





细粒度的时间序列预测规模与Facebook先知和Apache火花
试试这个时间序列预测笔记本需求预测我们的解决方案加速器。时间序列预测的发展使得零售商产生……
2020年1月27日 在公司博客上
试试这个时间序列预测的笔记本中为需求预测解决方案加速器。
时间序列预测的发展使得零售商产生更可靠的需求预测。现在的挑战是产生这些预测及时和粒度级别,允许业务进行精确调整产品库存。利用Apache火花™和Facebook的先知面临这些挑战,越来越多的企业发现他们可以克服过去的可伸缩性和精度限制的解决方案。
在这篇文章中,我们将讨论时间序列预测的重要性,想象一些样本时间序列数据,然后构建一个简单的模型来展示使用Facebook的先知。一旦你舒适的构建一个模型,我们会把先知与Apache的魔力火花™展示如何训练数以百计的模型,允许我们创建为每个单独的产品库存组合在一个精确的预测的粒度级别很少实现直到现在。
提高时间序列分析的速度和准确性,以更好地预测对产品和服务的需求对零售商的成功至关重要。如果太多的产品装在一个商店,货架和仓库空间可以紧张,产品到期,和零售商可能会发现他们的财务资源是绑在库存,使得他们不能够利用新的机会由制造商或消费模式的转变。如果太少的产品装在一个商店,顾客可能无法购买他们需要的产品。不仅这些预测错误导致零售商立即减少了收入,但随着时间的推移,消费者对竞争对手顾客可能会失望。
一段时间以来,企业资源规划(ERP)系统和第三方解决方案为零售商提供了需求预测能力基于简单的时间序列模型。但随着科技的进步和增加压力,许多零售商正在寻找超越线性模型和更传统的算法在历史上。
提供的新功能,例如Facebook的先知新兴数据科学社会,公司正在寻求灵活地应用这些机器学习模型的时间序列预测的需要。
这个运动远离传统预测解决方案需要零售商等自主研发的专业技能不仅在需求预测的复杂性,而且在有效分配所需的工作来生成成百上千,甚至成千上万的机器学习模型及时。幸运的是,我们可以使用火花分发这些模型的训练,使其不仅可以预测总体需求的产品和服务,但是为每个产品在每个位置的独特需求。
演示使用先知产生细粒度为个人商店和产品需求预测,我们将使用公开可用数据集Kaggle。它由5年的每日销售数据50个人物品在10个不同的商店。
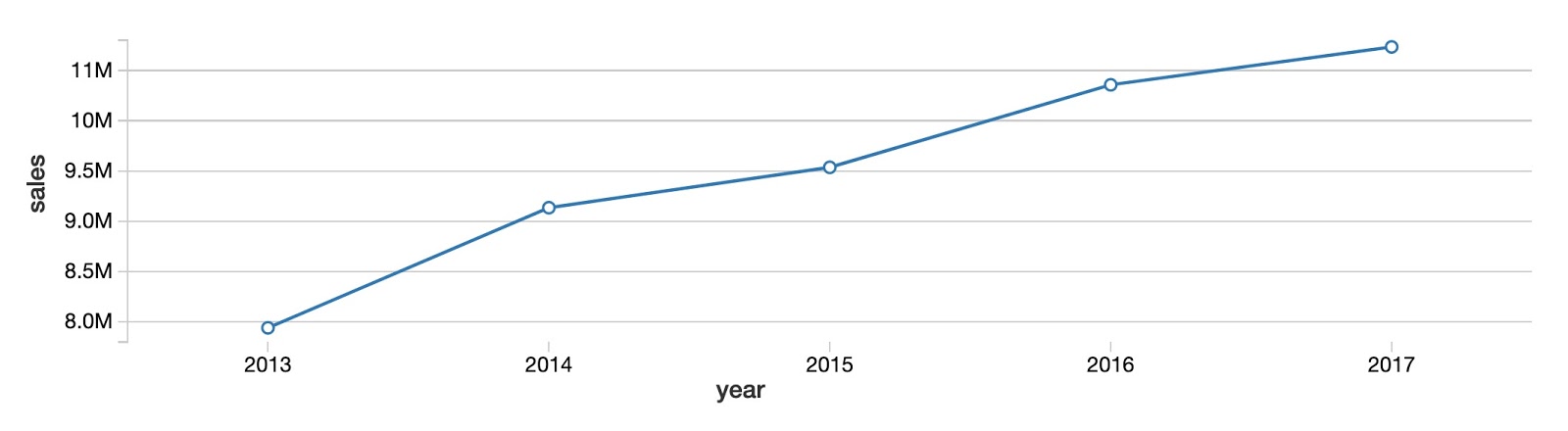
首先,让我们看看所有产品的年度总销量趋势和商店。正如你所看到的,产品销售总额同比增加没有明确的收敛在高原的迹象。
 接下来,通过查看相同的数据在每月的基础上,我们可以看到每个月同比稳步上升趋势不进步。相反,我们看到一个清晰的季节性模式,在夏季峰值和低谷在冬季。使用内置的数据可视化的特点砖协作笔记本的值,我们可以看到我们的数据在每个月把鼠标移到图表。
接下来,通过查看相同的数据在每月的基础上,我们可以看到每个月同比稳步上升趋势不进步。相反,我们看到一个清晰的季节性模式,在夏季峰值和低谷在冬季。使用内置的数据可视化的特点砖协作笔记本的值,我们可以看到我们的数据在每个月把鼠标移到图表。
星期天在工作日级别、销售高峰(工作日0),其次是很难下降周一(工作日1),然后稳步恢复在剩下的一周。
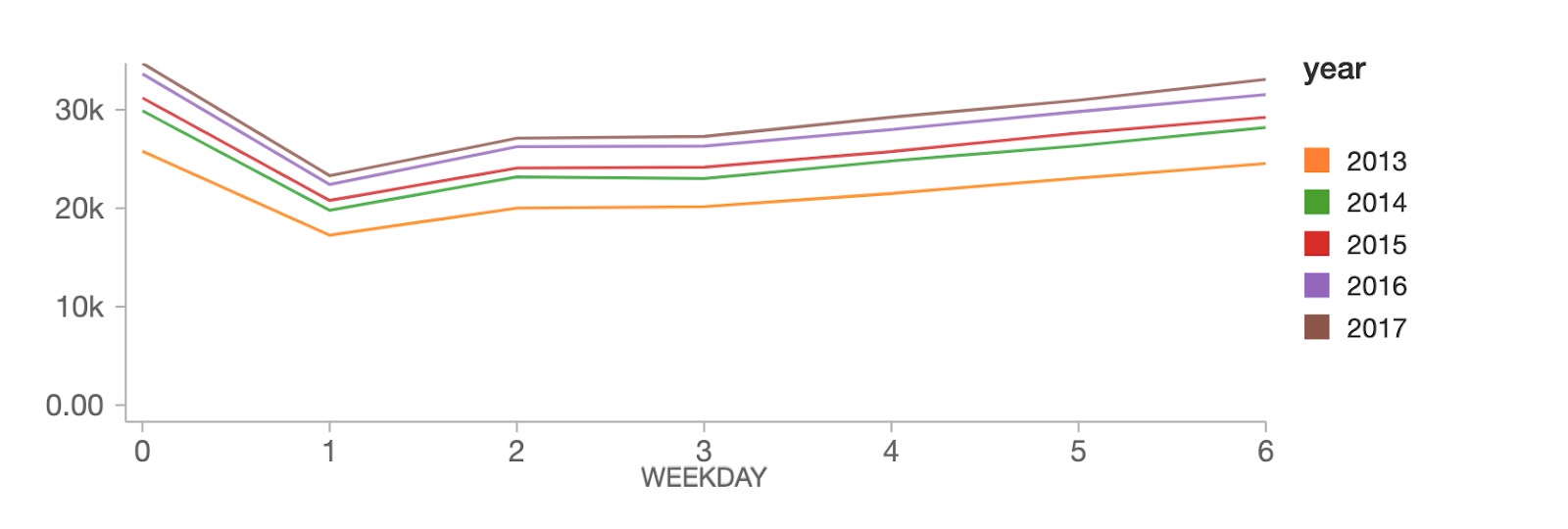
见上面的图表中,我们的数据显示一个明确的销售额同比上升趋势,以及年度和每周的季节性模式。正是这些先知的数据重叠模式旨在解决。
Facebook先知遵循scikit-learn API,所以应该很容易接任何有sklearn经验。我们需要通过一个2列熊猫DataFrame作为输入:第一列的日期,第二个是价值预测(在我们的例子中,销售)。一旦我们的数据的格式是正确,构建一个模型很容易:
进口熊猫作为pd从fbprophet进口先知#实例化模型和设置参数模型=先知(interval_width =0.95,增长=“线性”,daily_seasonality =假,weekly_seasonality =真正的,yearly_seasonality =真正的,seasonality_mode =“乘法”)#适合模型的历史数据model.fit (history_pd)现在我们已经符合我们的数据模型,我们使用它来构建一个90天的预测。在以下代码中,我们定义了一个数据集,包括历史日期和90天以外,利用先知的make_future_dataframe方法:
future_pd = model.make_future_dataframe (时间=90年,频率=' d ',include_history =真正的)#预测数据集forecast_pd = model.predict (future_pd)就是这样!现在我们可以想象我们的实际和预测数据排队以及预测未来使用先知的内置.plot方法。正如你所看到的,每周我们之前说明和季节性需求模式实际上是反映在预测结果。
predict_fig =模型。情节(forecast_pd包含=“日期”ylabel =“销售”)显示(图)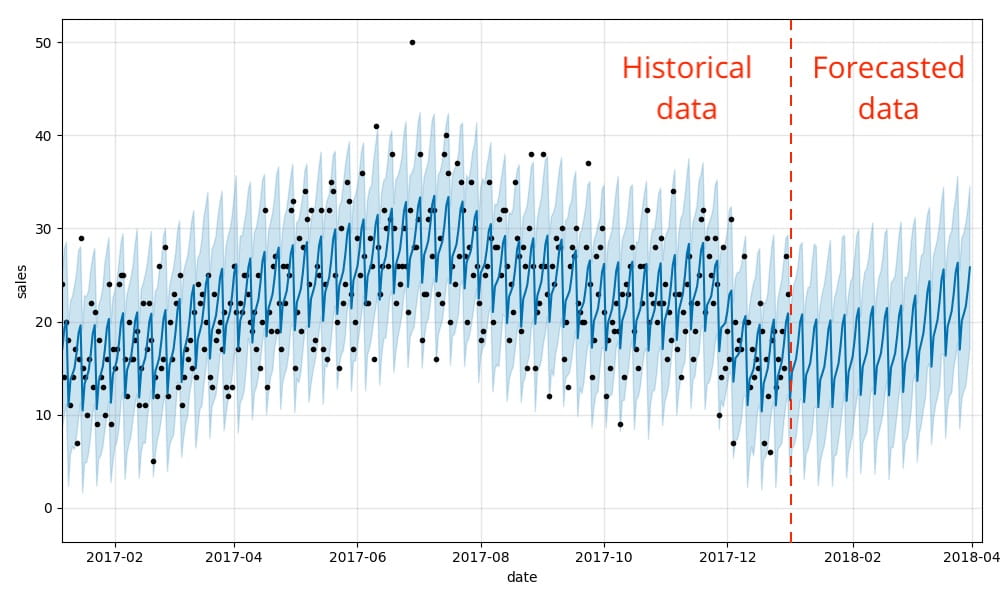
该可视化有点忙。Bartosz Mikulski提供一个优秀的崩溃它很值得一看。简而言之,黑点代表我们的实绩与暗蓝线代表我们预测和浅蓝色乐队代表(95%)不确定性区间。
既然我们已经演示了如何构建一个单一时间序列预测模型,我们可以使用Apache火花的力量把我们的努力。我们的目标是为整个数据集生成不是一个预测,但数以百计的模型和预测对于每个产品库存的组合,这将非常耗时的执行顺序操作。
构建模型以这种方式可以使连锁杂货店,例如,创建一个精确的预估的牛奶量他们应该为自己的桑达斯基顺序存储,不同于所需的克利夫兰商店,基于不同的需求在这些位置。
数据科学家经常应对培训大量的挑战模型使用一个分布式数据处理引擎等Apache火花。通过利用一个火花集群,个体劳动者集群中的节点可以训练与其他工人并行模型的一个子集节点,大大降低了所需总时间训练时间序列模型的整个集合。
当然,训练模型节点集群上的工人(电脑)需要更多的云基础设施,这是要付出代价的。但是简单的随需应变的云资源的可用性,企业可以迅速提供他们所需的资源,训练他们的模型,并释放这些资源一样快,使他们实现大规模可扩展性没有实物资产的长期承诺。
实现分布式数据处理的关键机制引发的DataFrame。加载数据到火花DataFrame,数据分布在集群中的工人。这允许这些工人来处理数据的子集以类似的方式,减少了整体的执行我们的工作所需的时间。
当然,每个工人需要访问数据的子集它需要做的工作。通过分组键值的数据,在这种情况下存储和项目组合,我们汇集所有的时间序列数据的键值到一个特定的工作节点。
store_item_history.groupBy (“存储”,“项目”)#。我们分享groupBy代码来强调它如何使我们许多并行模型有效地训练,虽然它不会真正发挥作用,直到我们设置和应用一个UDF在下一节我们的数据。
与我们的正常时间序列数据分组的存储和项目,我们现在需要训练一个模型为每个组。为了实现这一点,我们可以使用一个熊猫用户定义函数(UDF),它允许我们自定义函数应用于DataFrame每组数据。
这个UDF将不仅为每组训练模型,但也生成一个结果集代表的预测模型。虽然函数将每组训练和预测DataFrame独立于他人,从每一组返回的结果将被方便地收集到单一DataFrame。这将使我们能够生成存储项目水平预测但分析师和基金经理提出我们的结果作为一个单独的输出数据集。
可以看到在下面的缩写Python代码中,建设我们的UDF是相对简单的。的UDF被实例化pandas_udf方法确定它将返回的数据模式和数据,预计接收的类型。这之后,我们定义的函数将执行的工作UDF。
在函数定义中,我们实例化模型、配置和适应它已收到的数据。模型进行预测,数据返回的输出函数。
@pandas_udf (result_schema, PandasUDFType.GROUPED_MAP)defforecast_store_item(history_pd):#实例化模型,配置参数模型=先知(interval_width =0.95,增长=“线性”,daily_seasonality =假,weekly_seasonality =真正的,yearly_seasonality =真正的,seasonality_mode =“乘法”)#符合模型model.fit (history_pd)#配置预测future_pd = model.make_future_dataframe (时间=90年,频率=' d ',include_history =真正的)#做出预测results_pd = model.predict (future_pd)#。#回归预测返回results_pd现在,把它放在一起,我们使用groupBy命令我们前面讨论,以确保我们的数据集是正确划分的团体,代表着特定的存储和项的组合。然后我们简单应用的UDF DataFrame,允许UDF来适应一个模型,使预测在每个分组的数据。
返回的数据集的应用功能,每组更新以反映的日期我们生成的预测。这将帮助我们跟踪生成的数据在不同的模型作为我们最终的功能投入生产运行。
从pyspark.sql。功能导入当前日期结果=(store_item_history.groupBy (“存储”,“项目”)苹果(forecast_store_item).withColumn (“training_date”,当前日期()))我们已经构建了一个时间序列预测mdoel为每个存储项目组合。使用一个SQL查询,分析师可以查看每个产品的定制的预测。在下面的图表中,我们绘制投影产品10 # 1在商店的需求。正如你所看到的,需求预测从商店到商店,但所有商店的一般模式是一致的,正如我们所期望的。
作为新的销售数据到达,我们可以有效地生成新的预测并将这些附加到我们现有的表结构,允许分析师更新业务的预期发展条件。
为了了BOB低频彩解更多,看点播网络研讨会资格星巴克如何预测需求规模与Facebook先知和Azure砖吗看看我们的为需求预测解决方案加速器。
