
Databricks和Informatica加速智能数据管道的开发和完整的数据治理

分析和机器学习对组织的价值是众所周知的。我们最近的CIO调查显示,90%的组织正在投资分析、机器学习和人工智能。但我们也注意到,最大的障碍是在正确的地方以正确的格式获取正确的数据。因此,我们与Informatica合作,通过提供新的方法来发现、摄取和准备用于分析的数据,使组织获得更大的成功。
将数据直接输入三角洲湖
从混合数据源获取大量数据数据湖以一种可靠和高性能的方式是困难的。数据集经常被丢弃在不受管理的数据湖中,没有任何目的。数据被转储到没有一致格式的数据湖中,因此不可能混合读取和追加。数据也可能在写入数据湖的过程中被损坏,因为写入可能失败并留下部分数据集。
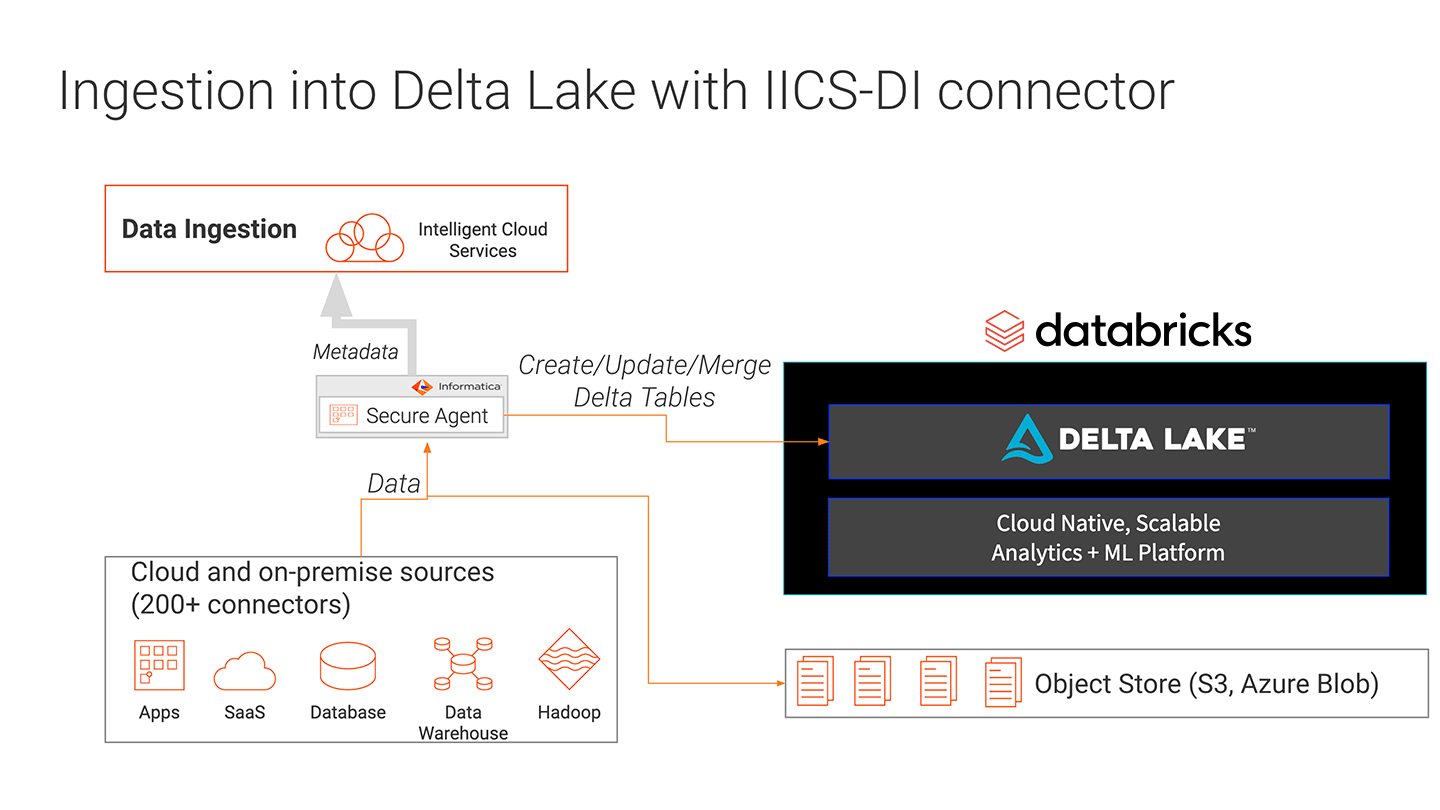
Informatica数据工程集成(DEI)支持从多个数据源摄取数据。通过将DEI与Delta Lake集成,摄入可以在Delta Lake的好处下进行。ACID事务确保写操作完成,或者在写操作失败时进行回退,不会留下任何工件。Delta Lake模式强制确保数据类型是正确的,并且存在所需的列,从而防止坏数据导致数据损坏。Informatica DEI和Delta Lake之间的集成使数据工程师能够将数据吸收到具有高可靠性和高性能的数据湖中。
准备
每个组织在格式化数据用于分析方面的资源都是有限的。确保数据集可以用于ML模型需要复杂的转换,创建这些转换需要花费时间。没有足够高技能的数据工程师可以为大规模数据编写高级ETL转换代码。此外,ETL代码很难排除故障或修改。
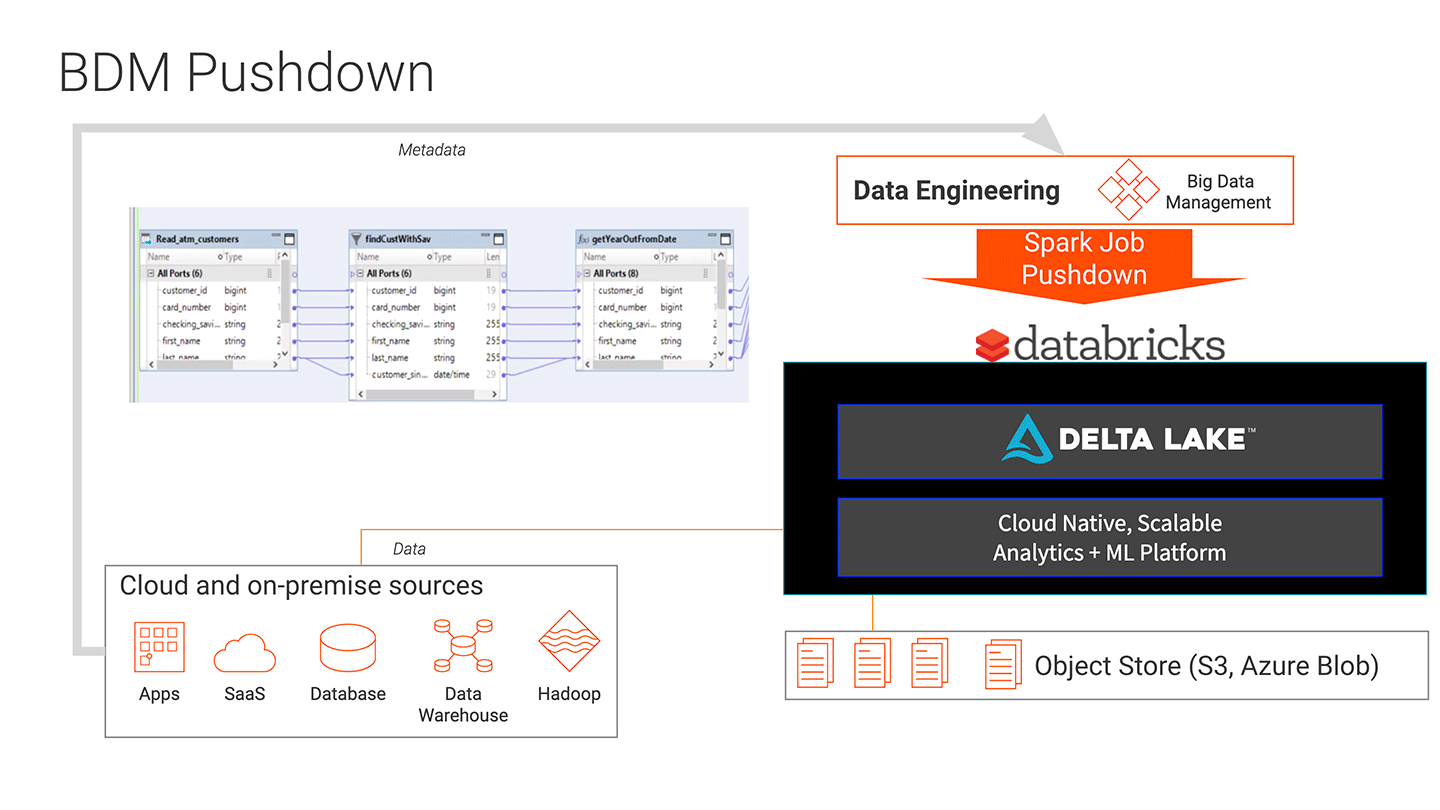
Informatica大数据管理(BDM)和Databricks统一分析平台的集成使得为大规模数据创建大容量数据管道变得更加容易。bob体育亚洲版bob体育客户端下载BDM的拖放界面降低了团队创建数据转换的门槛,不需要编写代码来创建数据管道。BDM易于维护和修改的管道可以利用Databricks的高容量可伸缩性,将工作下推进行处理。其结果是更快、更低成本地开发机器学习项目的大容量数据管道。管道的创建和部署增加了5倍,并且管道更容易维护和故障排除。
发现
为机器学习找到合适的数据集是很困难的。数据科学家浪费宝贵的时间为他们的模型寻找正确的数据集,以帮助解决关键问题。它们无法识别哪些数据集是完整的、格式正确的,以及哪些数据集已被正确地验证为正确的数据集。
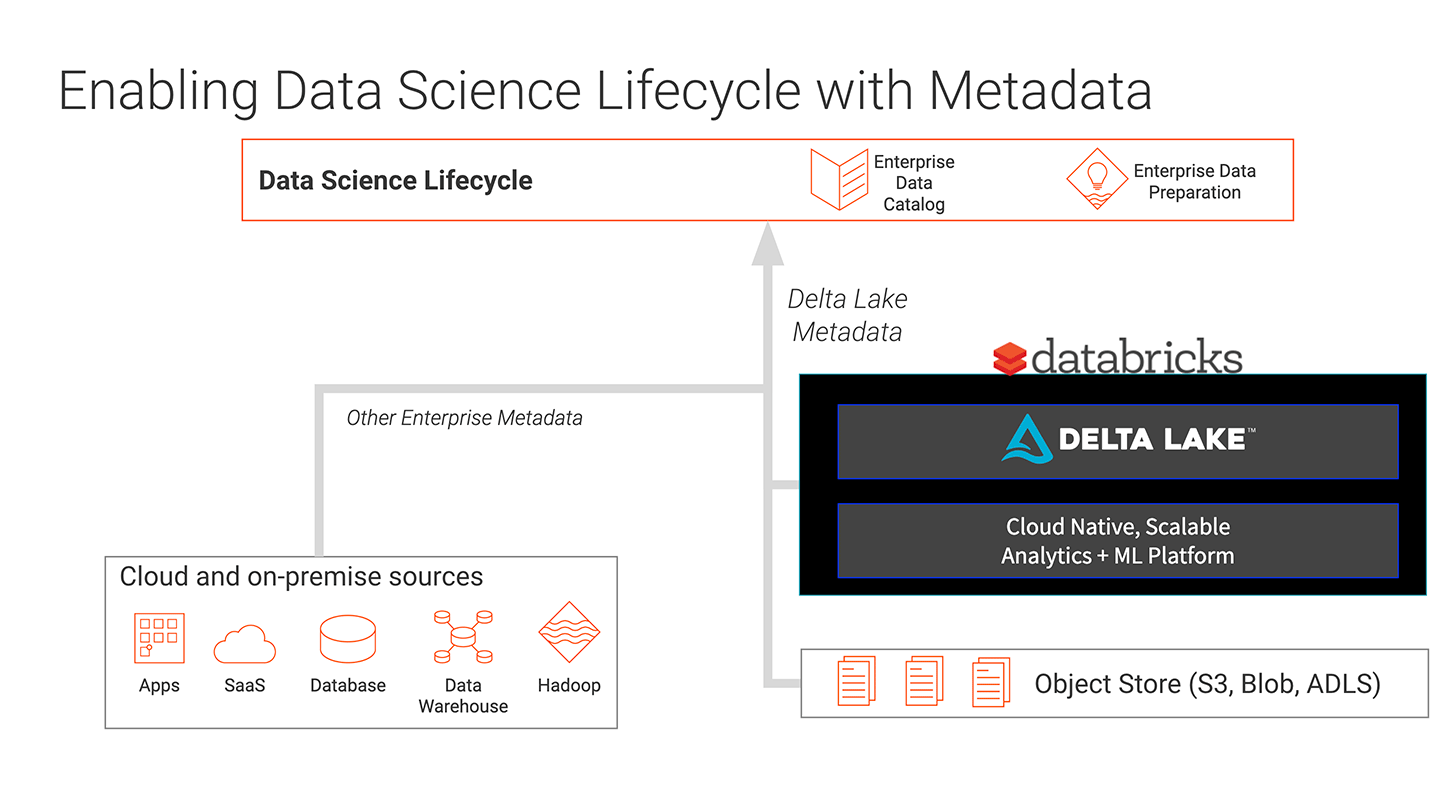
随着Informatica企业数据目录(EDC)与Databricks统一分析平台的集成,数据科学家现在可以为创建模型和执行分析找到正确的数据。bob体育亚洲版bob体育客户端下载Informatica的CLAIRE引擎使用人工智能和机器学习来自动发现数据,并为数据科学家提供智能建议。数据科学家可以快速地发现、验证和提供分析模型,大大缩短了实现价值的时间。Databricks可以以无限规模运行ML模型,以实现高影响力的洞察。EDC现在也可以跟踪Delta Lake中的数据,使其成为企业数据目录的一部分。
血统
追踪数据处理用于分析的沿袭几乎是不可能的。数据工程师和数据科学家无法提供任何血统证明来显示数据的来源。当数据被用于创建模型时,识别数据集、模型的哪个版本,甚至使用了哪个分析框架和库变得如此复杂,已经超出了我们手动跟踪的能力。
通过Informatica EDC的集成,以及Delta Lake和Databricks内部运行的MLflow,数据科学家可以从源头验证数据的沿系,跟踪Delta Lake中数据的确切版本,并跟踪和重现用于处理数据进行分析的模型、框架和库。这种跟踪数据科学决策的能力可以追溯到源头,为组织提供了一种强大的方法,可以根据需要审核和重现结果,以证明遵从性。
我们对这些集成以及它们将使组织成功的影响感到兴奋,通过使他们能够自动化数据管道并对这些管道提供更好的见解。欲了解更多信息,请注册本次网络研讨会https://www.informatica.com/about-us/webinars/reg/keys-to-building-end-to-end-intelligent-data-pipelines-for-ai-and-ml-projects_358895.html.