



使用Azure Databricks和Azure Data Factory将90+数据源连接到您的数据湖
数据湖使组织能够通过安全、及时地访问各种各样的数据源,始终如一地交付价值和洞察力。…
数据的湖泊通过安全及时地访问各种各样的数据源,使组织能够始终如一地交付价值和洞察力。这一旅程的第一步是使用健壮的数据管道编排和自动化摄取。随着数据量、种类和速度的迅速增加,更需要可靠和安全的管道来提取、转换和加载(ETL)数据。
Databricks客户每月处理超过2eb(20亿gb)的数据Azure砖是目前微软Azure上增长最快的数据和人工智能服务。Azure Databricks与其他Azure服务之间的紧密集成使客户能够简化和扩展其数据摄取管道。例如,与Azure Active Directory (Azure AD)的集成可以实现一致的基于云的身份和访问管理。此外,与Azure数据湖存储(ADLS)的集成为用户提供了高度可伸缩和安全的存储大数据分析, Azure数据工厂(ADF)支持混合数据集成,以大规模简化ETL。
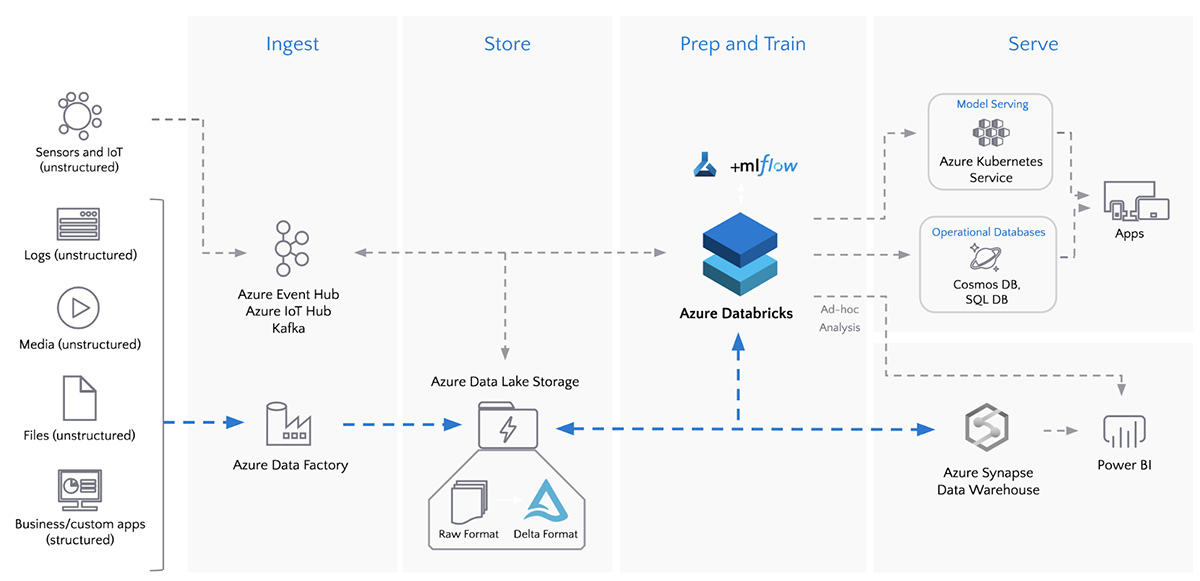
图:批处理ETL与Azure数据工厂和Azure数据
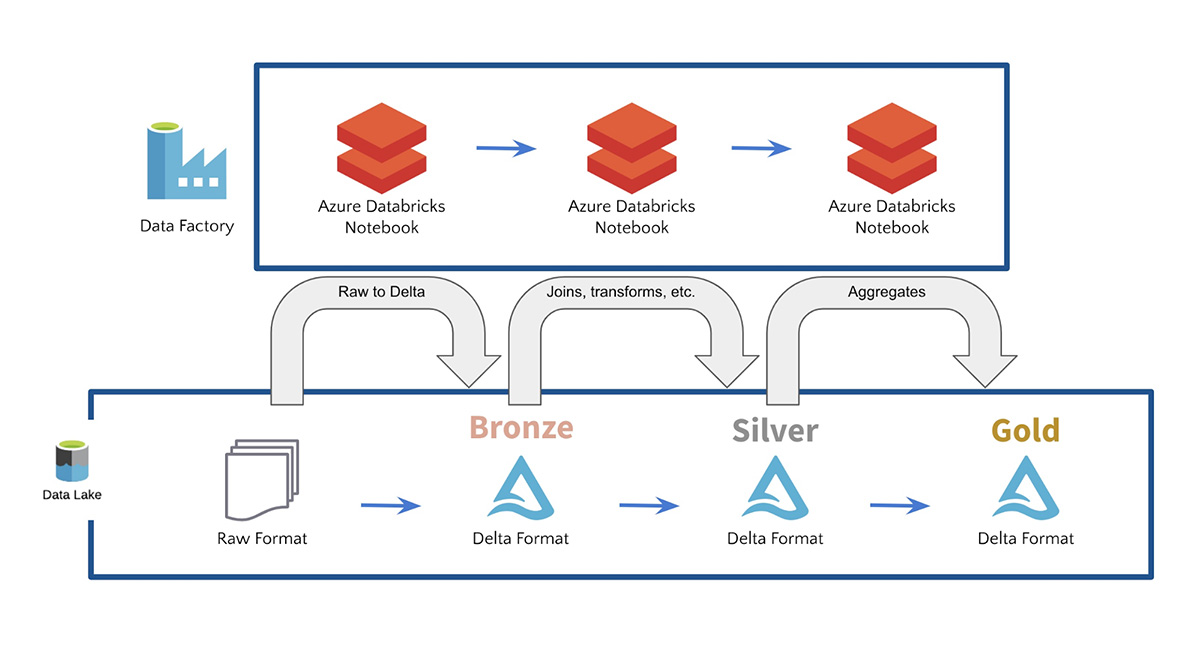
ADF包括90+内置数据源连接器并无缝运行Azure Databricks笔记本,将所有数据源连接并吸收到单个数据湖中。ADF还提供了内置的工作流控制、数据转换、管道调度、数据集成以及更多功能,以帮助您创建可靠的数据管道。ADF使客户能够以原始格式获取数据,然后通过Azure Databricks和Delta Lake将其数据提炼并转换为青铜表、银表和金表。例如,客户经常使用ADF与Azure Databricks Delta Lake一起启用数据湖上的SQL查询为了建造用于机器学习的数据管道.
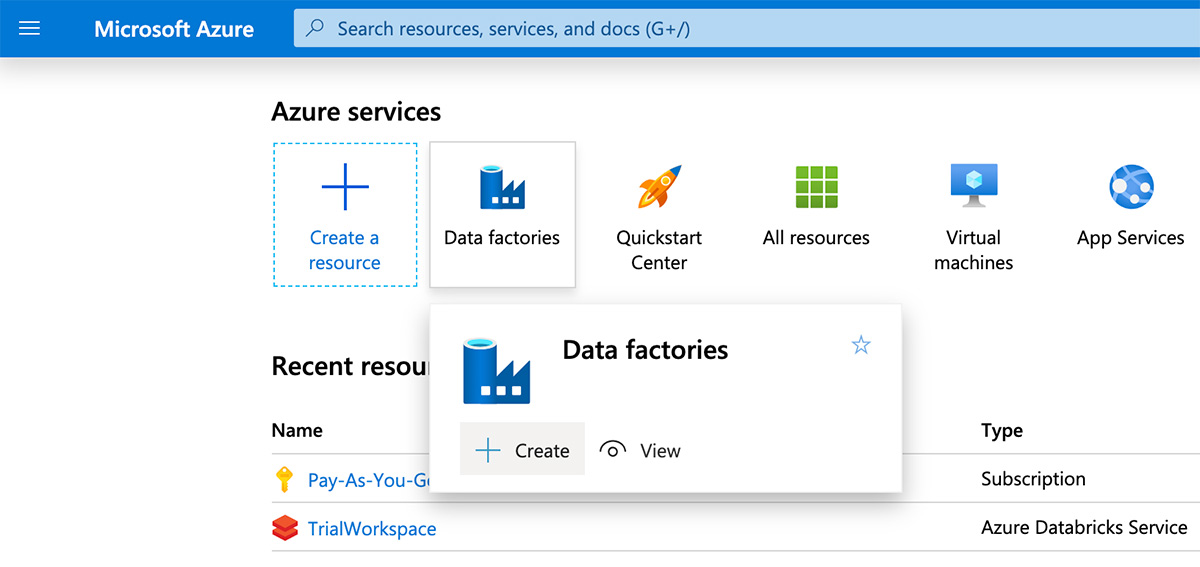
要使用Azure数据工厂运行Azure Databricks笔记本,请导航到Azure门户并搜索“数据工厂”,然后单击“创建”定义一个新的数据工厂。
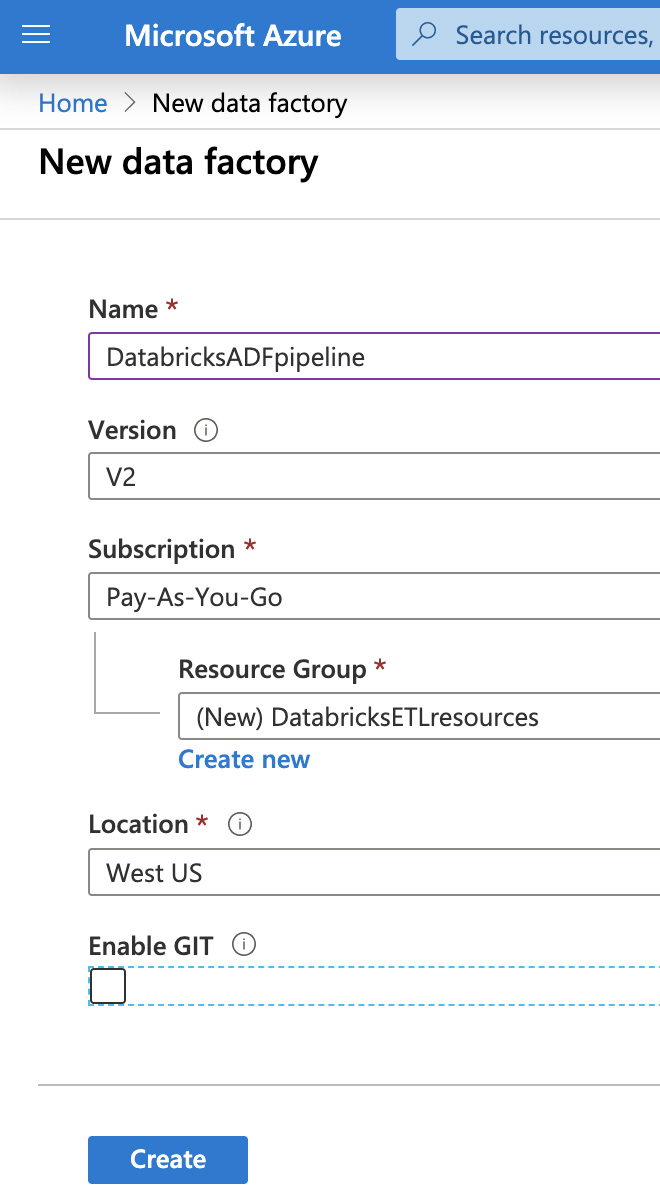
接下来,为数据工厂提供唯一的名称,选择订阅,然后选择资源组和区域。单击“创建”。
创建之后,单击“Go to resource”按钮查看新的数据工厂。
现在通过单击“Author & Monitor”tile打开Data Factory用户界面。
在Azure数据工厂“Let 's get started”页面中,单击左侧面板中的“Author”按钮。
接下来,点击屏幕底部的“连接”,然后点击“新建”。
在“新建链接服务”窗格中,单击“计算”选项卡,选择“Azure Databricks”,然后单击“继续”。
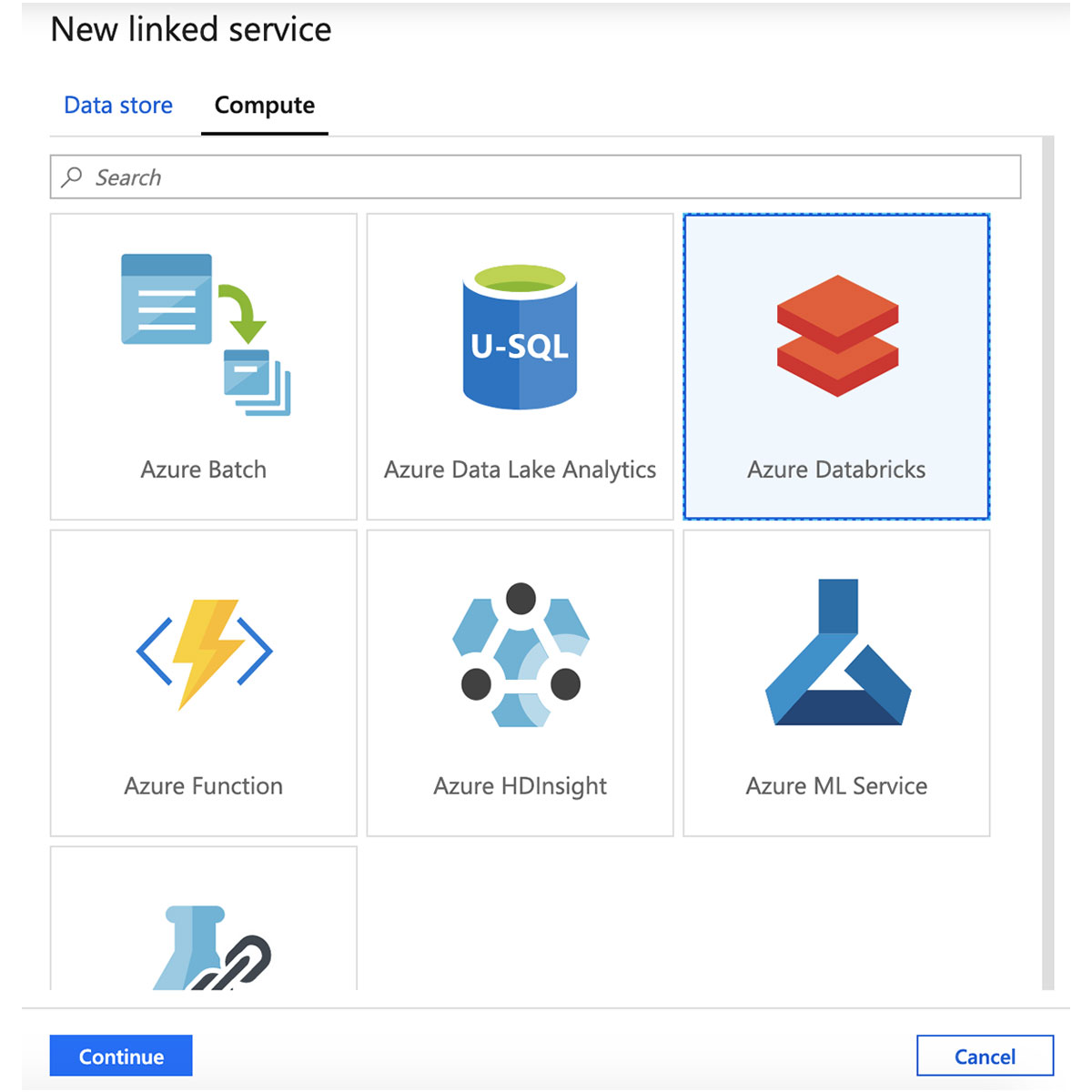
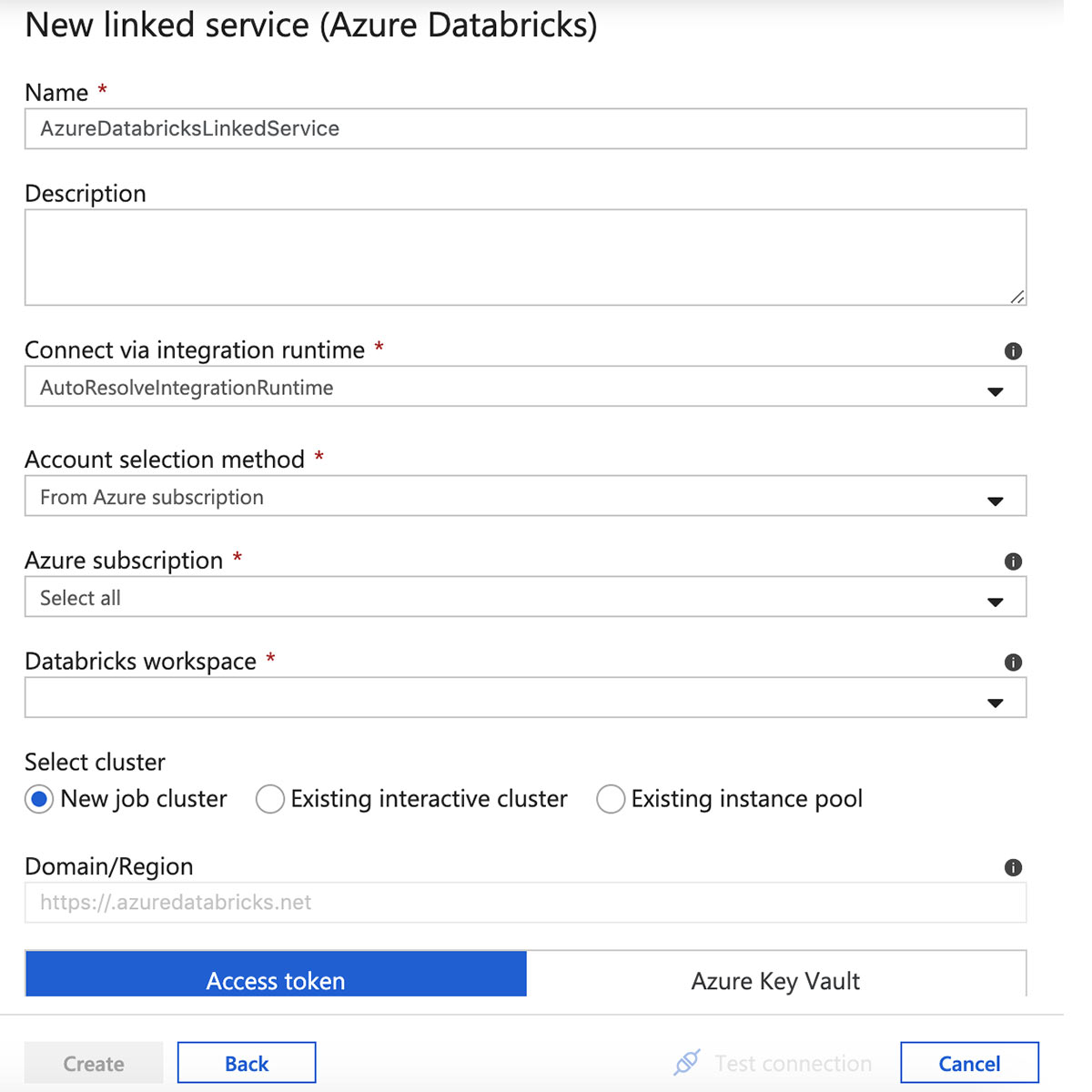
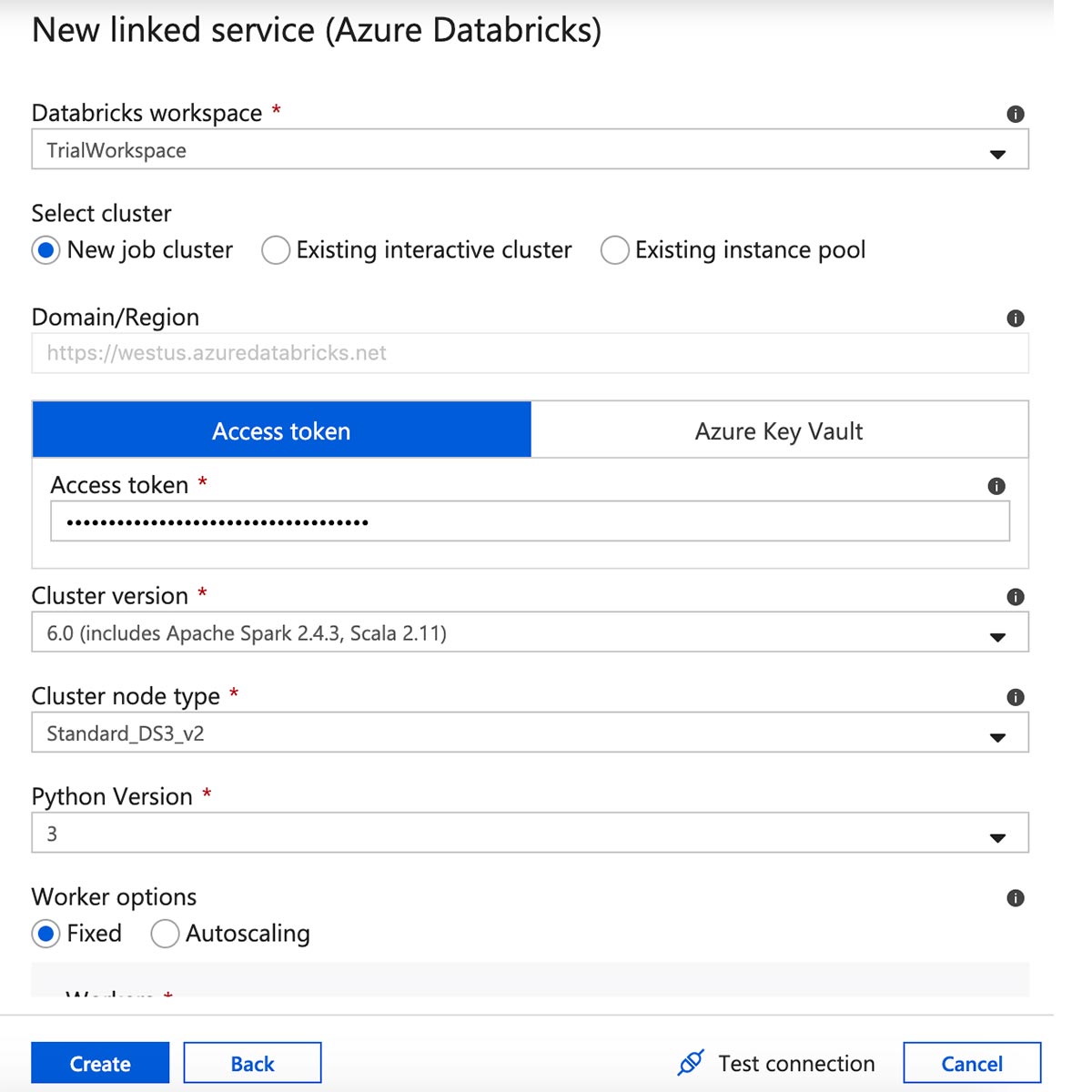
为Azure Databricks链接服务输入一个名称并选择一个工作空间。
通过单击屏幕右上角的用户图标,然后选择“用户设置”,从Azure Databricks工作区创建一个访问令牌。
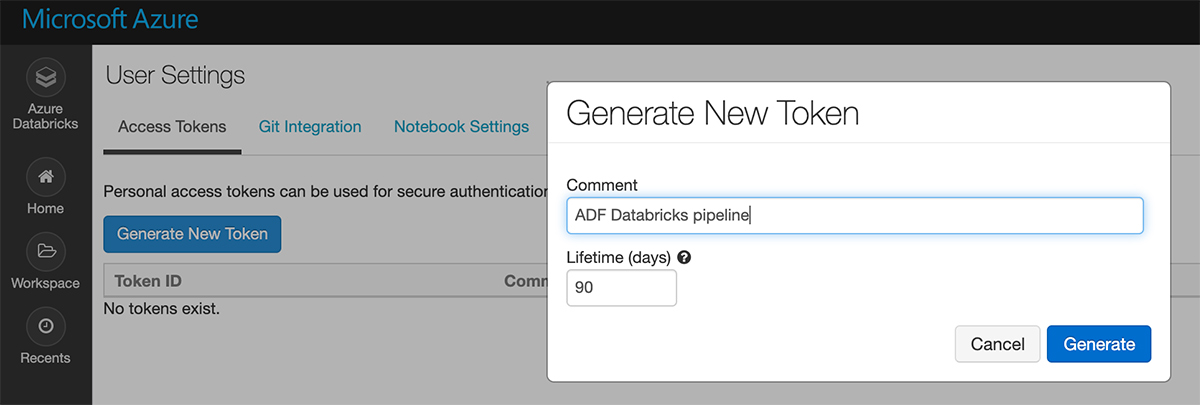
点击“生成新令牌”。
将令牌复制并粘贴到链接的服务表单中,然后选择集群版本、大小和Python版本。检查所有设置,然后单击“创建”。
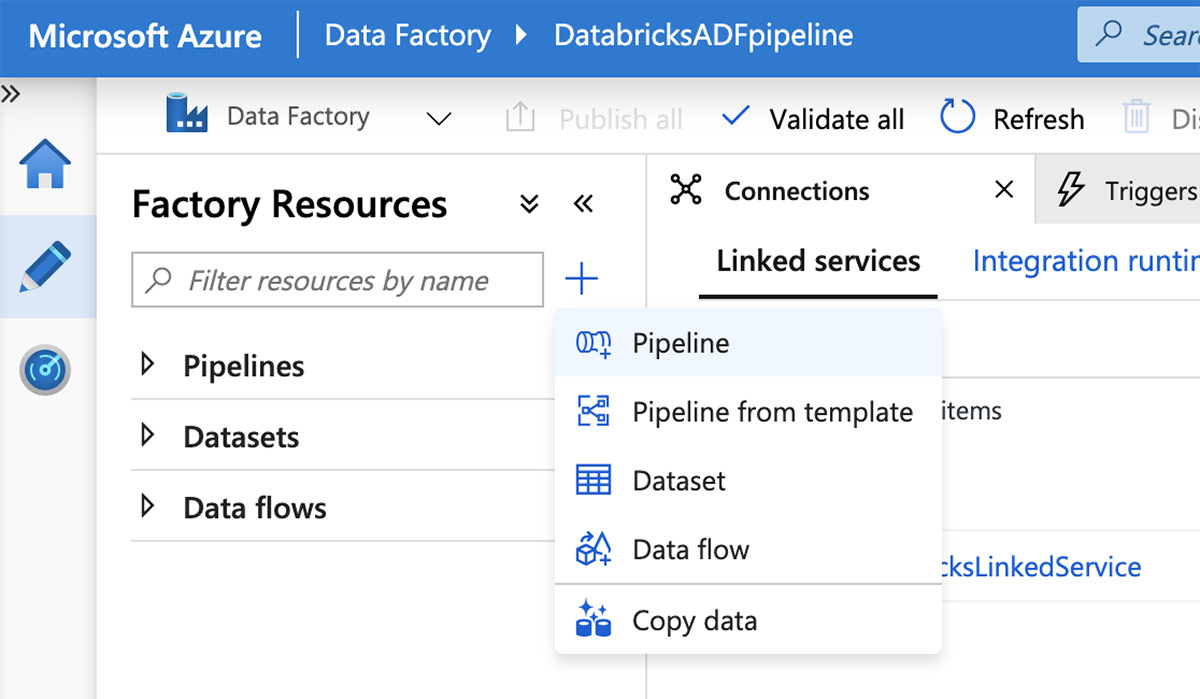
链接服务就绪后,就可以创建管道了。在Azure Data Factory UI中,点击加号(+)按钮并选择“Pipeline”。
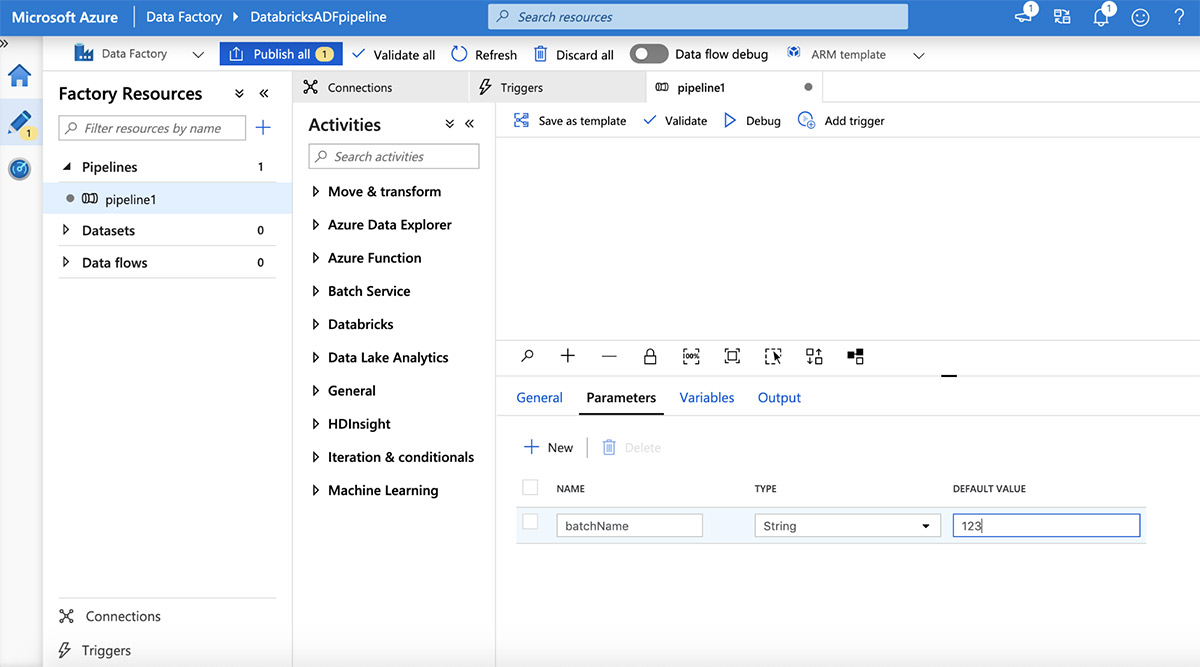
通过单击“Parameters”选项卡添加参数,然后单击加号(+)按钮。
接下来,通过展开“Databricks”活动向管道添加一个Databricks笔记本,然后将一个Databricks笔记本拖放到管道设计画布上。
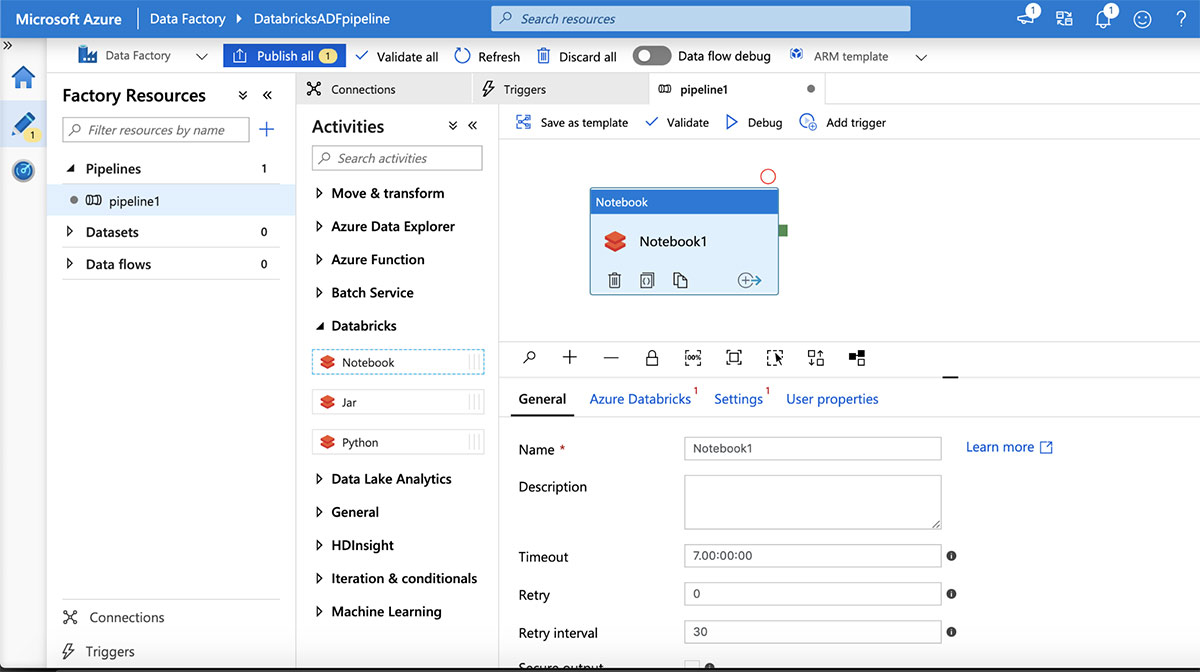
通过选择“Azure Databricks”选项卡并选择上面创建的链接服务来连接到Azure Databricks工作区。接下来,点击“Settings”选项卡指定笔记本路径。现在单击“Validate”按钮,然后单击“Publish All”,将其发布到ADF服务。
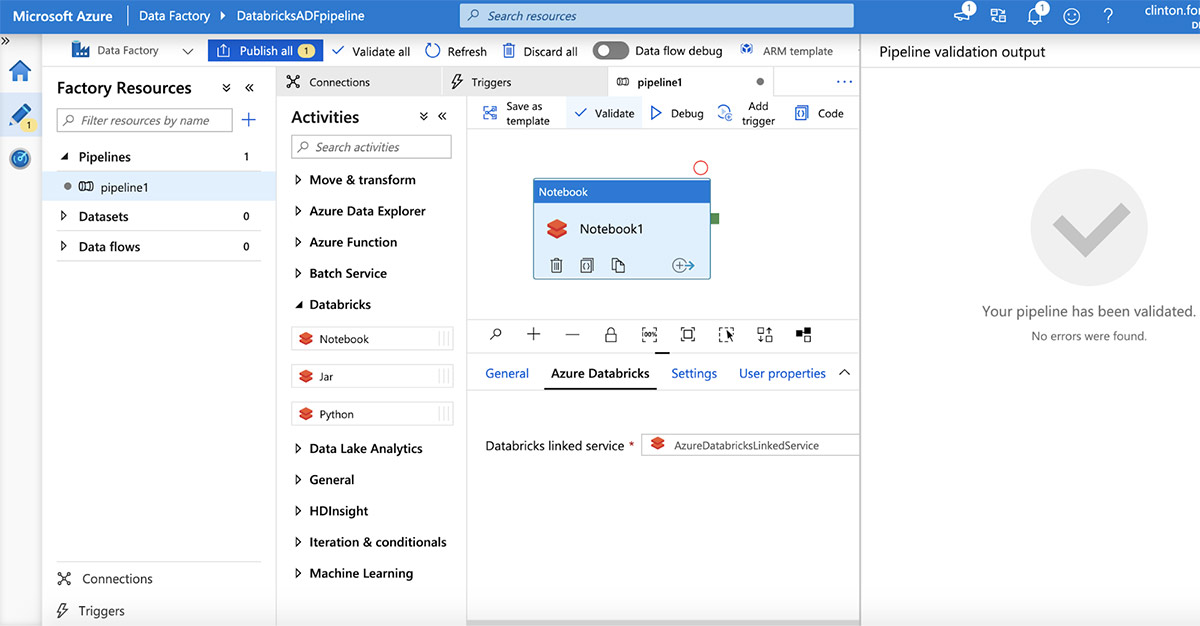
一旦发布,通过点击“Add trigger | trigger now”来触发管道运行。
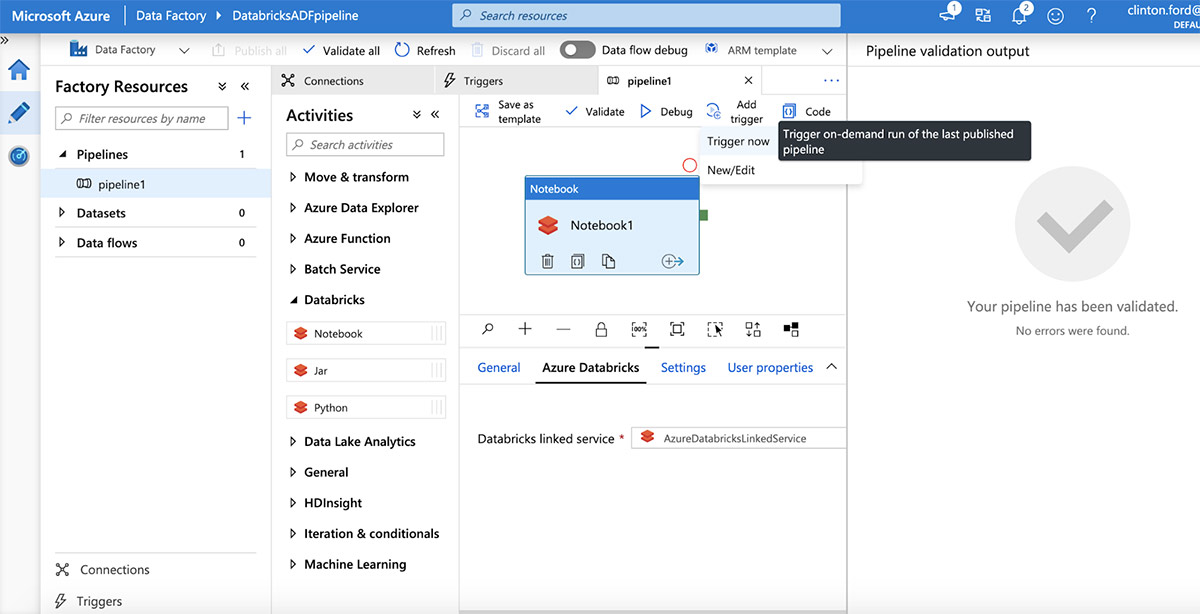
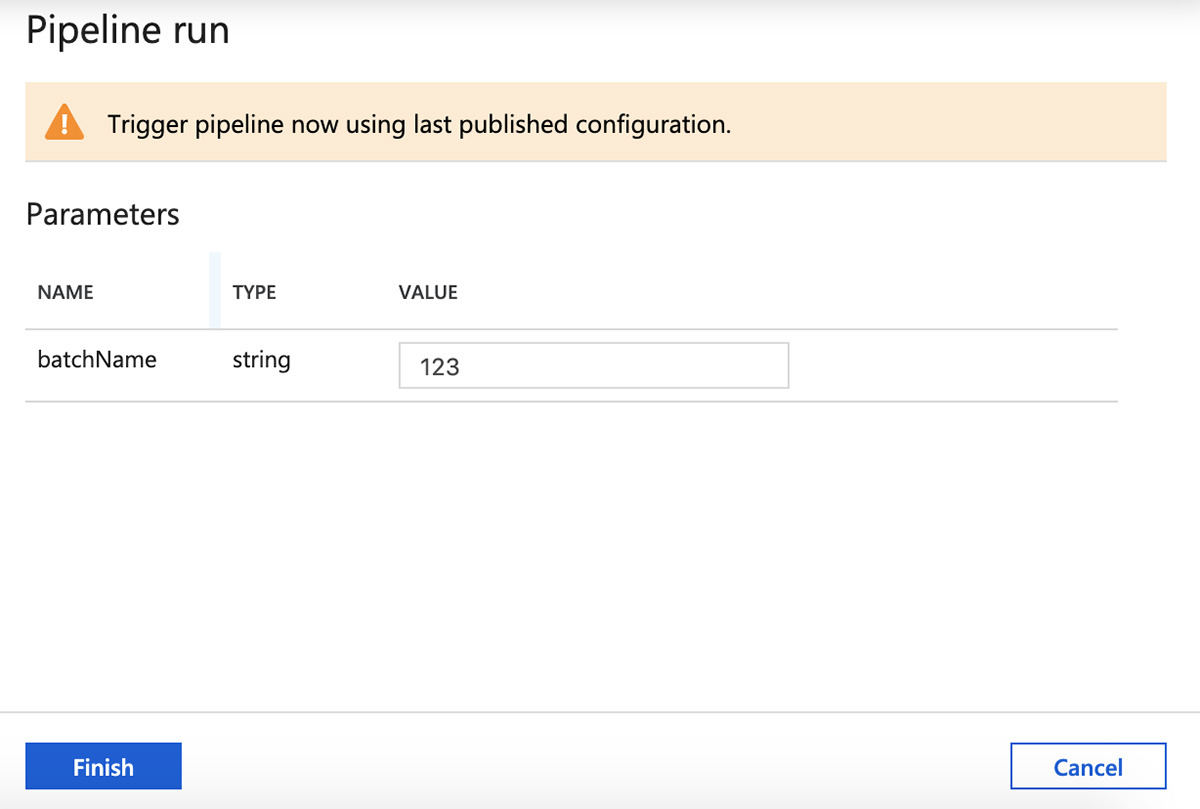
检查参数,然后单击“Finish”以触发管道运行。
现在切换到左侧面板上的“Monitor”选项卡,查看管道运行的进度。
将Azure Databricks笔记本集成到Azure数据工厂管道中,提供了一种灵活且可扩展的方式来参数化和操作自定义ETL代码。有关ABOB低频彩zure Databricks如何与Azure数据工厂(ADF)集成的更多信息,请参见这篇ADF博客文章而且ADF教程.要了解BOB低频彩更多关于如何探索和查询数据湖中的数据,请参阅此网络研讨会,使用SQL查询Delta Lake的数据湖.