





扬如何建立CDC和多路复用数据管道与Databricks Delta活表
这个博客是由来自Uplift的Ruchira和Joydeep共同开发和撰写的,我们要感谢他们的贡献,并认为…
2022年5月5日 在bob体育客户端下载平台的博客
在Audantic,我们为单户住宅房地产的细分市场提供数据和分析解决方案。我们利用房地产数据构建机器学习模型,对客户进行排名、优化,并为客户提供收入情报,实时做出数据驱动的战略房地产投资决策。
我们利用各种数据集,包括房地产税和记录仪数据以及人口统计数据。构建我们的预测模型需要大量的数据集,其中许多数据集有数百列宽,甚至在考虑时间维度之前就包含了数亿条记录。
为了支持我们的数据驱动计划,我们将ETL、编排、利用AWS的ML、风流的各种服务“缝合”在一起,我们看到了一些成功,但很快就变成了一个过于复杂的系统,与新的解决方案相比,开发时间几乎是它的五倍。我们的团队捕获了高级指标,比较了我们以前的实现和当前的湖屋解决方案。从下面的表格中可以看到,我们花了几个月的时间来开发之前的解决方案,并且必须编写大约3倍的代码。此外,我们能够将管道的运行时间减少73%,并节省21%的运行成本。
| 以前的实现 | 新的湖屋解决方案 | 改进 | |
|---|---|---|---|
| 开发时间 | 6个月 | 25天 | 开发时间缩短86% |
| 代码行数 | ~ 6000 | ~ 2000 | 代码行数减少66% |
在这篇博客中,我将回顾我们以前的实现,并讨论我们当前的湖屋解决方案。我们的目的是向您展示我们的数据团队如何使用Databricks Lakehouse平台降低复杂性、提高生产力和提高敏捷性。bob体育客户端下载
我们之前的架构包括来自AWS的多个服务以及其他组件,以实现我们想要的功能,包括Python模块、Airflow、EMR、S3、Glue、Athena等。下面是一个简化的架构:
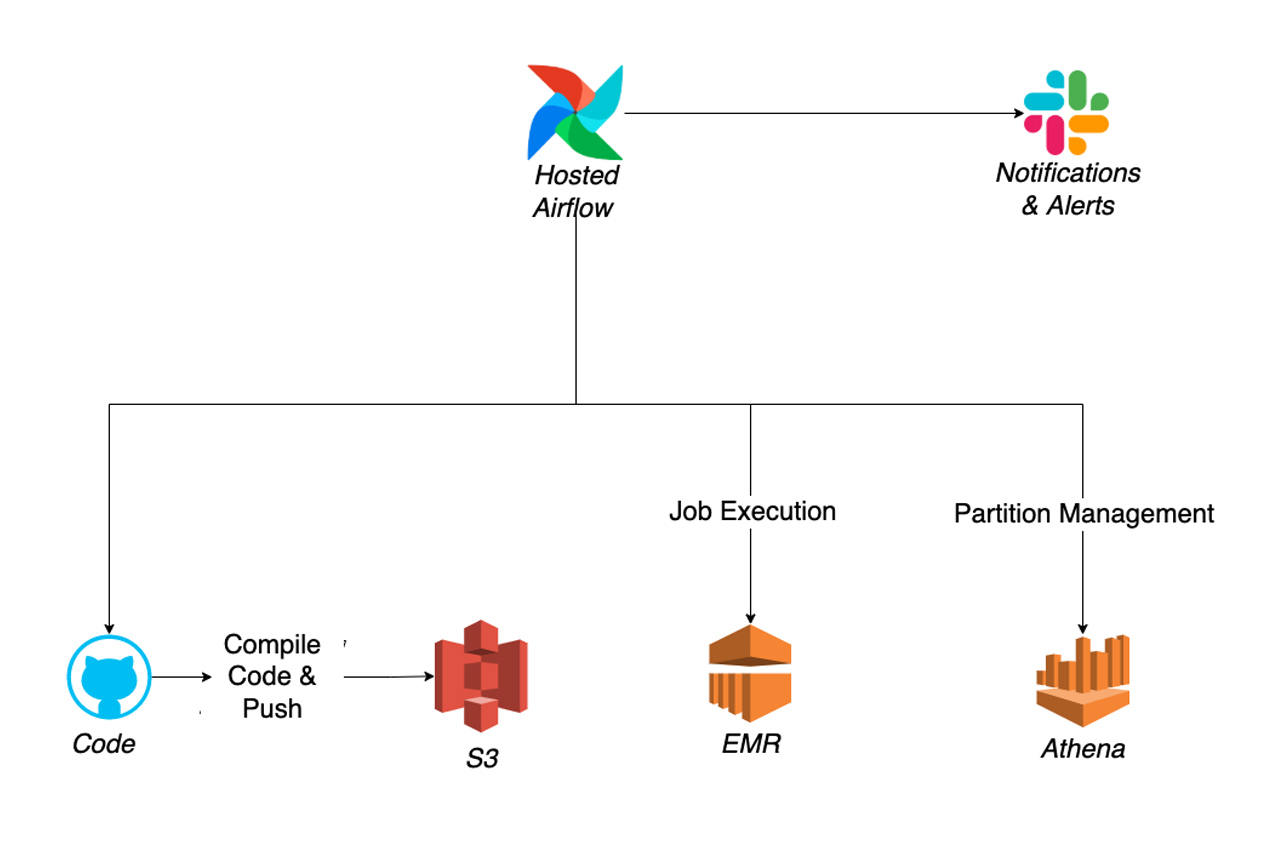
简单总结一下,过程如下:
由于我们之前实施的复杂性,我们面临许多挑战,阻碍了我们的前进和创新,包括:
我们之所以选择Databricks Lakehouse平台,是因为它易于管bob体育客户端下载理环境、集群和文件/数据,给我们留下了深刻的印象;Databricks笔记本中实时协作编辑的乐趣和有效性;以及平台的开放性和灵活性,而不牺牲可靠性和质量(例如,围绕他们的开源Delta bob体育客户端下载Lake格式构建,防止我们被锁定在专有格式或堆栈中)。我们将DLT视为又一步,以消除先前实现带来的更多挑战。我们的团队对获取存储在S3上的原始数据、支持模式演变、定义验证和监控数据质量的期望以及管理数据依赖关系的便利性和速度感到特别兴奋。
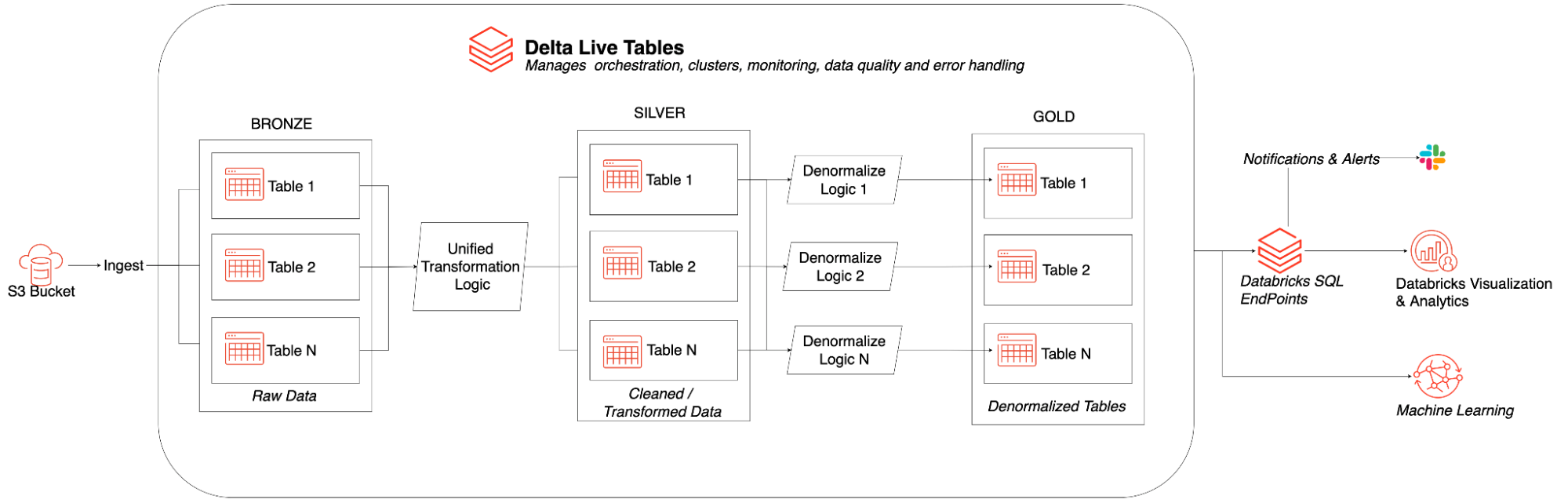
Delta Live Tables (DLT)可以轻松地构建和管理可靠的数据管道,从而在Delta Lake上交付高质量的数据。DLT将开发人员的工作效率提高了380%,帮助我们更快地交付用于ML和数据分析的高质量数据集。
通过使用Delta Live table,我们看到了许多好处,包括:
使用Databricks SQL,我们能够为分析人员提供一个SQL接口,以直接消费来自湖屋的数据,从而消除了将数据导出到其他工具进行分析消费的需要。它还通过Slack的成功和失败通知,为我们提供了对日常管道的增强监控。
Databricks Auto Loader可以自动摄取云存储上的文件到Delta Lake。它允许我们利用结构化流中内置的簿记和容错行为,同时保持接近批处理的成本。
我们在Databricks lakehouse平台上使用Delta Lake、Delta Live Tables、Databricks SQL和Aubob体育客户端下载to Loader构建了一个弹性的、可扩展的数据湖屋。我们能够通过消除维护气流实例、管理Spark参数调优和控制依赖关系管理的需要来显著降低操作开销。
此外,使用Databricks的技术可以自然而然地协同工作,而不是将许多不同的技术拼接在一起来覆盖我们所需的功能,从而大大简化了工作。操作开销和复杂性的减少极大地加速了我们的开发生命周期,并且已经开始改进我们的业务逻辑。总之,我们的小团队能够利用DLT在更短的时间内交付高价值的工作。
我们有即将到来的项目,将我们的机器学习模型转换到湖边小屋,并改进我们复杂的数据科学过程,比如实体解析。我们很高兴能让我们组织中的其他团队了解和访问新的湖屋中可用的数据。Databricks的Feature Store、AutoML、Databricks SQL、Unity Catalog等产品将使Audantic继续加速这一转变。
查看我们的一些资源,开始使用Delta Live Table

