



测量广告效果与销售预测和归因
你连接的影响,市场营销和广告支出对推动销售?随着广告景观继续发展,广告商发现其越来越具有挑战性,以有效地查明各种收入的营销活动的影响在他们的媒体组合。
品牌每年花费数十亿美元在零售推广他们的产品。这个营销花费计划提前3到6个月的时间和用于驱动促销策略来提高认识,生成试验,提高该品牌的产品和服务的消费。整个模型是与COVID中断。消费行为正在迅速改变,和品牌不再有奢侈的规划促销提前几个月花。品牌需要做决定在几天,甚至几个星期,甚至在接近实时的。因此,品牌等预算转向更灵活渠道数字广告和促销活动。
使得品牌这种改变并不容易。增加个性化的数字策略持有承诺交付消息最有可能引起个体消费者的共鸣。然而,传统的统计分析和媒体计划工具已经建立在长交货期使用聚合数据,这使得它难以优化消息传递部分和个人层面。市场营销或媒体组合建模(嗯)通常用于理解不同营销策略的影响相对于其他策略,并确定最优水平的花为未来的计划,但是嗯是一个高度手册,耗时和回顾性运动由于挑战集成多种数据集的不同级别的聚合。
你的印刷和电视广告公司可能会发送两周一次的excel电子表格提供印象在指定的市场区域(DMA)水平;数字广告公司可能提供CSV文件显示点击和印象在你的水平;你的销售数据可能会收到一个市场水平;和搜索和社会每个人都有自己的专有报告通过api切片观众由多种因素。加剧这一挑战是随着品牌转向数字媒体和敏捷方法的广告,他们增加不同的数据集的数量,需要快速合并和分析。因此,大多数营销人员进行嗯演习最多一次季度(通常一年一次)由于合理化和覆盖不同的数据源是一个过程,可能需要几周或数月的时间。
嗯是用于更广泛的营销投资决策水平,品牌需要快速做出决定的能力在一个好的层面。他们需要集成新的营销数据,进行分析,并加速决策从几个月或几周天或小时。品牌可以实时响应程序工作将导致更高的投资回报他们的努力。
介绍销售预测与广告归因仪表板加速器的解决方案
基于最佳实践从我们的工作领先品牌,我们开发了解决方案加速器常见用例分析和机器学习的发展保存数周或数月的时间你的数据工程师和科学家。
无论你是广告代理商或内部营销分析团队,这个解决方案加速器使您可以轻松地插入销售,广告接触,和地理数据从不同的历史和当前的来源,看看这些推动销售在当地的水平。这个解决方案,您也可以属性数字营销努力的总趋势水平没有饼干/设备ID跟踪和映射,已成为一个更大的担忧的消息苹果不以为然的IDFA。
通常,归因可以是一个相当昂贵的过程,尤其是对不断更新数据集运行归因没有正确的技术。幸运的是,砖与三角洲湖——提供了一个统一的数据分析平台开源事务层来管理您的云湖——大规模数据多重云基础设施工程和数据bob体育客户端下载科学。bob下载地址这个博客将演示数据砖如何促进了多级三角洲湖转换、机器学习和活动的可视化数据提供可行的见解。
三件事让这个解决方案加速器独特的相对于其他广告归因工具:
- 能够轻松地将新数据源集成到模式:三角洲体系结构的优势之一是多么容易混合新数据模式。通过自动化数据浓缩在三角洲湖,你可以很容易的,例如,集成一个新的数据源,使用一个不同的时间/日期格式相比,你其他的数据。这使得很容易覆盖营销策略到您的模型中,轻松地集成新的数据源。
- 实时仪表盘:虽然大多数嗯结果在一个时间点的分析中,加速器的自动数据管道提要轻松地共享指示板允许业务用户立即地图或预测ad-impressions-to-sales只要这些文件生成水平甚至segment-level数据可视化。
- 与机器学习的集成:机器学习模型在这个解决方案中,营销团队可以构建更细粒度的数据自上而下或地面行动的看法,每日广告客户群体的共鸣,甚至个人层面。
通过提供结构和模式执行在所有你的营销数据,三角洲湖砖可以让这个中央的消费数据来源BI和AI团队,有效地让这个营销数据湖。
该解决方案如何扩展和改善传统吗嗯、预测和归因
这个解决方案两个最大的优势是更快的洞察力和增加时间粒度相对于传统嗯,预报,和归因结合可靠数据摄入&准备,敏捷数据分析和机器学习努力成为一个统一的见解平台。bob体育客户端下载
当试图确定活动花优化通过嗯,营销人员传统上依靠手工流程来收集长期媒体购买数据,以及观察宏观因素可能影响活动,促销等竞争对手,品牌资产,季节性或经济因素。典型的嗯周期可能需要数周或数月,通常不提供可行的见解直到很久以后活动已经生活,有时,直到活动结束!在传统的营销组合模型建立和验证,它可能是来不及行动有价值的见解和关键因素,以确保最大限度地有效的运动。
此外,嗯重点推荐媒体组合策略从宏观的角度只提供自上而下的观点没有考虑最优信息以更细的粒度。作为广告的努力严重转向数字媒体,传统嗯方法未能提供深入了解这些用户级机会可以有效地优化。
通过统一的摄取、加工、分析和数据科学的广告数据到一个单独的平台、营销数据团队可以产生自顶向下和自底向上粒度级别的见解。bob体育客户端下载这将使营销人员执行直接量甚至用户级深潜水,和帮助广告商确定精确的营销组合最影响他们的努力正在优化正确的信息在正确的时间通过正确的渠道。简而言之,营销人员将极大的受益更有效和统一的测量方法。
解决方案概述
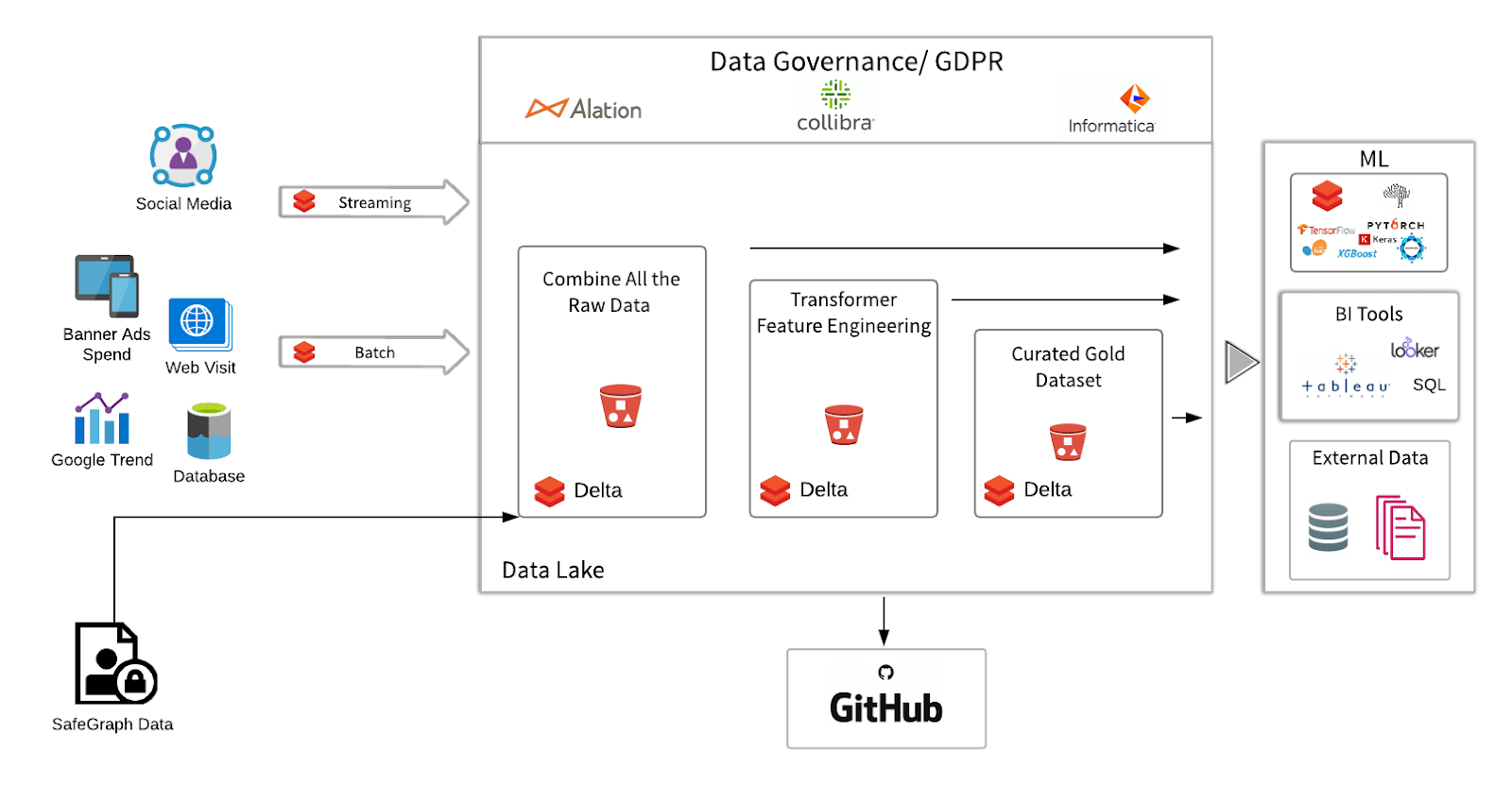
在高级别上连接一个时间序列的区域销售区域离线和在线广告的印象超过三十天。用毫升比较不同类型的测量(电视印象或毛评点与数码旗帜点击与社会等)在所有地区,然后我们关联的类型订婚增量区域销售为了建立归因和预测模型。挑战等合并广告kpi的印象,来自不同数据源的点击,页面浏览量与不同的模式(例如,一个源可能使用天部分测量印象而另一个使用确切的日期和时间;位置可以通过邮政编码在一个源和在另一个市区)。
作为一个例子,我们使用的是SafeGraph丰富的数据集客流量数据从同一连锁餐馆。当我们使用嘲笑离线存储访问对于这个示例,您可以很轻松地插入离线和在线销售地区和日期提供的数据包括在你的销售数据。我们将读到不同位置的店内访问数据,探索PySpark和火花SQL中的数据,并使数据清洁,可靠和分析准备毫升的任务。对于这个示例,营销团队想要找出哪些网络媒体是最有效的渠道推动店内参观。
主要步骤是:
- 摄入:模拟月客流量时间序列SafeGraph格式——这里我们嘲笑数据以适应模式(青铜)
- 工程特点:转换为月度时间序列数据我们匹配数值的访问数量/日期(行=日期)(银)
- 数据浓缩:覆盖区域活动数据区域销售。进行探索性分析等功能分布的检查和变量变换(黄金)
- 高级分析/机器学习:构建预测与归因模型
的数据:
我们使用SafeGraph提取店内访问模式。SafeGraph的地方模式是匿名的数据集和聚合访客定居和访客人口数据可供~ 3.6毫米的兴趣点(POI)在美国。在这个练习中,我们看历史数据(2019年1月- 2020年2月)一组有限服务的餐厅店内访问纽约。
1。数据摄取到三角洲格式(青铜)
从笔记本”运动Effectiveness_Forecasting脚Traffic_ETL”。
第一步是加载数据从blob存储。近年来越来越多的广告商选择摄取他们的竞选blob存储数据。例如,您可以通过FBX Facebook广告见解API以编程方式检索数据。你可以查询端点的印象,点击率数据,中国共产党。在大多数情况下,数据将返回在CSV或XLS格式。在我们的示例中,配置相当无缝:我们pre-mount dbfs S3 bucket,这样一旦设置源文件的目录,我们可以直接加载原始CSV文件从blob数据砖。
raw_sim_ft = spark.read。格式(“csv”).option (“头”,“真正的”).option (“9”,”、“).load (“/ tmp / altdata_poi / foot_traffic.csv”)raw_sim_ft.createOrReplaceTempView (“safegraph_sim_foot_traffic”)然后创建一个临时视图允许我直接与这些文件使用火花SQL交互。因为店内访日是一个大数组在这一点上,我们将有一些特性工程以后的工作要做。在这一点上我准备使用三角洲写出数据格式创建三角洲湖青铜表来捕获所有原始数据指向一个blob的位置。铜表作为数据的第一站湖泊,原始数据从各种来源哪里来不断通过批处理或流,这是一个地方的数据可以被捕获并存储在原来的原始格式。数据在这个步骤可以是肮脏的,因为它来自于不同的来源。
raw_sim_ft.write。格式(“δ”).mode (“覆盖”).save (“/ home /蕾拉/数据/表/ footTrafficBronze ')2。特性工程做销售时间序列准备阴谋(银)
将原始数据后,我们现在有一些数据清洗和特性的工程任务。例如,添加MSA地区和解析月/年。因为我们发现visit_by_date是一个数组,我们需要爆炸的数据到单独的行。这个功能块将平数组。跑后,它将返回visits_by_day df, num_visit映射到每一行:
def解析器(元素):返回json.loads(元素)defparser_maptype(元素):返回json。负载(元素,MapType (StringType (), IntegerType ()))jsonudf = udf(解析器,MapType (StringType (), IntegerType ()))convert_array_to_dict_udf = udf (λ加勒比海盗:{idx: x为idx x在列举(json.loads (arr)}, MapType (StringType (), IntegerType ()))defexplode_json_column_with_labels(df_parsed column_to_explode key_col =“关键”value_col =“价值”):df_exploded = df_parsed.select (“safegraph_place_id”,“location_name”,“msa”,“date_range_start”,“年”,“月”,“date_range_end”爆炸(column_to_explode)) .selectExpr (“safegraph_place_id”,“date_range_end”,“location_name”,“msa”,“date_range_start”,“年”,“月”,“关键是{0}”。格式(key_col),“价值为{0}”。格式(value_col))返回(df_exploded)工程特性后,数据准备好供下游业务团队使用。我们可以持续数据三角洲湖银表,这样团队中的每个人都可以直接访问数据。在这个阶段,数据是干净的和多个下游黄金表将取决于它。不同的业务团队可能有自己的业务逻辑进行进一步的数据转换。例如,你可以想象我们有一个银表“特性分析”,水合物几个下游表有不同目的像填充一个见解仪表盘、生成报告使用一组指标,或喂养ML算法。
3所示。数据浓缩与广告覆盖(金-分析做好准备)
在这一点上,我们已经准备好丰富的数据集在线竞选媒体数据。在传统的嗯数据收集阶段、数据浓缩服务通常发生在数据湖,到达分析平台。bob体育客户端下载用方法的目标是一样的:把一个商业广告的基本数据(即印象、点击、转换,观众属性)成一个更完整的画卷的人口,地理、心理、和/或采购行为。
数据浓缩不是一个一次性的过程。观众信息,如位置、偏好和行为随时间变化。通过利用三角洲湖、广告数据和观众概要文件可以持续更新,以确保数据保持清洁,相关和有用的。营销人员和数据分析师可以构建更完整的消费资料,与客户发展。在我们的例子中,我们有旗帜印象,社会媒体FB喜欢和web登录页面访问。使用SQL火花很容易加入不同的数据流,原dataframe。为了进一步丰富数据,我们称之为Google趋势API将在谷歌趋势有机搜索关键字搜索索引来表示元素——这个数据是来自谷歌趋势。
def解析器(元素):x返回json.loads(元素)defparser_maptype(元素):返回json。负载(元素,MapType (StringType (), IntegerType ()))
jsonudf = udf(解析器,MapType (StringType (), IntegerType ()))convert_array_to_dict_udf = udf (λ加勒比海盗:{idx: x为idx x在列举(json.loads (arr)}, MapType (StringType (), IntegerType ()))defexplode_json_column_with_labels(df_parsed column_to_explode key_col =“关键”value_col =“价值”):df_exploded = df_parsed.select (“safegraph_place_id”,“location_name”,“msa”,“date_range_start”,“年”,“月”,“date_range_end”爆炸(column_to_explode)) .selectExpr (“safegraph_place_id”,“date_range_end”,“location_name”,“msa”,“date_range_start”,“年”,“月”,“关键是{0}”。格式(key_col),“价值为{0}”。格式(value_col))返回(df_exploded)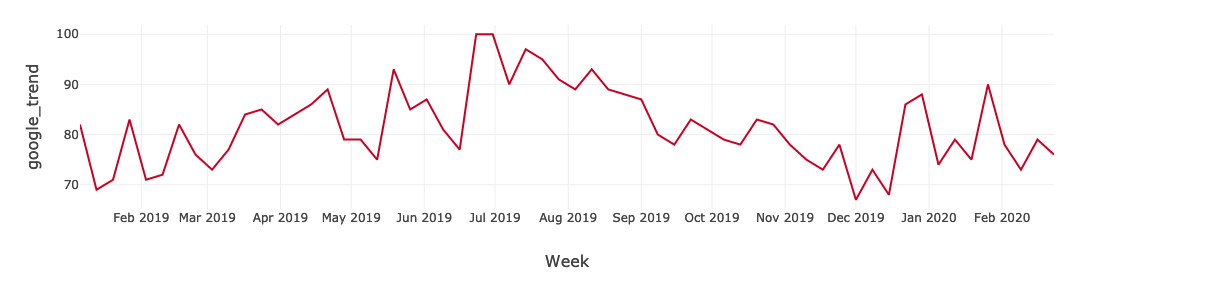
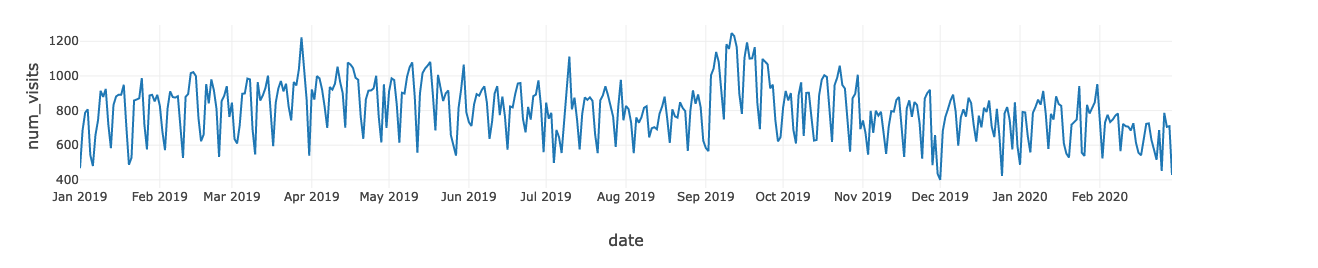
最后,一个数据集结合店内num_visit和在线媒体数据。我们可以快速获得的见解通过绘制num_visit时间序列。例如,您可以使用图形可视化趋势项或数值。在我们的案例中,因为日期和时间信息是一个连续聚合统计数据,点绘制沿x轴和由实线连接。缺失的数据显示虚线。
时间序列图可以回答关于你的数据的问题,如:随时间变化的趋势如何?或者我有缺失值吗?下面的图显示了从1月店内参观,2019年2月,2020年。店内的最高时期访问发生在2019年9月中旬。如果营销活动发生在这两个月里,这将意味着活动是有效的,但只有在有限的时间内。
我们写出这个干净、三角洲湖丰富的数据集,创建一个黄金表上。
4所示。先进的分析和机器学习来构建预测和归因模型
传统嗯使用方差分析和多重回归的组合。在这个解决方案中,我们将演示如何使用一个XGBoost ML算法固有的优点是模型讲解员世鹏科技电子在第二毫升笔记本。即使这个解决方案没有取代传统嗯过程,传统嗯统计学家可以编写单个节点的代码,并使用pandas_udf运行它。
下一步,使用笔记本”运动Effectiveness_Forecasting脚Traffic_机器学习”。
到目前为止,我们使用砖摄取和把所有的原始数据;然后清洗、转换和添加额外的可靠性数据通过编写三角洲湖为更快的查询性能
在这一点上,我们应该对数据集感觉不错。现在是时候来创建归因模式。我们要用黄金策划表数据仔细观察行人在纽约了解快餐连锁店的各种广告宣传努力推动店内访问。
主要步骤是:
- 创建一种机器学习方法,预测数量的店内访问给定一组网络媒体数据
- 利用世鹏科技电子模型翻译再混合的模型预测和量化多少客流量一定媒体频道开车
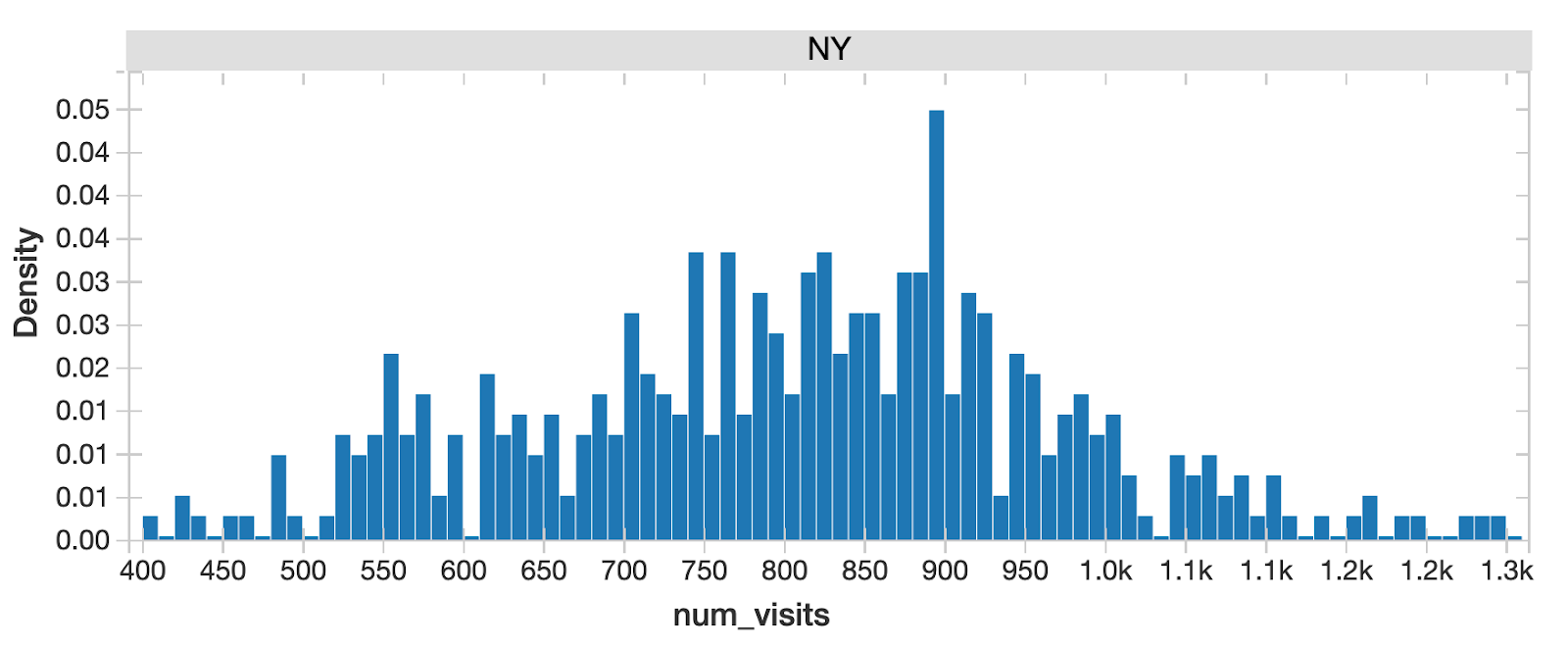
作为数据科学的标准步骤,我们想了解目标变量的概率分布store-visit和潜在的特性,因为它告诉我们所有可能的值(或间隔)的数据意味着人口的基本特征。从这个图表我们可以快速识别,纽约州立店内参观,有两个峰值,表明多通道分布。这意味着人口潜在的差异在不同的领域,我们应该进一步深入。
%sql选择*从(选择地区、城市、投(一年作为整数)一年,投(月作为整数)月,投(一天作为整数)一天,总和(num_visits) num_visits从layla_v2.Subway_foot_traffic在哪里地区=“纽约”和num_visits> =50集团通过地区、城市、投(一年作为整数),投(月作为整数),投(一天作为整数)订单通过一年,月,一天,num_visits)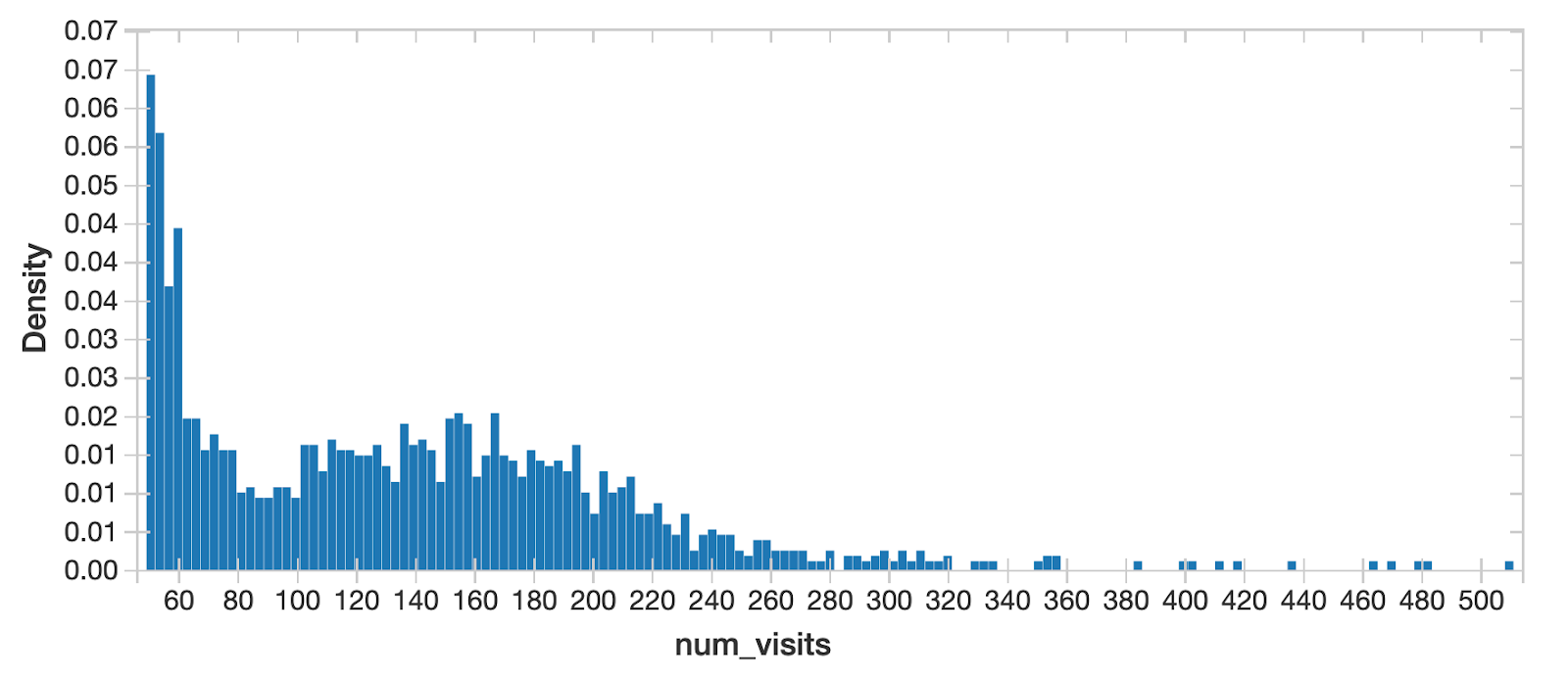
当分离纽约市交通从所有其他城市,看起来接近正常——纽约分布一定是一个独特的地区!
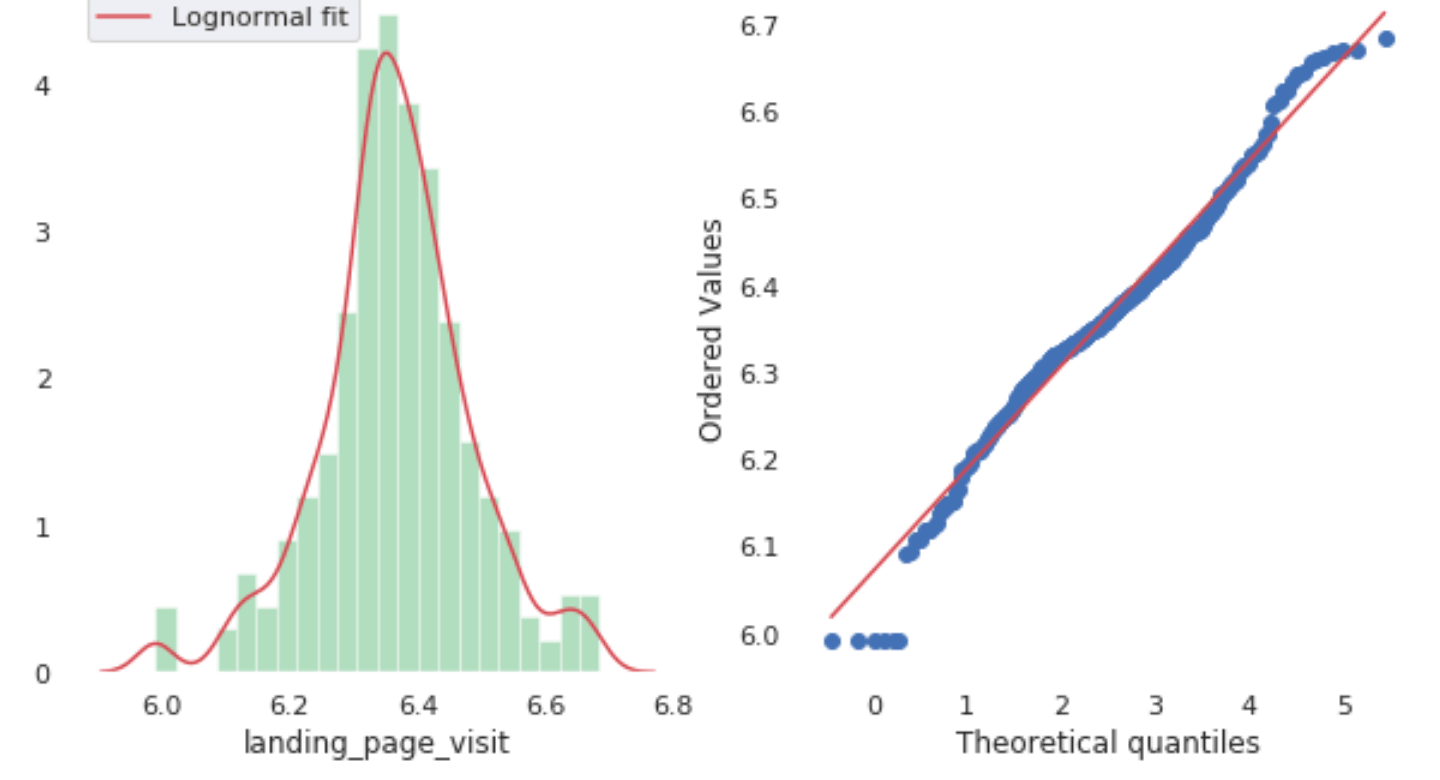
然后我们也检查的所有特性的分布使用qq情节和正常测试。从图表我们可以告诉看起来很正态分布的特性。良好的钟形曲线。
砖做分析的一个重要优点是,我可以自由开关从火花dataframe到熊猫,和使用流行的可视化库图绘制图表在笔记本上探索我的数据。下面的图表是阴谋。我们可以放大,缩小,钻在密切关注任何数据点。
情节与放大图面板
正如我们所看到的,它很容易创建所需的所有统计图,我们不离开相同的笔记本的环境。
现在,我们相信,适用于模型训练数据。让我们训练预测模型。算法的选择,我们将使用XGBoost。数据集并不大,所以单节点训练是一种有效的方法。数据符合记忆时,我们建议您火车毫升模型在单个机器上如果训练数据大小适合内存(说HyperOpt——分布式优化模型的超参数,以便我们可以找到最好的hyperparameters:效率提高了
从hyperopt进口fmin, tpe,兰德、惠普、试验,STATUS_OK进口xgboost从xgboost进口XGBRegressor从sklearn.model_selection进口cross_val_score进口mlflow进口mlflow.xgboost从sklearn.model_selection进口train_test_splitpdf = city_pdf.copy ()X_train、X_test y_train y_test = train_test_split (pdf.drop ([“地区”,“年”,“月”,“天”,“日期”,“num_visits”),轴=1pdf (),“num_visits”),test_size =0.33random_state =55)def火车(参数个数):”“”一个例子训练方法,计算输入的平方。该方法将被传递给“hyperopt.fmin ()”。:param参数:hyperparameters。它的结构是一致的搜索空间是如何定义的。见下文。:返回:dict字段“损失”(标量损失)和“状态”(成功/失败运行状态)”“”curr_model = XGBRegressor (learning_rate = params [0),γ=int(params [1]),max_depth =int(params [2]),n_estimators =int(params [3]),min_child_weight = params [4)、客观=“注册:squarederror”)分数= -cross_val_score (curr_model X_train y_train,得分=“neg_mean_squared_error”).mean ()分数= np.array(分数)返回{“损失”:分数,“状态”:STATUS_OK,“模型”:curr_model}
#定义搜索参数和离散或连续search_space = [hp.uniform (“learning_rate”,0,1),hp.uniform (“伽马”,0,5),hp.randint (“max_depth”,10),hp.randint (“n_estimators”,20.),hp.randint (“min_child_weight”,10)]#定义搜索算法(TPE或随机搜索)算法= tpe.suggest从hyperopt进口SparkTrialssearch_parallelism =4spark_trials = SparkTrials(并行= search_parallelism)与mlflow.start_run ():argmin = fmin (fn =火车,空间= search_space,算法=算法,max_evals =8,试验= spark_trials)
deffit_best_model(X, y):客户= mlflow.tracking.MlflowClient ()experiment_id = client.get_experiment_by_name .experiment_id (experiment_name)
运行= mlflow.search_runs (experiment_id)best_loss =[运行“metrics.loss”]。最小值()best_run =运行(运行(“metrics.loss”)= = best_loss)
best_params = {}best_params [“伽马”]=浮动(best_run [“params.gamma”])best_params [“learning_rate”]=浮动(best_run [“params.learning_rate”])best_params [“max_depth”]=浮动(best_run [“params.max_depth”])best_params [“min_child_weight”]=浮动(best_run [“params.min_child_weight”])best_params [“n_estimators”]=浮动(best_run [“params.n_estimators”])xgb_regressor = XGBRegressor (learning_rate = best_params [“learning_rate”),max_depth =int(best_params [“max_depth”]),n_estimators =int(best_params [“n_estimators”]),γ=int(best_params [“伽马”]),min_child_weight = best_params [“min_child_weight”)、客观=“注册:squarederror”)xgb_model = xgb_regressor。符合(X, y,冗长的=假)返回(xgb_model)#使用最适合的模型参数和测井模型xgb_model = fit_best_model (X_train y_train)mlflow.xgboost.log_model (xgb_model“xgboost”)#记录模型
从sklearn.metrics进口r2_score从sklearn.metrics进口mean_squared_errortrain_pred = xgb_model.predict (X_train)test_pred = xgb_model.predict (X_test)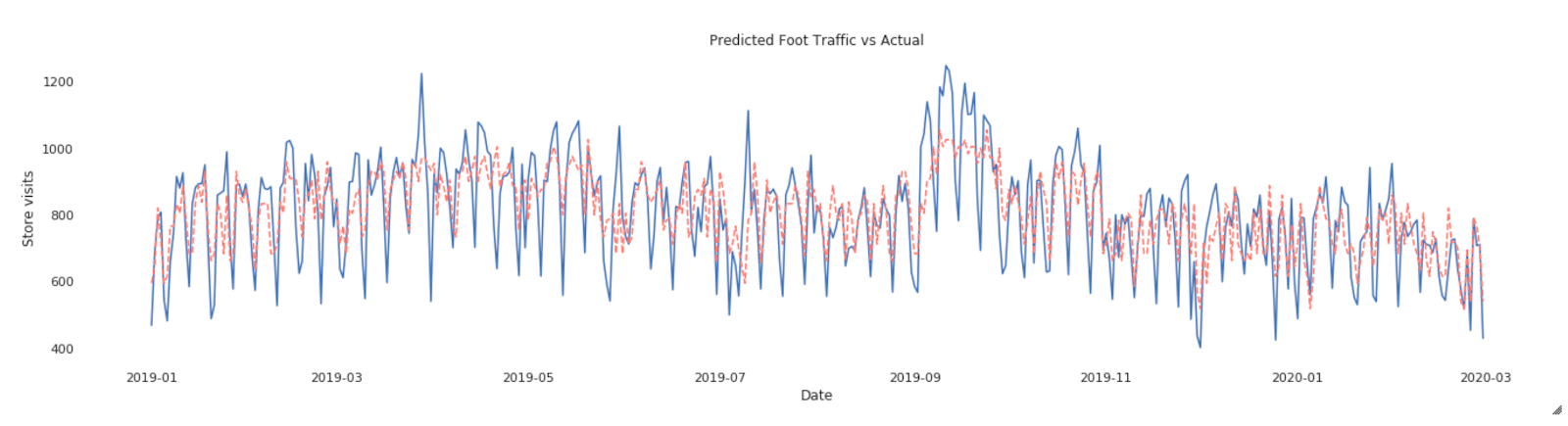
注意,通过指定Spark_trials, HyperOpt自动分配一个调优工作在一个Apache火花集群。HyperOpt发现最好的一组参数后,我们只需要适应模型一旦得到最好的模型适合比跑步更有效迭代模型的适合和交叉验证来找到最好的模型。现在我们可以使用拟合模型预测纽约店内交通:
deffit_best_model(X, y):客户= mlflow.tracking.MlflowClient ()experiment_id = client.get_experiment_by_name .experiment_id (experiment_name)
运行= mlflow.search_runs (experiment_id)best_loss =[运行“metrics.loss”]。最小值()best_run =运行(运行(“metrics.loss”)= = best_loss)
best_params = {}best_params [“伽马”]=浮动(best_run [“params.gamma”])best_params [“learning_rate”]=浮动(best_run [“params.learning_rate”])best_params [“max_depth”]=浮动(best_run [“params.max_depth”])best_params [“min_child_weight”]=浮动(best_run [“params.min_child_weight”])best_params [“n_estimators”]=浮动(best_run [“params.n_estimators”])xgb_regressor = XGBRegressor (learning_rate = best_params [“learning_rate”),max_depth =int(best_params [“max_depth”]),n_estimators =int(best_params [“n_estimators”]),γ=int(best_params [“伽马”]),min_child_weight = best_params [“min_child_weight”)、客观=“注册:squarederror”)xgb_model = xgb_regressor。符合(X, y,冗长的=假)返回(xgb_model)#使用最适合的模型参数和测井模型xgb_model = fit_best_model (X_train y_train)mlflow.xgboost.log_model (xgb_model“xgboost”)#记录模型从sklearn.metrics进口r2_score从sklearn.metrics进口mean_squared_errortrain_pred = xgb_model.predict (X_train)test_pred = xgb_model.predict (X_test)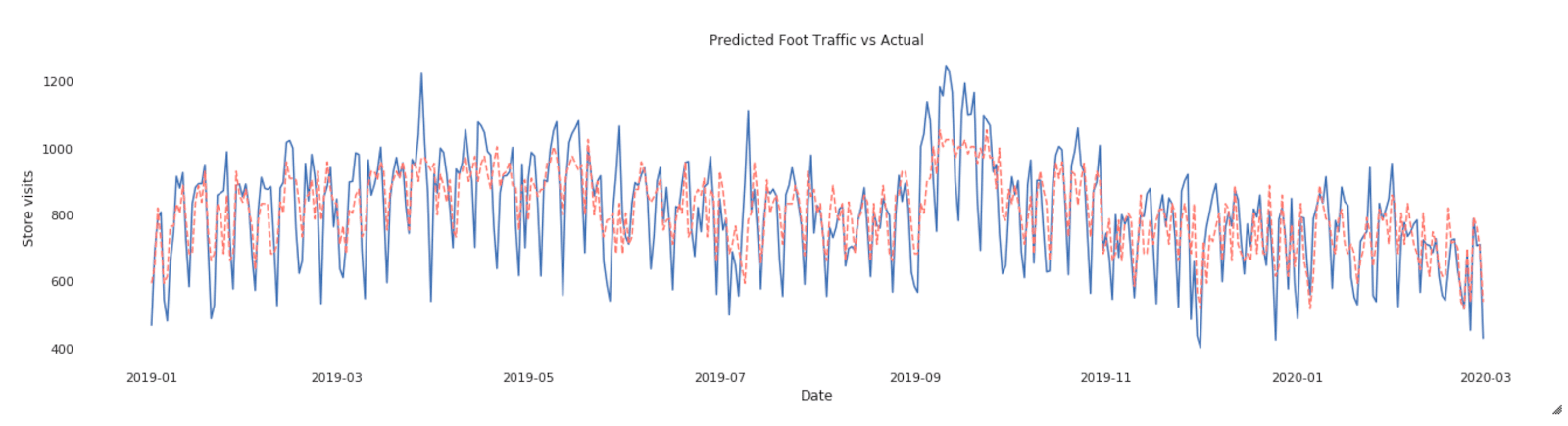
红线是预测而蓝色是实际访问——尽管它看起来像模型捕获主要趋势错过几峰值。以后肯定需要一些调整。不过,很体面的如此之快的努力!
一旦我们得到预测模型,一个自然的问题是如何模型进行预测呢?怎么每个特性有助于这个黑盒算法?在我们的案例中,问题变成了“多少钱每个媒体输入导致店内人流量。”
通过直接使用世鹏科技电子图书馆是一个开源软件模型翻译,我们可以很快得到见解,如“什么是最重要的媒体渠道驾驶我的线下活动吗?”
有一些好处,我们可以使用世鹏科技电子。首先,它可以解释在个人的层面上输入:每个观测将有其自己的一套世鹏科技电子值相比传统功能重要性算法告诉我们哪些特性是最重要的在整个人口。然而,通过只看趋势在全球层面,这些个体差异可以迷路了,只剩下最常见的分母。个体层面的世鹏科技电子值,我们可以确定哪些因素最有效的为每一个观察,让我们使生成的模型更加健壮和见解更可行的。所以在我们的例子中,它将计算每个媒体世鹏科技电子值输入每天店内参观。
沙普利值的图表,我们可以快速识别社交媒体和着陆页访问最高贡献模型:
世鹏科技电子。总和mary_plot(shap_values, X, plot_type=“酒吧”)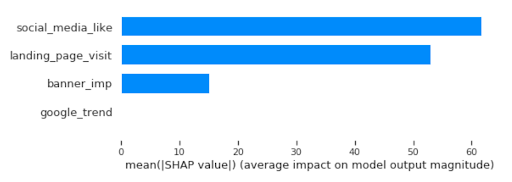
显示器(spark.createDataFrame (排序(列表(邮政编码(mean_abs_shap X.columns)),反向=真正的):8]、[“意思是| |穿刺法”,“特性”)))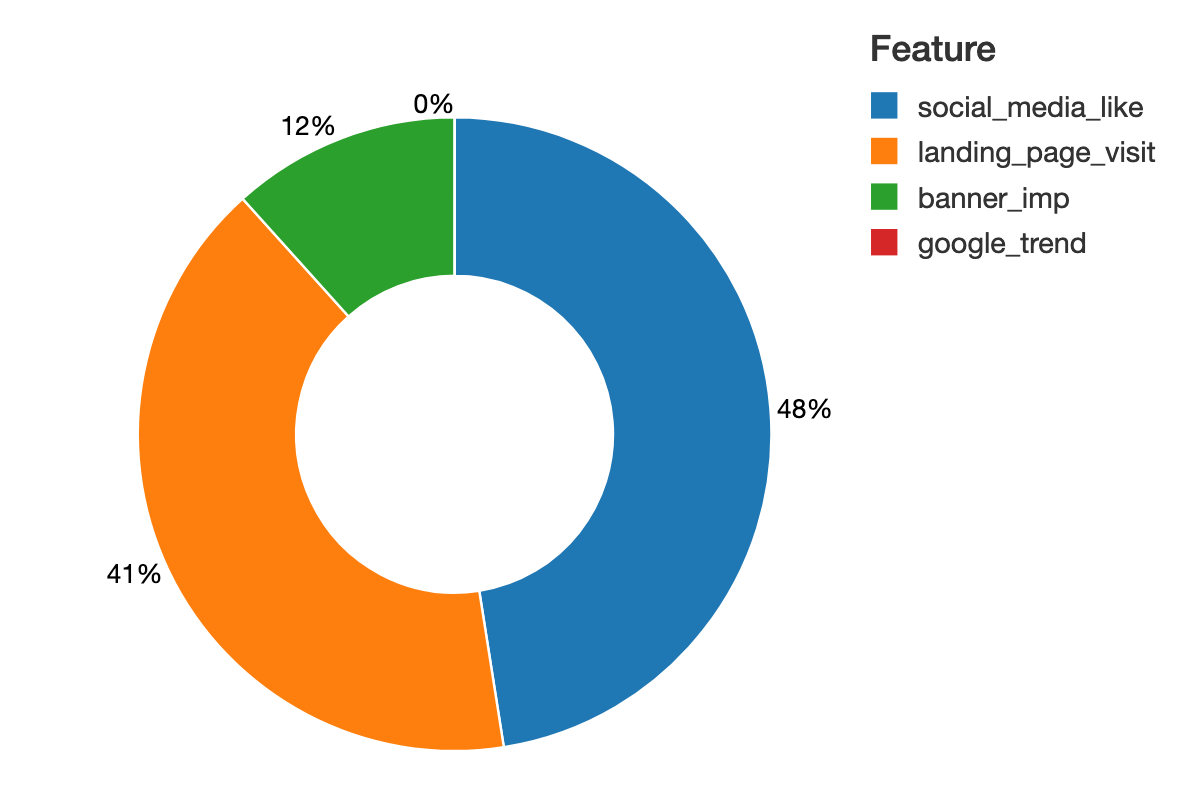
世鹏科技电子可以提供媒体组合的细粒度的洞察力在个体层面的贡献。我们可以直接与特性值的单位输出。世鹏科技电子是能够量化的影响特性模型的单元目标,店内参观。在这个图中,我们试图预测薪水,我们可以阅读的单元特性的影响,从而大大提高了解释结果相比相对分数从功能的重要性。
plot_html = shap.force_plot(讲解员。expected_value shap_values [n: n +1),feature_names = X。列,plot_cmap =“GnPR”)displayHTML (bundle_js + plot_html.data)
最后我们可以创建完整的日常定居时间序列分解图,有一个清晰的理解如何店内每个网络媒体输入访问属性。传统上,它要求数据科学家构建decomp矩阵,涉及一个混乱的转换和反复计算。这里与世鹏科技电子得到盒子的价值!
进口plotly.graph_objects作为去
无花果= go.Figure (data = (go.Bar (name =“base_value”x = shap_values_pdf [“日期”),y = shap_values_pdf [“base_value”),marker_color =“lightblue”),go.Bar (name =“banner_imp”x = shap_values_pdf [“日期”),y = shap_values_pdf [“banner_imp”]),go.Bar (name =“social_media_like”x = shap_values_pdf [“日期”),y = shap_values_pdf [“social_media_like”]),go.Bar (name =“landing_page_visit”x = shap_values_pdf [“日期”),y = shap_values_pdf [“landing_page_visit”]),go.Bar (name =“google_trend”x = shap_values_pdf [“日期”),y = shap_values_pdf [“google_trend”])])#改变模式fig.update_layout (barmode =“栈”)fig.show ()情节与放大图面板
我们正在背后的代码分析可供下载和审查。如果你有任何问题关于这个解决方案可以部署在您的环境中,请不要犹豫接触给我们。
免费试着砖
相关的帖子