三角洲湖数据摄取演示
免费开始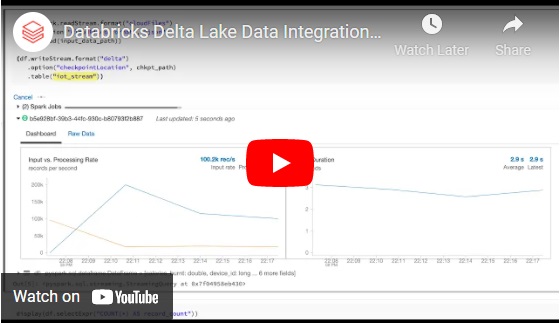

使用Databricks Auto Loader,一旦新的批处理和实时流数据文件到达您的数据湖,您就可以增量地、高效地将它们吸收到Delta Lake表中,以便它们始终包含可用的最完整和最新的数据。Auto Loader是一个简单、灵活的工具,可以连续运行,或在“triggerOnce”模式下批量处理数据。SQL用户可以使用简单的“COPY INTO”命令自动将新数据拉入他们的Delta Lake表,而不需要跟踪哪些文件已经被处理。
深入了解Databricks平台bob体育客户端下载


视频记录
用自动装载机把数据输入德尔塔湖
将原始数据加载到数据仓库中可能是一个混乱而复杂的过程,但是使用Databricks,用可用的最新数据填充Delta Lake变得从未如此简单。
在这里,我们正在使用来自物联网设备(如跟踪步骤的智能手表)的一些JSON遥测数据。每5秒就有新的数据文件进入我们的数据湖,所以我们需要一种方法来自动将它们吸收到Delta lake中。Auto Loader提供了一个名为“cloudFiles”的新的结构化流数据源,我们可以使用它来实现这一点。
点击展开文字记录→
点击折叠文本→
如何使用Databricks自动加载
首先,我们指定“cloudFiles”作为数据流的格式。接下来,我们指定要监视数据湖中的哪个目录以寻找新文件。一旦它们到达,Auto Loader就会有效地增量地将它们加载到我们指定的Delta Lake表中。
这样就完成了!使用Auto Loader就像按下原始数据摄取的“简单按钮”。我们不需要指定模式、设置消息队列或手动跟踪哪些文件已经被处理。在幕后,Auto Loader使用始终在线的文件通知服务跟踪新文件事件,这比在数据湖上运行昂贵的“列表”操作更快,更可扩展。
在批处理模式下使用triggerOnce自动加载
对于时间敏感的数据工作负载,连续运行Auto Loader是一件简单的事情。但是对于时间不太敏感的工作负载,您可以通过指定“triggerOnce”选项在“批处理模式”下运行Auto Loader,然后将笔记本设置为作为计划作业运行。在triggerOnce模式下,即使没有活动集群运行,Auto Loader仍然跟踪新文件——它只是等待实际处理它们,直到您再次手动运行Auto Loader代码,或者作为计划作业的一部分。
为SQL用户使用COPY INTO加载数据
最后,喜欢这种面向批处理的数据摄取方法的SQL用户可以使用COPY INTO命令。COPY INTO是一个可检索且幂等的命令,因此它会忽略已经处理过的数据,就像“triggerOnce”模式下的Auto Loader一样。
准备开始了吗?


