
开始使用个性化倾向得分





越来越多的消费者希望从事个性化的方式。无论是电子邮件推广产品补充最近的一次购买,在线横幅宣布出售产品经常浏览类别,或内容与表达利益,消费者有越来越多的选择,他们花自己的钱,更愿意与媒体承认他们的个人需求和喜好。
一个最近的调查麦肯锡突出,近四分之三的消费者现在预期个性化交互作为他们的购物体验的一部分。研究包含在这个调查强调,公司得到了这个站通过个性化的活动多产生40%的收入,使个性化的关键区别表现最好的零售。
尽管如此,许多零售商与个性化斗争。一个最近的调查Forrester发现只有30%的美国市场和26%的英国消费者认为零售商做好创建相关的经验。在一个独立调查3激进,仅有18%的受访者强烈地感觉到他们收到定制的建议,而52%从接收无关的通信,提供了表示失望。与消费者越来越多授权开关品牌和渠道,正确个性化已成为越来越多的企业的当务之急。
个性化是一个旅程
组织新的个性化,提供一对一的约会的想法似乎令人生畏。我们如何克服孤立的过程,可怜的数据管理和数据隐私担忧这种方法组装所需的数据吗?我们如何工艺内容和消息传递,感觉真正个性化的只有有限的营销资源吗?我们如何确保我们创造的内容是有效地针对个人发展的需求和喜好?
虽然大部分文献个性化突出前沿方法突出新颖性(但不总是这样有效性),实际情况是,个性化是一个旅程。在早期阶段,强调利用自身的数据隐私和客户信任更容易维护。相当标准的预测技术应用于带证明能力。随着价值证明和组织的发展不仅舒适与这些新技术,而且各种各样的方式他们可以集成到实践,然后使用更为复杂的方法。
倾向得分通常是一个个性化的第一步
个性化的旅程的第一个步骤是经常考试的销售数据洞察个人客户偏好。的过程称为倾向得分,公司可以评估客户的潜在接受要约或内容相关产品的一个子集。使用这些分数,营销人员可以确定哪些手头的消息应该提交给一个特定的客户。同样,这些分数可以用来识别领域的客户或多或少地接受一个特定形式的接触。
大多数倾向得分演习的起点是数值的计算属性(特征)从过去的交互。这些功能可能包括诸如客户的购买频率、比例的花与特定产品类别相关联,天自去年购买,和许多其他指标的历史数据。的历史时期后立即从这些特性计算然后检查等行为感兴趣的产品在一个特定类别的采购或优惠券的救赎。如果观察到的行为,一个标签1相关联的特性。如果不是,一个标签(0)分配。
使用标签的特性预测,数据科学家可以训练一个模型来估计概率利益的行为发生。应用这种训练模型特性计算最近的一段时间,营销人员可以估计的概率一个客户会从事这种行为在可预见的未来。
与众多优惠、促销、消息和其他内容在我们处理,大量的模型,预测不同行为、训练和应用于这个特性集。每个用户配置文件组成的分数为每个感兴趣的行为被编译,然后发布到下游系统使用的营销编排的各种活动。
砖提供关键的能力倾向得分
的倾向得分的声音,这不是没有挑战。在我们的谈话与零售商实施倾向得分,我们经常遇到同样的三个问题:
- 我们如何保持特性的100年代和1000年代有时我们用来训练我们倾向模型?
- 我们如何快速火车模型与新活动,营销团队希望追求吗?
- 我们如何迅速重新部署模型,成为客户模式漂移,得分管道?
在砖,我们的重点是让我们的客户通过一个分析平台构建与端到端需求的企业。bob体育客户端下载为此,我们纳入平台特性存储等功能,AutoML MLFlow,所有这些都可以用来应bob体育客户端下载对这些挑战是一个健壮的倾向评分过程的一部分。
特色商店
的砖特性的商店是一个集中的存储库,支持持久性,发现和分享功能跨各种模型的训练。捕获特性、血统和其他元数据捕获,这样数据科学家希望重用特性由其他人可能自信和轻松地这样做。标准安全模型和流程确保只允许用户可以使用这些特性,所以数据科学的流程管理,按照组织的数据访问政策。
AutoML
砖AutoML允许您快速生成模型利用行业最佳实践。作为一个玻璃盒解决方案,AutoML首先生成一个收藏的笔记本代表不同的模型变化符合您的场景。虽然迭代训练不同的模型来确定哪个效果最好与你的数据集,它允许您访问与每一个相关的笔记本电脑。对于许多数据科学团队,这些笔记本电脑成为一个可编辑的出发点为进一步探索模型变化,最终使他们到达他们自信训练模型能满足他们的目标。
MLFlow
MLFlow是一个开源的bob下载地址机器学习模型库,砖内的管理平台。bob体育客户端下载这个存储库允许数据科学团队跟踪和分析各种模型的迭代生成AutoML和定制的培训周期。它的工作流程管理功能允许组织迅速移动训练模型从开发到生产,这样训练模型可以更直接影响操作。
结合使用时砖特性存储、模型坚持MLFlow保留知识培训期间使用的特性。作为推理检索模型,这种模型相同的信息允许检索相关特性存储的功能,极大地简化了得分工作流和支持快速部署。
建立一个倾向得分工作流
结合使用这些特性,我们看到许多组织实施倾向得分的一部分由三部分组成的工作流。在第一部分中,数据工程师处理数据科学家定义特性相关的倾向得分锻炼和坚持这些特性存储。每日甚至实时特性工程过程被定义为计算值作为新的数据输入到最新的功能。
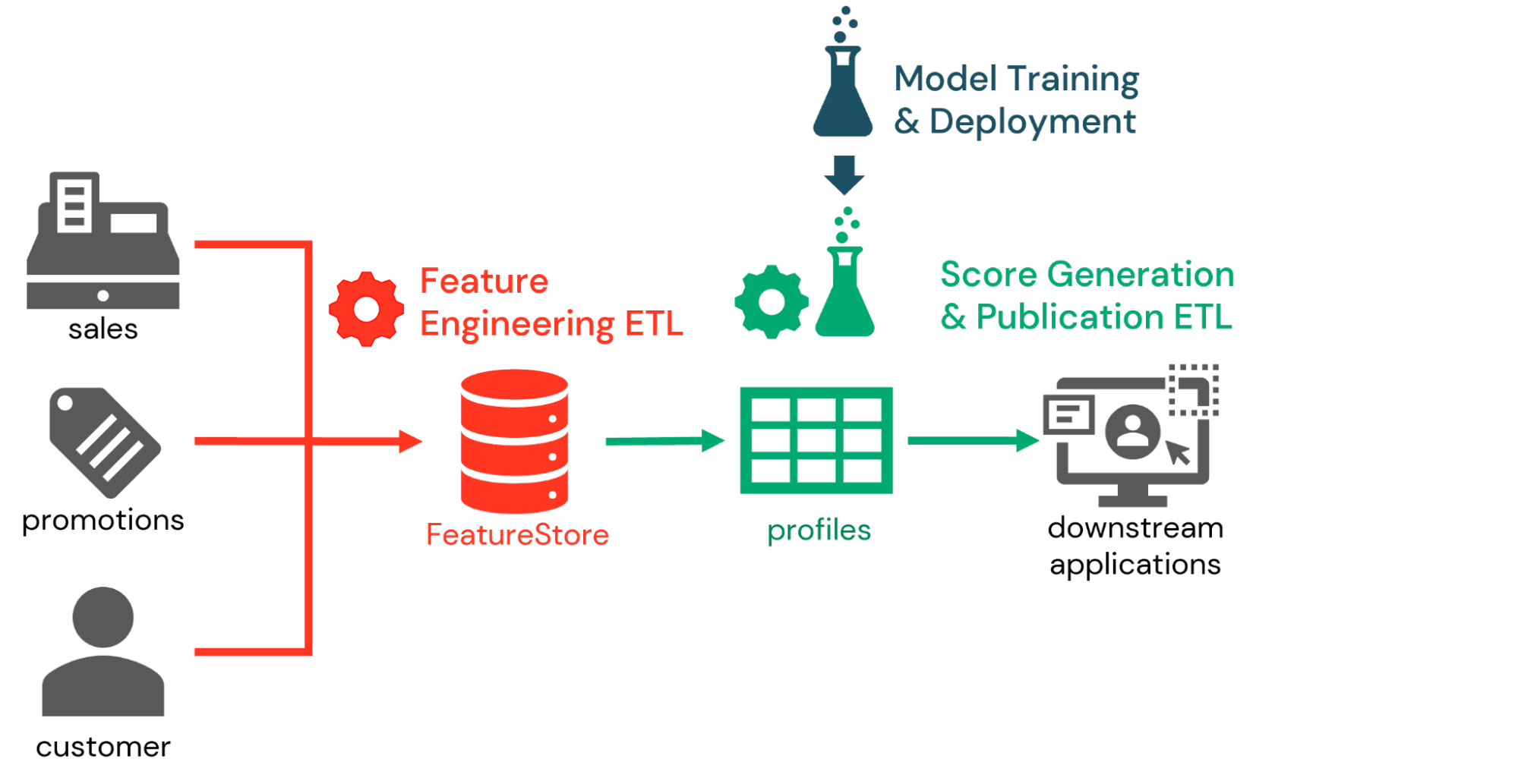
接下来,作为推理的工作流的一部分,提出了客户标识符之前训练模型,以生成倾向分数基于最新的特性。模型允许数据捕获功能存储信息工程师来检索这些特性和相对轻松地生成所需的分数。这些分数可能持续分析砖内的平台,但更通常被发布到下游营销系统。bob体育客户端下载
最后,在model-training工作流、数据科学家定期培训倾向评分模型来捕捉客户行为的变化。这些模型被保存到MLFLow、变更管理流程是用来评估模型和提高这些模型满足组织标准的生产现状。在推理工作流程的下一个迭代,每个模型的最新版本是检索生成客户分数。
验证这些功能如何一起工作,我们构造了一个端到端流程的倾向得分基于公开数据集。这个工作流演示了上述三条腿的工作流,并展示了如何使用关键的砖特性建立一个有效的倾向得分管道。
下载资产在这里,以此为起点构建你自己的个性化使用砖平台的基础。bob体育客户端下载