




宣布Photon公开预览:Databricks Lakehouse平台上的下一代查询引擎bob体育客户端下载
今天,我们激动地宣布Photon的公开预览版。Photon是一个用c++开发的本地矢量化引擎。
2021年6月17日 在bob体育客户端下载平台的博客
今天,我们很高兴地宣布光子公开预览。Photon是用c++开发的原生向量化引擎,用于显著提高查询性能。所有你要做的就是从Photon中受益。Photon将无缝地协调工作和资源,透明地加速SQL和Spark查询的部分。不需要调优或用户干预。
虽然新引擎被设计为最终加速所有工作负载,但在预览期间,Photon专注于更快地运行SQL工作负载,同时降低每个工作负载的总成本。有两种方式你可以从Photon受益:
在这篇博客中,我们将讨论构建Photon的动机,解释Photon的工作原理,以及如何从Databricks SQL和Databricks Data Science & Data Engineering上的传统集群中监控Photon中的查询执行。
有人可能会问,为什么要构建一个新的查询引擎?有人说一幅柱状图胜过千言万语,所以让我们用数据来讲述故事吧。
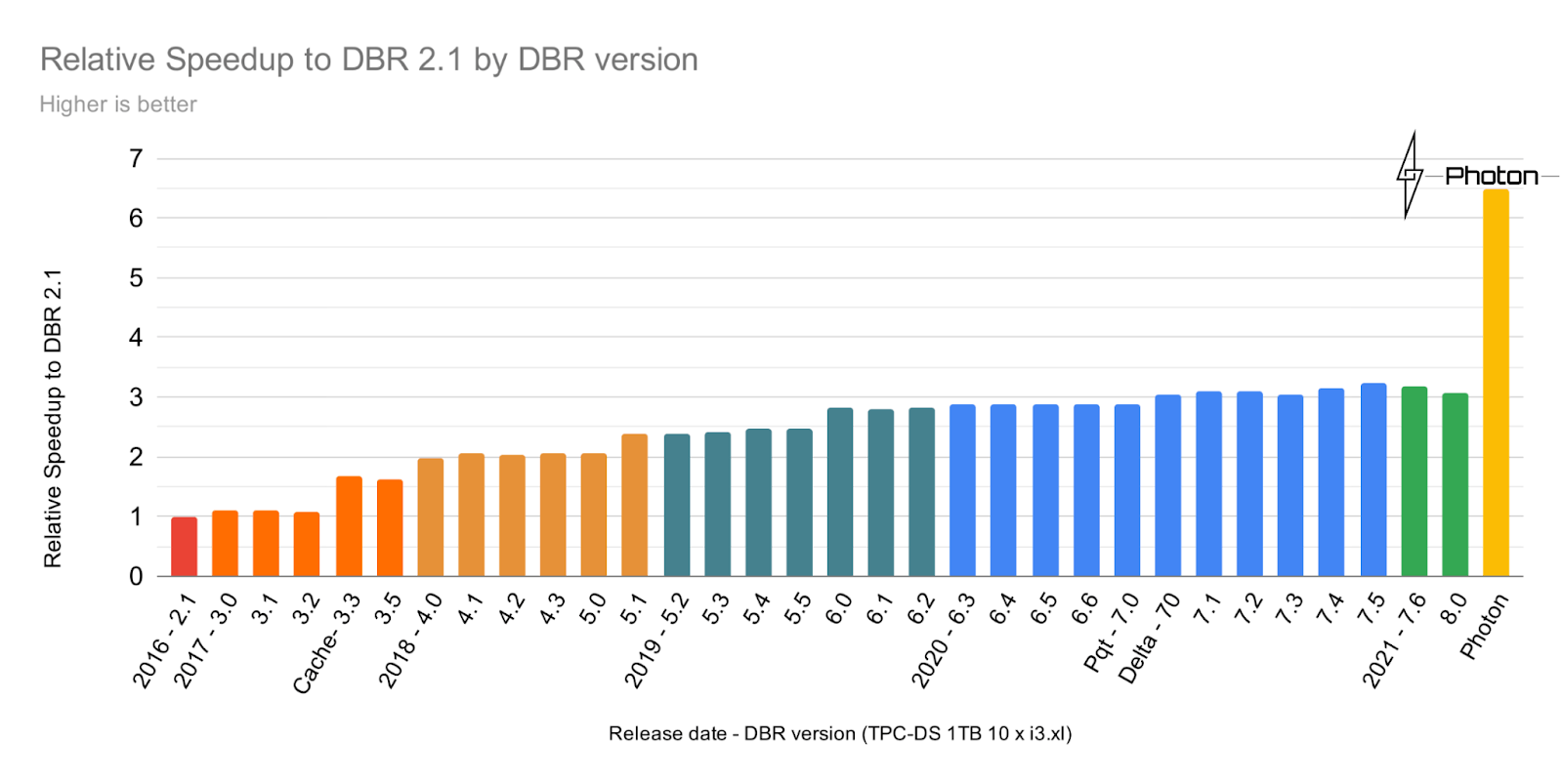
从这张使用TPC-DS基准测试(比例因子1TB)的Databricks运行时性能图表中可以看到,这些年来性能稳步提高。然而,随着Photon的引入,我们看到了查询性能的巨大飞跃——Photon比Databricks Runtime 8.0快了2倍。这就是为什么我们对Photon的潜力感到非常兴奋,我们才刚刚开始——Photon路线图包含了更大的覆盖范围和更多优化的计划。
早期的私人预览客户已经观察到使用Photon在SQL工作负载上的平均提速2-4倍,例如:
虽然Photon是用c++编写的,但它直接集成在Databricks Runtime和Spark中。这意味着使用Photon不需要修改代码。让我带你快速了解一个“查询的生命周期”,以帮助你理解Photon的插入位置。
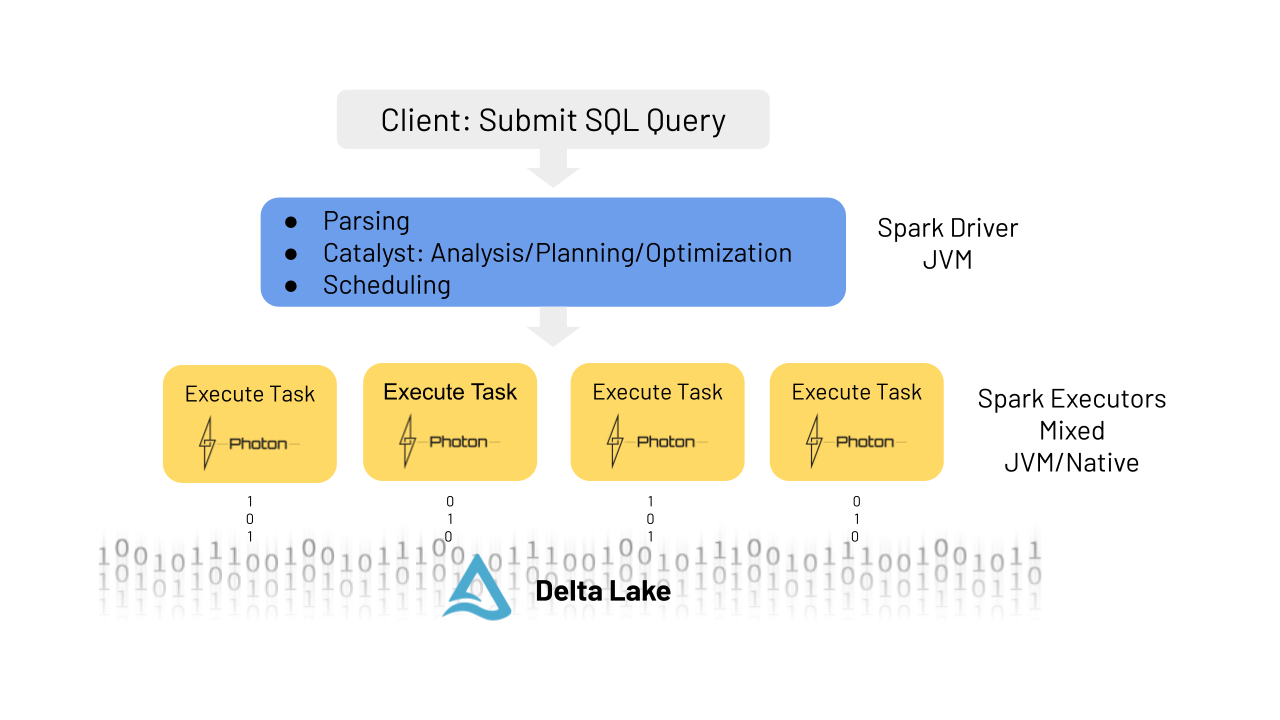
当客户端向Spark驱动程序提交给定的查询或命令时,该查询或命令将被解析催化剂优化器做分析,计划和优化,就像它会没有光子涉及。唯一不同的是,在Photon中,运行时引擎会传递物理计划,并决定哪些部分可以在Photon中运行。Photon的计划可能会做一些小的修改,例如,将排序合并连接更改为散列连接,但计划的整体结构,包括连接顺序,将保持不变。由于Photon还不支持Spark的所有功能,单个查询可以部分在Photon中运行,部分在Spark中运行。这种混合执行模型对用户是完全透明的。
然后,查询计划被分解为分布式执行的原子单元,称为任务,这些任务在工作节点上的线程中运行,这些线程对数据的特定分区进行操作。光子引擎就是在这个层次上工作的。你可以把它想象成用原生引擎实现取代Spark的整个阶段代码原。Photon库加载到JVM中,Spark和Photon通过JNI,将数据指针传递到堆外内存。Photon还集成了Spark的内存管理器,用于在混合计划中协调溢出。Spark和Photon都被配置为使用堆外内存并在内存压力下进行协调。
随着公开预览版的发布,Photon支持许多(但不是全部)数据类型、操作符和表达式。请参阅光子概述详见文档。
考虑到目前并不是所有的工作负载和操作符都被支持,你可能想知道如何选择可以从Photon中受益的工作负载,以及如何在执行计划中检测Photon的存在。简而言之,Photon执行是自底向上的——它从表扫描操作符开始,并继续向上DAG(有向无环图),直到它遇到一个不受支持的操作。在这一点上,执行离开Photon,其余的操作将在没有Photon的情况下运行。
一般来说,Task Time在Photon中的百分比越大,Photon的性能收益就越大。
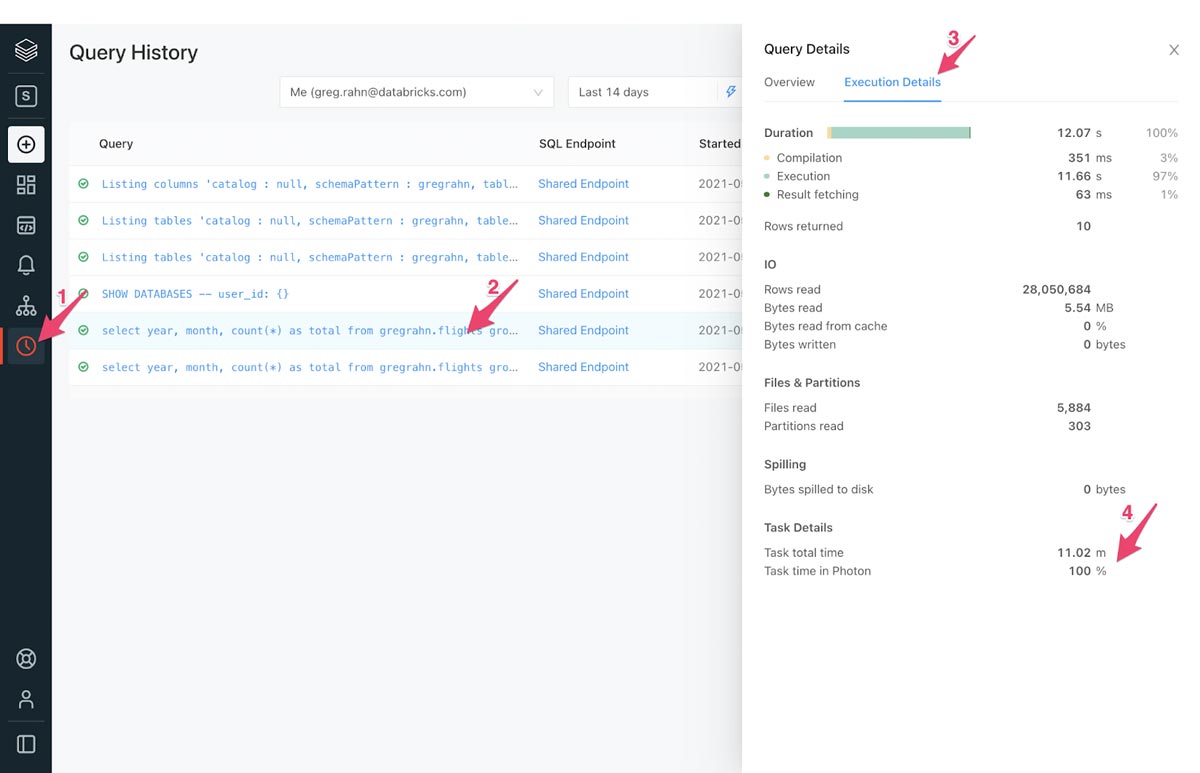
如果你在Databricks集群上使用Photon,你可以在Spark UI中查看Photon动作。下面的截图显示了查询细节DAG。在DAG中有两个光子的迹象。首先,Photon操作符以Photon开头,例如PhotonGroupingAgg。其次,在DAG中,Photon操作符和阶段是桃红色的,而非Photon操作符和阶段是蓝色的。
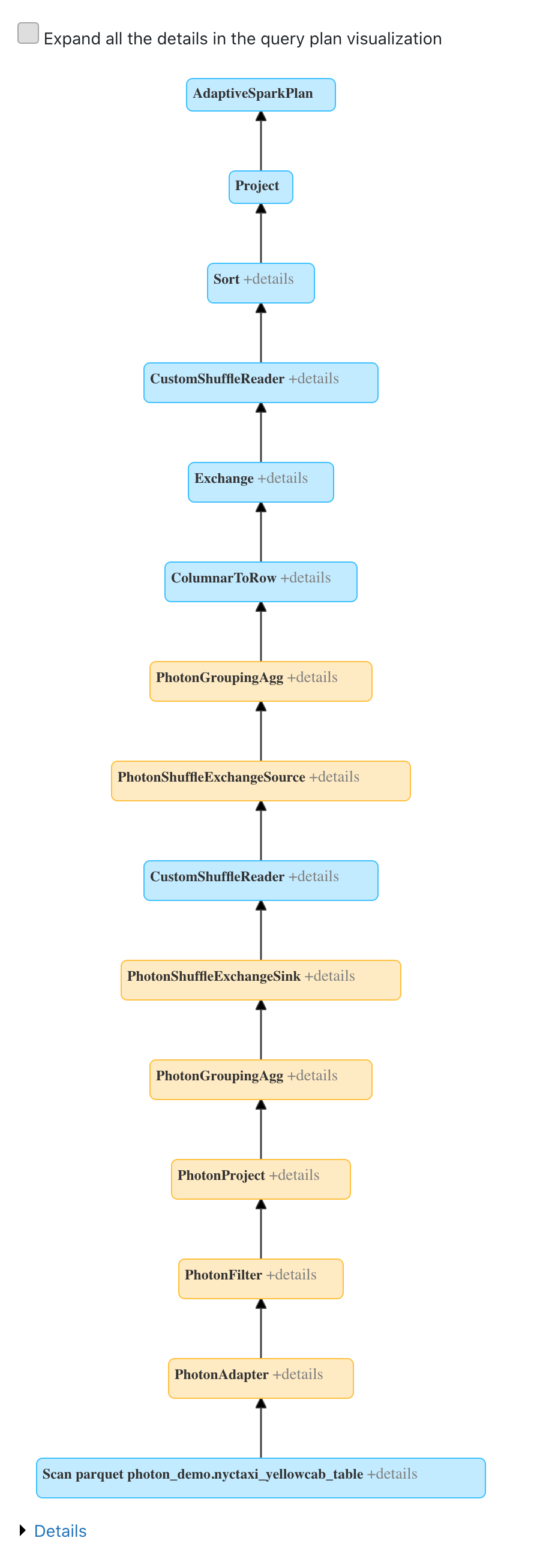
如上所述,有两种方法可以使用Photon:
创建了启用photon的SQL端点或集群后,可以尝试对NYC Taxi数据集从Databricks SQL编辑器或笔记本。我们已经预装了一段摘录,并将其作为我们的一部分砖的数据集.
首先,用下面的SQL代码段创建一个指向现有数据的新表:
创建如果数据库不存在photon_demo;创建表格photon_demo.nyctaxi_yellowcab_table使用δ选项(路径“/ databricks-datasets / nyctaxi /表/ nyctaxi_yellow /”);尝试这个查询,享受光子的速度!
选择vendor_id,总和(trip_distance)作为SumTripDistance,AVG(trip_distance)作为AvgTripDistance从photon_demo.nyctaxi_yellowcab_table在哪里passenger_count在(1,2,4)集团通过vendor_id订单通过vendor_id;我们使用Photon和常规Databricks Runtime在预热的AWS集群上测量了上述查询的响应时间,该集群有2个i3.2xlarge执行器和一个i3.2xlarge驱动程序。以下是结果。
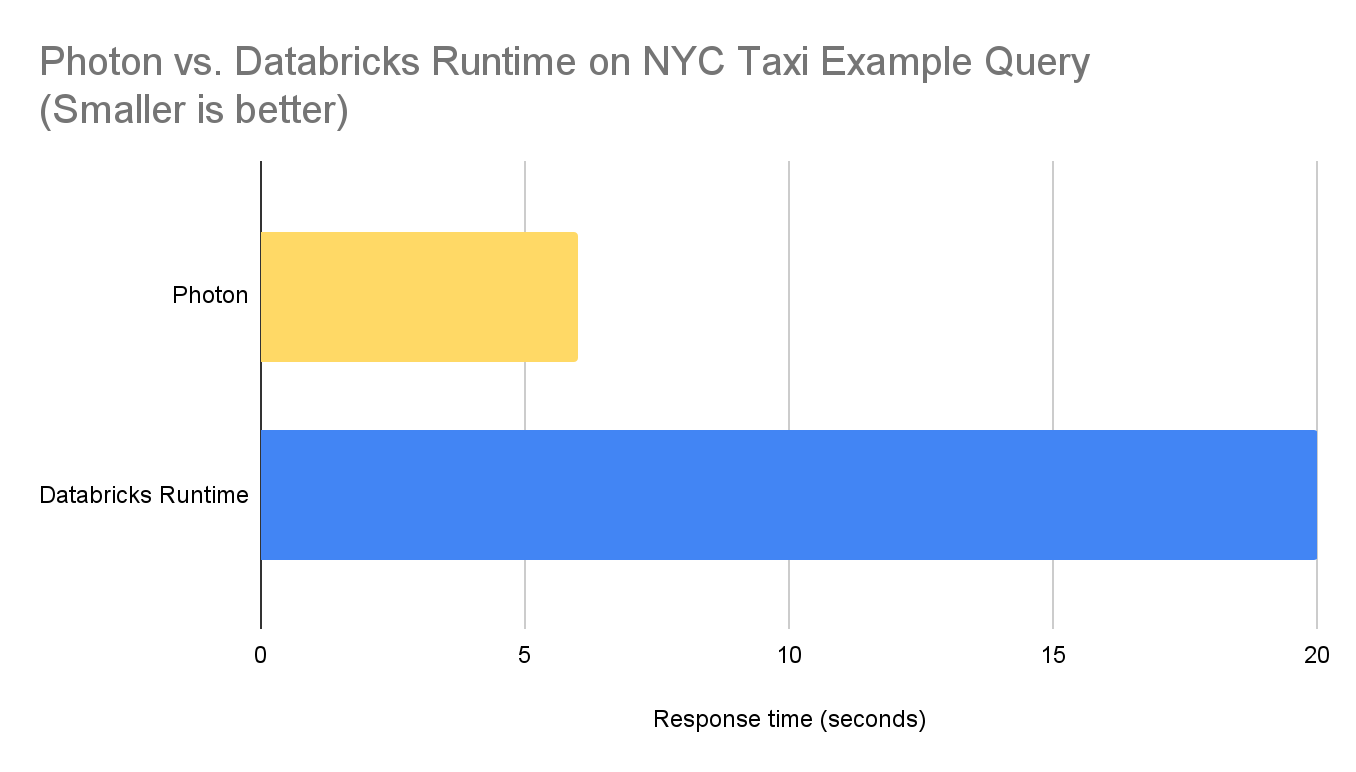
如果你想了解更多关于Photon的BOB低频彩知识,你也可以观看我们的数据和AI峰会:根本性的速度SQL查询光子在引擎盖下.感谢您的阅读,我们期待您的反馈!