



使用Databricks Delta和AWS Glue数据目录服务转换您的AWS数据湖
在这篇博客文章中,我们将探索如何可靠有效地将您的AWS数据湖无缝转换为Delta湖,使用…
在这篇博客文章中,我们将探索如何可靠有效地转换你的AWS数据湖成一个三角洲湖无缝使用AWS胶水数据目录服务。AWS Glue服务是一个Apache兼容的Hive无服务器metastore,允许您轻松地跨AWS服务、应用程序或AWS帐户共享表元数据。
这提供了几个具体的好处:
此参考实现说明了Databricks Delta Lake与AWS核心服务的独特定位集成,可帮助您解决最复杂的问题数据湖挑战。
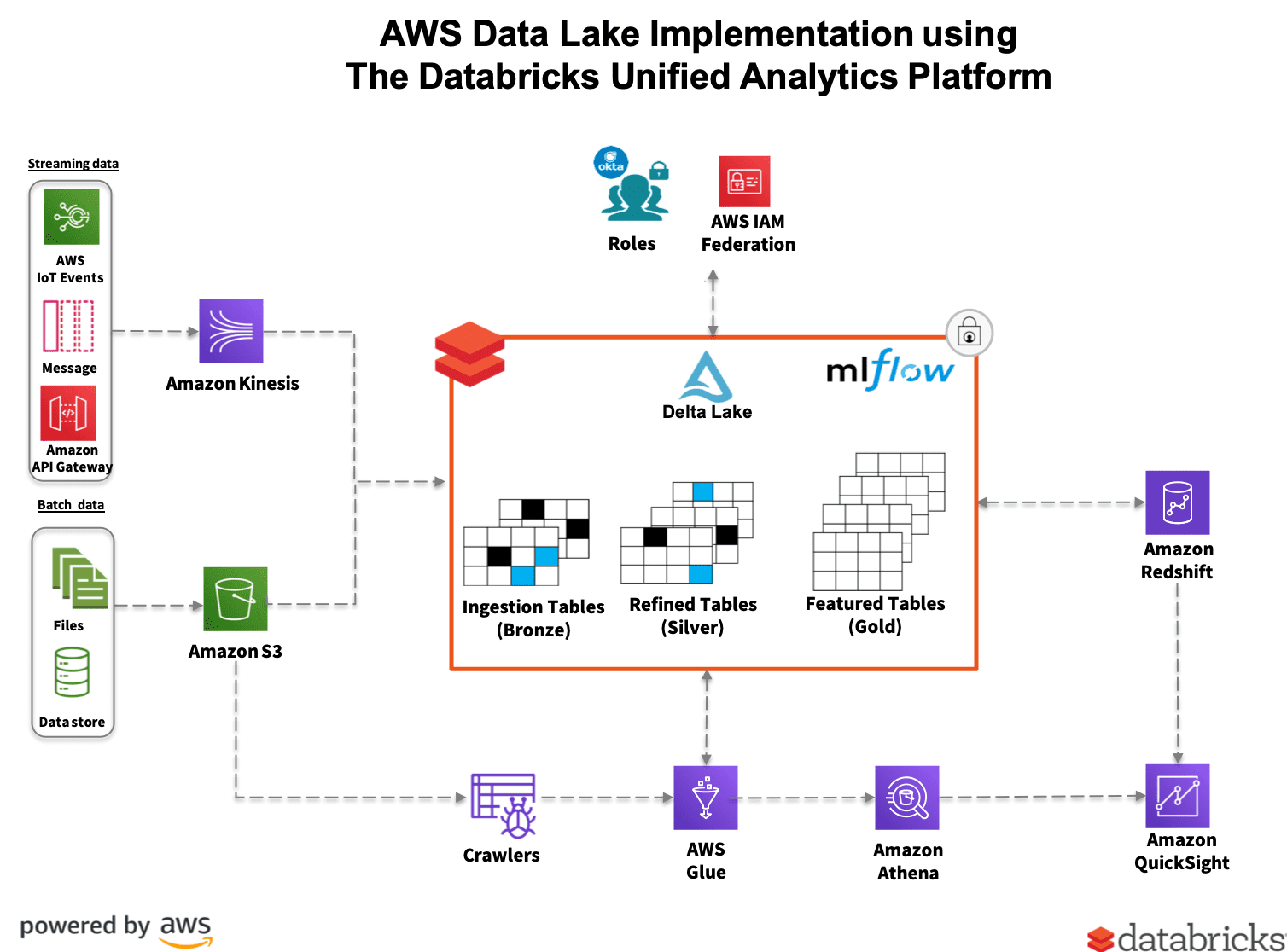
Delta Lake是一个开源存储bob下载地址层,为数据湖带来可靠性。Delta Lake提供ACID事务,可扩展的元数据处理,并统一流和批处理数据。Delta Lake运行在您现有的数据湖之上,并且完全兼容Apache Spark api。
下载这个电子书了解数据湖通常面临的关键数据可靠性挑战,以及Delta Lake如何帮助解决这些挑战。
Databricks最近在2019年Spark峰会上开放了Delta Lake的源代码。你可以在这里了解BOB低频彩更多关于三角洲湖的信息delta.io.
从Databricks运行时5.5开始,您现在可以从Presto和Amazon Athena查询Delta Lake表。当使用清单文件在Hive metastore中定义外部表时,Presto和Amazon Athena使用清单文件中的文件列表,而不是通过目录列表查找文件。可以像查询以Parquet等格式存储数据的表一样查询这些表。
首先,必须启动数据计算集群使用必要的AWS Glue Catalog IAM角色。IAM角色和策略需求在Databricks AWS Glue作为Metastore文档.
出于本博客的目的,我创建了一个AWS IAM角色,名为Field_Glue_Role它也委托了我的S3桶的访问权。我将该角色附加到我的集群配置,如图1所示。
图1所示。
https://www.youtube.com/watch?v=g73JZF1qgY4
接下来,Spark配置属性的集群配置之前集群启动,如图2所示。
图2。更新Databricks Cluster Spark Configuration属性
https://www.youtube.com/watch?v=D1_L0tFEmEg
在创建AWS Glue数据库之前,让我们将集群附加到上一步创建的笔记本上,并发出以下命令测试您的设置:
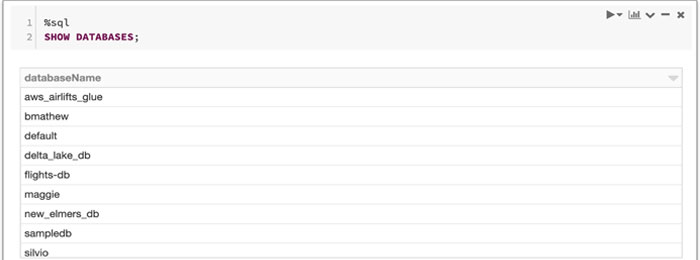
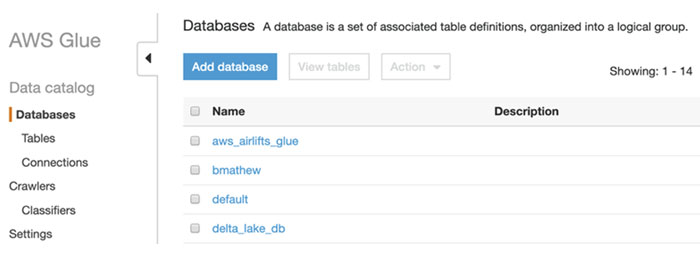
然后验证使用AWS Glue控制台显示相同的数据库列表,并列出这些数据库。
我们现在已经准备好直接从我们的笔记本中创建一个新的AWS Glue数据库,如下所示:
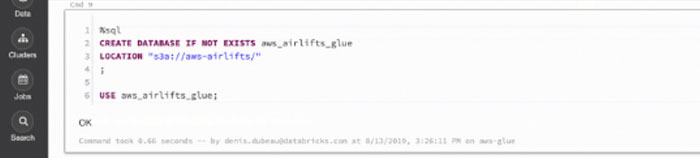
通过重新发布SHOW DATABASES,验证新的AWS Glue数据库已经成功创建。AWS Glue数据库也可以通过数据窗格查看。
https://www.youtube.com/watch?v=NHrp3x-u7xk
现在,让我们直接从笔记本创建表并将其编入AWS Glue Data catalog。参考如何填充AWS Glue数据目录用于使用爬虫程序创建和编目表。
我用的是电影推荐网站MovieLens由电影评分组成的数据集。我首先用以下python代码创建了一个DataFrame:

然后将DataFrame注册为一个临时表,使用SQL访问它,如下:

现在让我们使用SQL和上一步创建的临时表创建一个Delta Lake表:
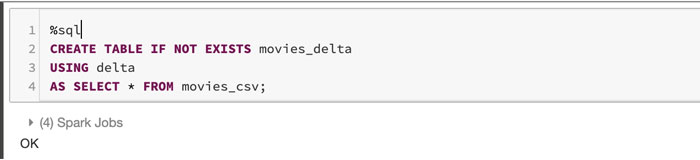
注意:像Delta Lake中描述的那样创建Delta Lake表非常容易三角洲湖快速入门指南.
现在,我们可以使用以下步骤生成Amazon Athena所需的清单文件。

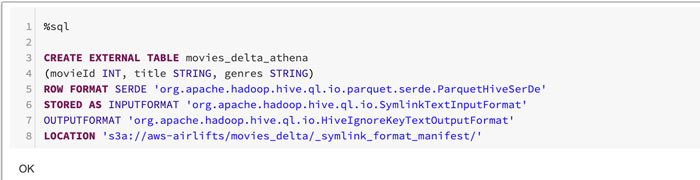
在上面的示例代码中,注意清单文件是在s3a: / / aws-airlifts movies_delta / _symlink_format_manifest /文件的位置。
Athena是一种无服务器服务,不需要任何基础设施来管理和维护。因此,您可以查询Delta表,而不需要Databricks集群运行。
从Amazon Athena控制台,选择您的数据库,然后预览表,如下所示:
https://www.youtube.com/watch?v=zkr8fgjnxf0
在AWS Glue的支持下,我们为所有使用AWS生态系统的企业引入了强大的无服务器metastore策略。此外,我们正在通过Delta Lake提升您的数据湖的可靠性,并通过与Amazon Athena集成为您的企业提供无缝的无服务器数据访问。
现在,您可以安全地让分析师、数据工程师和数据科学家使用Databricks统一分析平台为AWS上的数据湖战略提供支持。bob体育亚洲版bob体育客户端下载
相关资源: