三角洲生活表(DLT)是第一个ETL框架,使用一个简单的声明性方法用于创建可靠的数据管道和全面管理批处理和底层基础设施的规模吗流数据。许多用例需要可行的见解来自附近的实时数据。增量住表可以低延迟流数据管道支持这样的用例通过直接摄取低延迟的数据事件等公交车Apache卡夫卡,AWS运动,汇合的云,亚马逊MSK的,或Azure的活动中心。
本文将介绍使用Apache的DLT卡夫卡,同时提供摄取所需的Python代码流。推荐系统架构将会解释说,和相关的DLT设置值得考虑将探索。
流媒体平台bob体育客户端下载
事件总线或消息总线分离消息生产者与消费者。一个流行的流媒体用例是点击率数据的收集来自用户的导航网站,每一个用户交互是Apache卡夫卡存储为一个事件。然后从卡夫卡事件流是用于实时流数据分析。多个消息的消费者可以从卡夫卡读取相同的数据和使用数据,了解受众利益,转化率,反弹的原因。从用户交互实时流媒体事件数据通常也需要与实际购买存储在数据库计费。
Apache卡夫卡
Apache卡夫卡是一个很受欢迎的开放源代码bob下载地址事件总线。卡夫卡使用主题的概念,一个扩展分布式日志事件的消息是一定的时间缓冲。虽然在卡夫卡不删除消息一旦消耗他们,他们也不会无限期保存。卡夫卡的消息保留可以配置每个主题,默认为7天。过期的信息最终将被删除。
这篇文章是围绕Apache卡夫卡;然而,概念也适用于许多讨论其他事件总线或消息传递系统。
流数据管道
在数据流管道,三角洲住表及其依赖关系可以用一个标准的SQL声明创建表选择DLT (cta)语句和关键字“生活”。
当发展与Python的DLT,@dlt.table修饰符是用来创建一个三角洲住表。确保数据质量在一个管道,DLT用途预期简单的SQL的约束条款定义管道的行为与无效记录。
由于流媒体工作负载常常有不可预测的数据量,数据砖使用增强自动定量为数据流管道,以减少整体的端到端延时,同时降低成本通过关闭不必要的基础设施。
三角洲生活表完全重新计算,以正确的顺序,每个管道运行一次。
相比之下,流三角洲生活表是有状态的,增量计算和处理数据,添加了自上次管道运行。如果查询的定义了一个流媒体直播表变化,新的数据处理基于新的查询,但现有的数据重新计算。流媒体直播表总是使用流媒体来源,只有在扩展流,如卡夫卡,运动,或者自动加载程序。流dlt是基于结构化流火花。
可以链多个流管道,例如,工作量非常大的数据量和低延迟的要求。
直接摄入流引擎
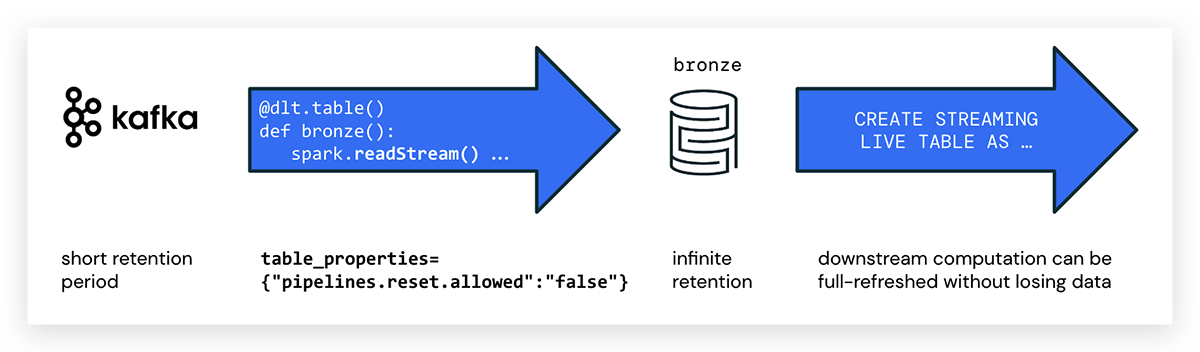
三角洲生活表写在Python中可以直接摄取数据从一个事件总线使用结构化流火花就像卡夫卡。你可以设置一个短停留时间对卡夫卡的话题避免合规问题,降低成本和受益于廉价,三角洲所提供的弹性和可控制的存储。
作为第一步,我们建议摄入数据是青铜(生)表,避免复杂的转换,可以将重要数据。像任何三角洲表铜表将保留历史和允许执行GDPR和其他执行任务。
从Apache卡夫卡摄取流数据
当编写DLT管道在Python中,您使用@dlt.table创建一个DLT表注释。没有特殊的属性标记流dlt在Python中;简单地使用spark.readStream ()访问流。示例代码创建一个DLT表的名称kafka_bronze消费数据从卡夫卡主题如下:
进口dlt从pyspark.sql.functions进口*从pyspark.sql.types进口*主题=“tracker-events”KAFKA_BROKER = spark.conf.get (“KAFKA_SERVER”)#在KAFKA_BROKER订阅话题raw_kafka_events = (spark.readStream。格式(“卡夫卡”).option (“订阅”、主题).option (“kafka.bootstrap.servers”KAFKA_BROKER).option (“startingOffsets”,“最早”).load ())@dlt.table (table_properties = {“pipelines.reset.allowed”:“假”})defkafka_bronze():返回raw_kafka_events
pipelines.reset.allowed
注意事件公共汽车通常过期消息一段时间后,而三角洲是专为无限的保留。
这可能导致在卡夫卡的影响源数据已经删除DLT管道在运行一个完整的刷新。在这种情况下,并不是所有的历史数据可以从消息传递平台、回填和数据会丢失DLT表。bob体育客户端下载为了防止删除数据,使用以下DLT表属性:
pipelines.reset.allowed = false
设置pipelines.reset.allowed假防止刷新表但并不妨碍增量写入表或新流入的数据表。
检查点
如果你是一个有经验的火花结构化流开发人员,你会发现没有检查点在上面的代码。在火花结构化流检查点需要持续进步已成功处理信息数据失败,这个元数据用于重新启动失败的查询具体位置。
而对故障恢复检查点是必要的火花结构化流仅一次保证,DLT自动处理状态,而不需要任何手动配置或显式检查点。
混合SQL和Python DLT管道
DLT管道可以包含多个笔记本,但一个DLT笔记本需要完全用SQL编写或Python(不像其他砖笔记本,你可以有细胞不同的语言在一个笔记本)。
现在,如果你的偏好是SQL,您可以从Apache代码数据摄入卡夫卡在一个笔记本在Python中,然后实现数据的转换逻辑管道在另一个笔记本在SQL。
模式映射
从消息传递平台读取数据时,数据流是不透明的,必须提供一个模式。bob体育客户端下载
下面的Python示例显示了从健身追踪事件的模式定义,以及价值的一部分卡夫卡消息映射这个模式。
event_schema = StructType ([\StructField (“时间”、TimestampType ()真正的),\StructField (“版本”、StringType ()真正的),\StructField (“模型”、StringType ()真正的),\StructField (“heart_bpm”、IntegerType ()真正的),\StructField (“千卡”、IntegerType ()真正的)\])
#临时表,可见在管道而不是在数据浏览器,#不能查询交互@dlt.table (评论=“真正的Kakfa负载模式”,临时=真正的)
defkafka_silver():返回(#卡夫卡流(时间戳值)#价值包含了卡夫卡的有效载荷dlt.read_stream (“kafka_bronze”).select(坳(“时间戳”),from_json(坳(“价值”).cast (“字符串”),event_schema) .alias (“事件”)).select (“时间戳”,“。*”))
好处
阅读流数据直接从message broker DLT最小化架构复杂性并提供较低的端到端延时自数据直接从消息传递代理和中介流的步骤。
流摄取与云对象存储媒介
用于一些特定的情况下,您可能希望将数据从Apache卡夫卡,例如,使用卡夫卡连接器和存储流数据在云对象中介。砖的工作区,云通过砖可以映射到特定于供应商的对象存储文件系统(DBFS)作为cloud-independent文件夹。一旦数据卸载,砖自动加载程序可以摄取的文件。
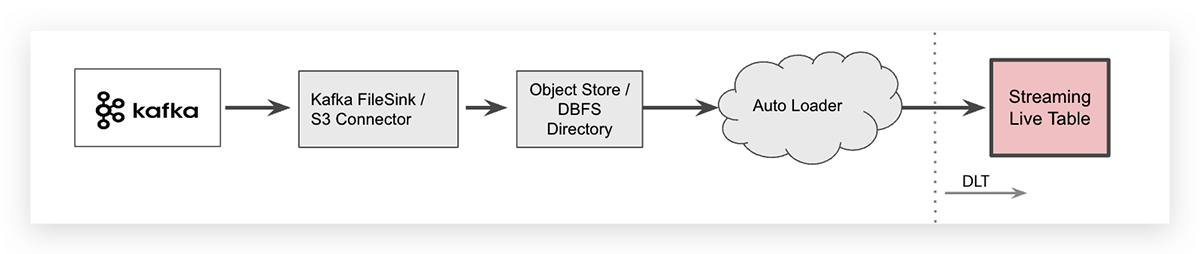
自动加载器可以摄取数据与一行的SQL代码。语法来摄取的JSON文件到一个DLT表如下所示(它是包裹在两行可读性)。
——摄取自动加载程序创建或更换现场直播表生作为选择*从cloud_files (“dbfs: /数据/ twitter”,“json”)
注意自动加载器本身就是一个流数据源和新来的所有文件将被处理一次,因此,原始表显示数据流媒体关键字是摄取增量表。
自卸载流数据到云对象存储了一个额外的步骤在您的系统架构也会增加端到端延迟和创建额外的存储成本。记住,卡夫卡连接器写事件数据到云对象存储需要管理,增加操作的复杂性。
因此砖建议作为最佳实践的直接访问事件总线数据使用火花从DLT结构化流如上所述。
其他事件总线或消息传递系统
这篇文章是围绕Apache卡夫卡;然而,讨论的概念也适用于其他事件总线或消息传递系统。DLT支持任何数据源数据砖运行时直接支持。
亚马逊运动
在运动中,你写消息完全托管serverless流。卡夫卡一样,动作不永久存储消息。默认的消息保留在运动是一天。
当使用亚马逊动作,替换格式(“卡夫卡”)格式(“运动”)在上面的Python代码流摄入和增加亚马逊Kinesis-specific设置选项()。关于更多信息,检查部分运动的集成在火花结构化流文档。
Azure的活动中心
Azure活动中心设置,检查官员微软文档和这篇文章三角洲表食谱:生活消费从Azure事件中心。
总结
DLT不仅仅是ETL的“T”。DLT,您可以很容易地从流和批处理来源摄取,清理和转换数据砖Lakehouse平台上任何云保证数据质量。bob体育客户端下载
数据从Apache卡夫卡可摄入通过直接连接到卡夫卡从Python中的DLT笔记本代理。数据丢失是可以预防的一个完整的管道刷新即使卡夫卡的源数据流层过期了。
开始
如果你是一个砖客户,只是遵循导游开始。阅读发布说明了解更多关于什么是包含在该通用版本。BOB低频彩如果你没有一个现有的砖的客户,注册一个免费试用,您可以查看我们的详细的DLT定价在这里。
加入的谈话砖社区data-obsessed同行在哪里聊天关于数据+人工智能峰会2022公告和更新。学习。网络。
最后但并非最不重要,享受深入研究数据工程会话的峰会。在该会话,我通过另一个流数据的代码例子微博直播,自动加载程序,三角洲住表的SQL,拥抱面临情绪分析。