,我们将使用一个公开可用的数据集Kaggle。它由10家不同商店50种商品5年的每日销售数据组成。
首先,让我们看看所有产品和商店的整体年度销售趋势。正如你所看到的,产品销售总额逐年增长,没有明显的趋同迹象。
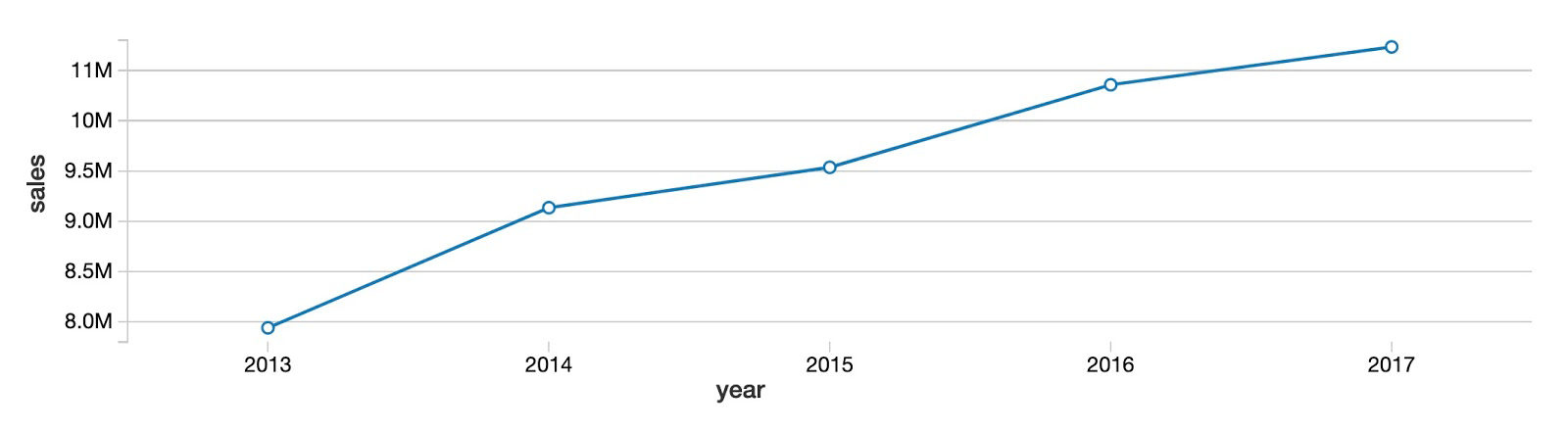
接下来,通过每月查看相同的数据,很明显,同比上升的趋势并不是每个月都在稳步发展。相反,有一个明确的季节模式,夏季的几个月是高峰,冬季的几个月是低谷。的内置数据可视化特性Databricks协作笔记本,我们可以将鼠标移到图表上,查看每个月的数据值。
在工作日层面,销量在周日达到峰值(工作日0),随后在周一(工作日1)出现大幅下降,然后在一周的其余时间稳步回升。
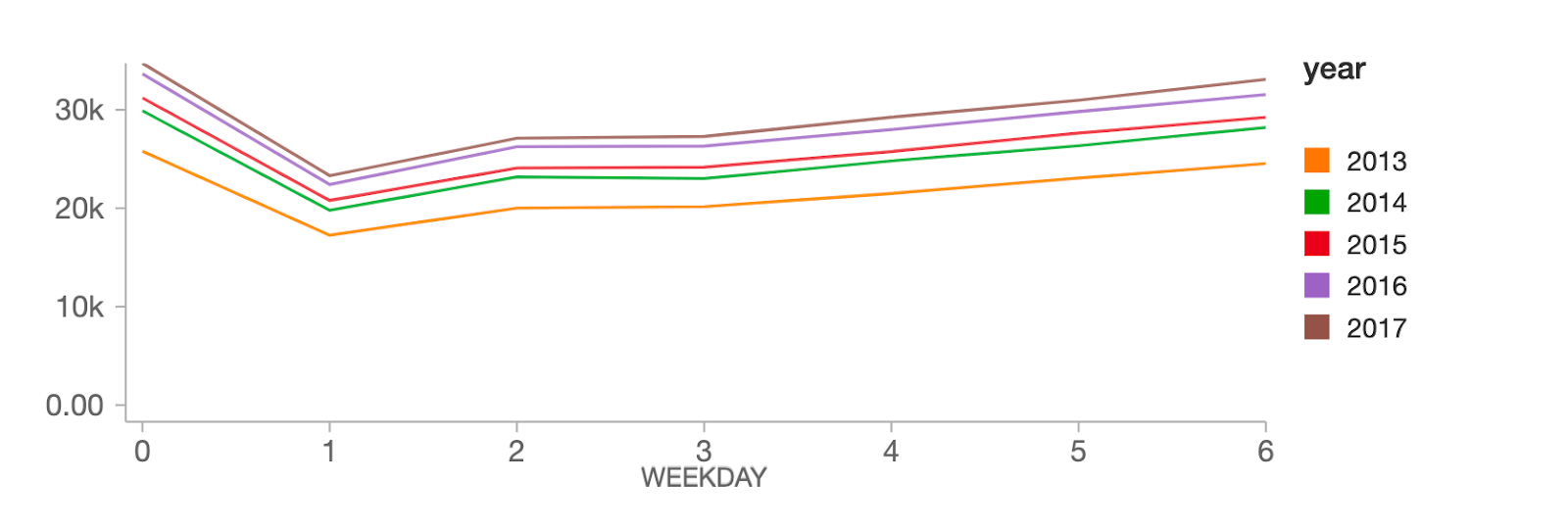
如上所示,我们的数据显示了销售额明显的同比上升趋势,以及年度和每周的季节性模式。Facebook Prophet的设计目的就是要解决这些数据中的重叠模式。
Facebook Prophet遵循scikit-learn API,所以对于任何有sklearn经验的人来说都应该很容易上手。我们需要传入一个两列的pandas DataFrame作为输入:第一列是日期,第二列是要预测的值(在我们的例子中是销售额)。一旦我们的数据有了合适的格式,建立一个模型就很容易了:
进口熊猫作为pd从fbprophet进口先知#实例化模型并设置参数模型=先知(interval_width =0.95,增长=“线性”,daily_seasonality =假,weekly_seasonality =真正的,yearly_seasonality =真正的,seasonality_mode =“乘法”)#拟合模型到历史数据model.fit (history_pd)现在我们已经将模型与数据进行了拟合,让我们用它来构建90天的预测:
使用Prophet内置的make_future_dataframe方法定义一个数据集,包括历史日期和90天后的最后一个可用日期Future_pd = model.make_future_dataframe(时间=90,频率=' d ',include_history =真正的)#预测数据集Forecast_pd = model.predict(future_pd)就是这样!现在,我们可以使用Facebook Prophet模型内置的。plot方法来可视化我们的实际数据和预测数据是如何排列的,以及对未来的预测。如您所见,前面显示的每周和季节性需求模式都反映在预测结果中。
Predict_fig =模型。情节(forecast_pd包含=“日期”ylabel =“销售”)显示(图)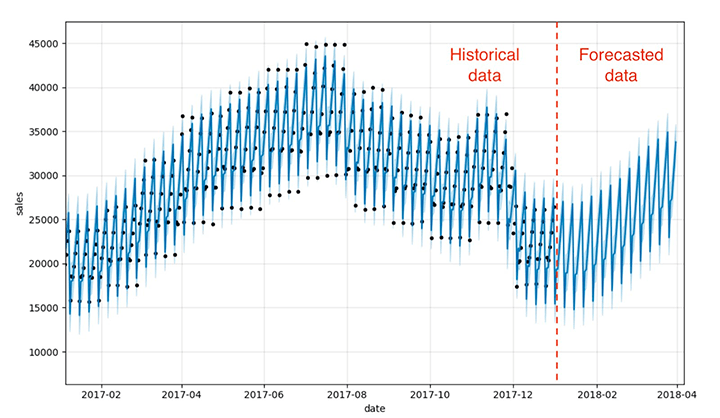
这个可视化有点忙。Bartosz Mikulski提供了一个优秀的崩溃这很值得一查。简而言之,黑点代表我们的实际情况,深蓝色线代表我们的预测,浅蓝色带代表我们的(95%)不确定性区间。
现在我们已经演示了如何构建单个模型,我们可以使用Spark的强大功能来加倍努力。我们的目标不是为整个数据集生成一个预测,而是为每个产品-商店组合生成数百个模型和预测,作为连续操作执行这将是非常耗时的。
例如,以这种方式构建模型可以让连锁杂货店根据不同地点的不同需求,为他们应该为桑达斯基商店订购的牛奶量与克利夫兰商店所需的牛奶量创建精确的预测。
数据科学家经常使用分布式数据处理引擎来处理训练大量模型的挑战火花.通过杠杆火花集群,集群中的单个工作节点可以与其他工作节点并行训练模型的子集,大大减少了训练整个时间序列模型集合所需的总体时间。
当然,在工作节点(计算机)集群上训练模型需要更多的云基础设施,这是有代价的。但是,随着按需云资源的容易获得,公司可以快速提供所需的资源,训练模型,并快速释放这些资源,从而允许他们实现大规模的可伸缩性,而无需对物理资产进行长期承诺。
在Spark中实现分布式数据处理的关键机制是DataFrame。通过将数据加载到Spark DataFrame中,数据将分布到集群中的各个worker中。这允许这些工作人员以并行的方式处理数据子集,减少执行工作所需的总时间。
当然,每个工作人员都需要访问完成其工作所需的数据子集。通过根据键值分组数据(在本例中是关于store和item的组合),我们将这些键值的所有时间序列数据集中到特定的工作节点上。
store_item_history.groupBy (“存储”,“项目”)……我们在这里分享groupBy代码,以强调它如何使我们能够高效地并行训练许多模型,尽管它不会真正发挥作用,直到我们在下一节中对数据设置并应用一个自定义pandas函数。
时间序列数据按商店和商品正确分组后,我们现在需要为每一组训练一个模型。为了实现这一点,我们可以使用熊猫函数,这允许我们对DataFrame中的每组数据应用自定义函数。
这个函数不仅会为每个组训练一个模型,还会生成一个表示该模型预测的结果集。但是,虽然该函数将独立于其他组对DataFrame中的每个组进行训练和预测,但从每个组返回的结果将方便地收集到单个结果DataFrame中。这将允许我们生成存储项目级别的预测,但将我们的结果作为单个输出数据集呈现给分析师和经理。
正如您在下面的缩写代码中所看到的,构建我们的函数是相对简单的。与之前的Spark版本不同,我们可以以一种相当简化的方式声明函数,指定我们期望接收和返回的pandas对象的类型。Python类型提示.
在函数定义中,我们实例化我们的模型,配置它并使它适应它所接收到的数据。模型进行预测,并将该数据作为函数的输出返回。
defforecast_store_item(history_pd: pd。DataFrame) -> pd。DataFrame:#实例化模型,配置参数模型=先知(interval_width =0.95,增长=“线性”,daily_seasonality =假,weekly_seasonality =真正的,yearly_seasonality =真正的,seasonality_mode =“乘法”)#适合模型model.fit (history_pd)#配置预测Future_pd = model.make_future_dataframe(时间=90,频率=' d ',include_history =真正的)#做预测Results_pd = model.predict(future_pd)#……#回报预测返回results_pd现在,为了将它们组合在一起,我们使用前面讨论过的groupBy命令来确保数据集被正确地划分为代表特定商店和项目组合的组。然后,我们简单地将yinpandas函数应用到我们的DataFrame,允许它拟合模型并对每组数据进行预测。
函数对每个组的应用程序返回的数据集被更新,以反映我们生成预测的日期。这将帮助我们跟踪在不同模型运行期间生成的数据,因为我们最终将功能投入生产。
从pyspark.sql.functions进口当前日期结果=(store_item_history.groupBy (“存储”,“项目”).applyInPandas (forecast_store_item模式=result_schema).withColumn (“training_date”,当前日期()))现在,我们已经为每个商店商品组合构建了一个预测。使用SQL查询,分析师可以查看每个产品的定制预测。在下面的图表中,我们绘制了10家商店对产品1的预计需求。正如你所看到的,需求预测因商店而异,但正如我们所预期的,所有商店的总体模式是一致的。
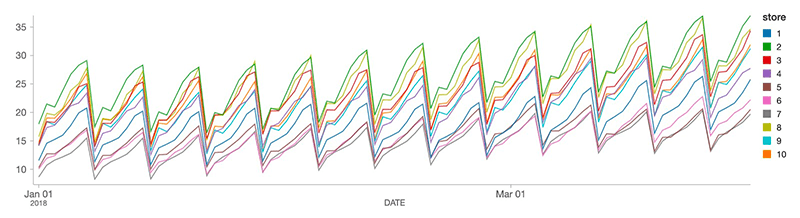
随着新的销售数据的到来,我们可以有效地生成新的预测,并将这些预测附加到我们现有的表结构中,允许分析师随着情况的发展更新业务预期。
要在您的Databricks环境中生成这些预测,请查看我们的需求预测解决方案加速器.
要访问此笔记本的先前版本(为Spark 2.0构建),请点击此链接.