
MLflow 1.12特性扩展PyTorch集成


2020年11月13日 在工程的博客
MLflow 1.12特性包括扩展的PyTorch集成、SHAP模型可解释性、MLflow实体的自记录支持的模型风味,以及许多UI和文档改进。现可于PyPI和文档在线,您可以安装此新版本PIP install mlflow==1.12.0如在MLflow快速入门指南.
在这篇博客中,我们简要地解释了关键特性,特别是扩展的PyTorch集成,以及如何使用它们。有关附加功能、更改和错误修复的全面列表,请阅读MLflow 1.12更新日志.
支持PyTorch自动记录,TorchScript模型和TorchServing
在PyTorch开发者日, Facebook的AI和PyTorch工程团队,与Databricks的MLflow团队和社区合作,宣布了一项扩展PyTorch和MLflow集成作为MLflow 1.12版本的一部分。这次联合工程投资和与MLflow的集成为PyTorch开发人员提供了一个“从开发到生产的端到端PyTorch平台”。bob体育客户端下载我们简要介绍集成的三个方面:
- PyTorch模型的自定义
- 支持TorchScript模型
- 将PyTorch模型部署到TorchServe上
自建PyTorch pl.LightningModule模型
作为这个版本中引入的通用自记录功能的一部分(请参阅下面的自记录部分),您可以自动记录(并跟踪)PyTorch Lightning模型中的参数和指标。
除了用于记录和跟踪的定制实体之外,PyTorch autolog跟踪功能将记录模型的优化器名称和学习率;训练损失、验证损失、准确性等指标;以及作为工件和检查点的模型。对于早期停止,模型检查点,早期停止参数和指标也被记录下来。
将PyTorch模型转换为TorchScript
TorchScript是一种从PyTorch代码中创建可序列化和可优化模型的方法。因此,任何mlflow记录的PyTorch模型都可以转换为TorchScript,保存并加载(或部署到)一个高性能的独立进程,其中没有Python依赖。这个过程包括以下步骤:
- 创建一个MLflow Python模型
- 使用JIT编译模型并转换为TorchScript模型
- 记录或保存TorchScript模型
- 加载或部署TorchScript模型
#你的PyTorch nn。Module或pl.LightningModule模型= Net()Scripted_model = torch.jit.script(模型)...mlflow.pytorch.log_model (scripted_model“scripted_model”)Model_uri = mlflow.get_artifact_uri(“scripted_model”)load_model = mlflow.pytorch.load_model(model_uri)...为简洁起见,我们在这里没有包括所有代码,但是您可以检查示例代码IrisClassification而且MNIST-在GitHubmlflow /例子/ pytorch / torchscript目录.
使用脚本(拟合或日志)模型可以做的一件事是使用mflow fluent和mlflow.pytorchapi来访问模型及其属性,如GitHub示例中所示。你可以用脚本模型做的另一件事是使用TorchServer MLflow Plugin将它部署到TorchServe服务器上。
使用TorchServe MLflow Plugin部署PyTorch模型
TorchServe为PyTorch模型提供了一个灵活、简单的工具。通过TorchServe MLflow部署插件,您可以部署任何mlflow记录和安装的PyTorch模型。扩展的集成完成了PyTorch MLOps生命周期-从开发,跟踪和保存到部署和服务PyTorch模型。

为了演示,有两个PyTorch示例—bertnewsclassification和MNIST列举如何使用TorchServe MLflow部署插件将PyTorch保存的模型部署到现有的TorcheServe服务器的步骤。任何mlflow记录和安装的PyTorch模型都可以轻松部署mlflow部署命令。例如:
Mlflow部署创建-t torchserve -m models:/my_pytorch_model/production -n my_pytorch_model
一旦部署完成,您就可以轻松地使用mlflow部署预测命令进行推断。
Mlflow部署预测——命名my_pytorch_model——目标torchserve——输入路径样本。输出路径output.json。
SHAP API提供模型解释性
随着越来越多的机器学习模型被部署到生产中,作为提供提示性提示或做出决定性预测的业务应用程序的一部分,机器学习工程师有义务解释模型是如何训练的,以及哪些特征对其输出有贡献。回答这些问题的一个常用技巧是世鹏科技电子(SHapley加法解释),一种解释任何机器学习模型输出的理论方法。
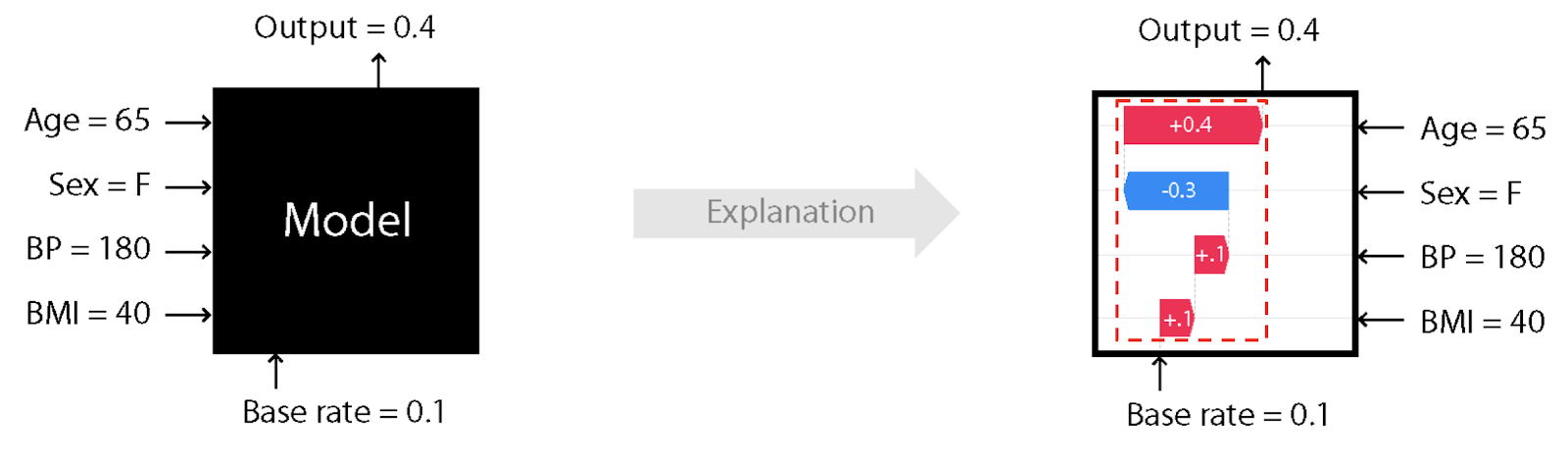
为此,本版本包括一个mlflow。世鹏科技电子模块用一种方法mlflow.shap.log_explanation ()生成可记录日志的说明性图形
作为模型工件,并在UI中进行检查。
进口mlflow#准备培训数据数据集= load_boston()X = pd.DataFrame(dataset.data[:50,:8= dataset.feature_names[],列:8])Y = dataset.target[:50]#训练一个模型模型=线性回归()模型。fit (X, y)#记录解释与mlflow.start_run ()作为运行:mlflow.shap.log_explanation(模型。预测,X)...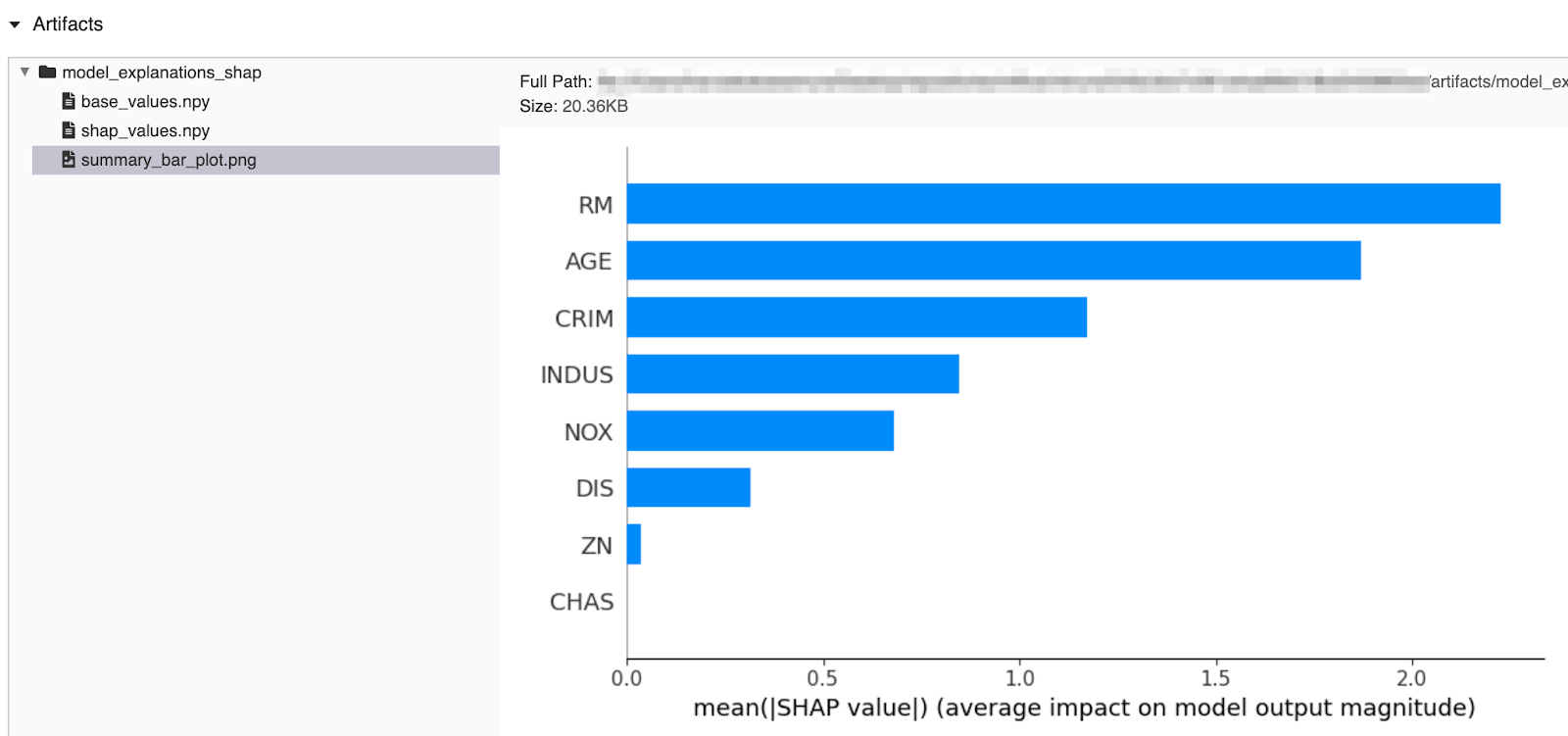
方法中查看示例代码文档页面并在MLflow GitHub中尝试其他带有SHAP解释的模型示例mlflow /例子/世鹏科技电子目录中。
自记录简化了跟踪实验
的mlflow.autolog ()method是一个通用的跟踪API,它通过一次调用自动记录所有相关的模型实体(参数、度量、模型和模型摘要等工件)来简化训练代码,而不需要显式地调用每个单独的方法来记录各自的模型实体。
作为一种通用的单一方法,它在底层检测使用了哪一种受支持的自记录模型类型(在我们的示例中是scikit-learn),并跟踪其所有各自的实体以记录日志。运行后,在MLflow UI中查看时,可以检查所有自动记录的实体。
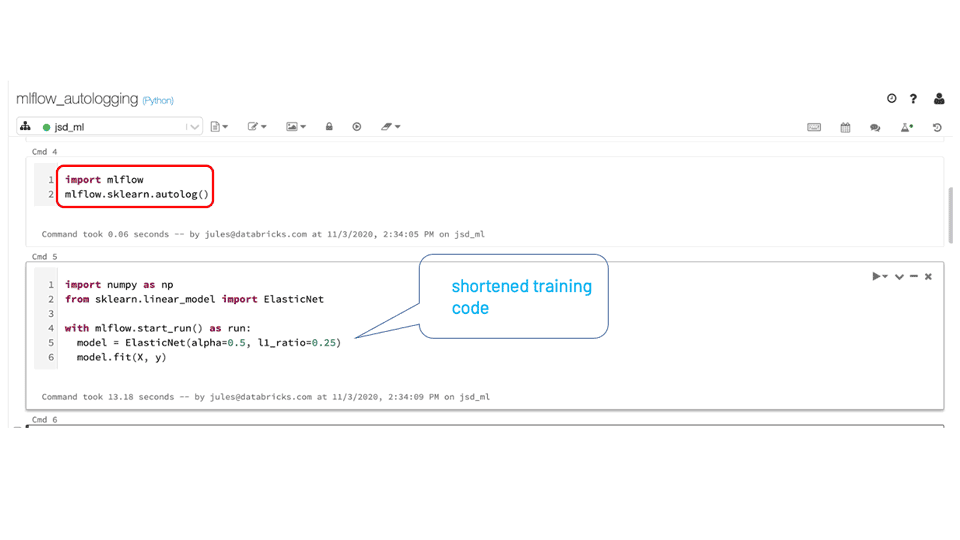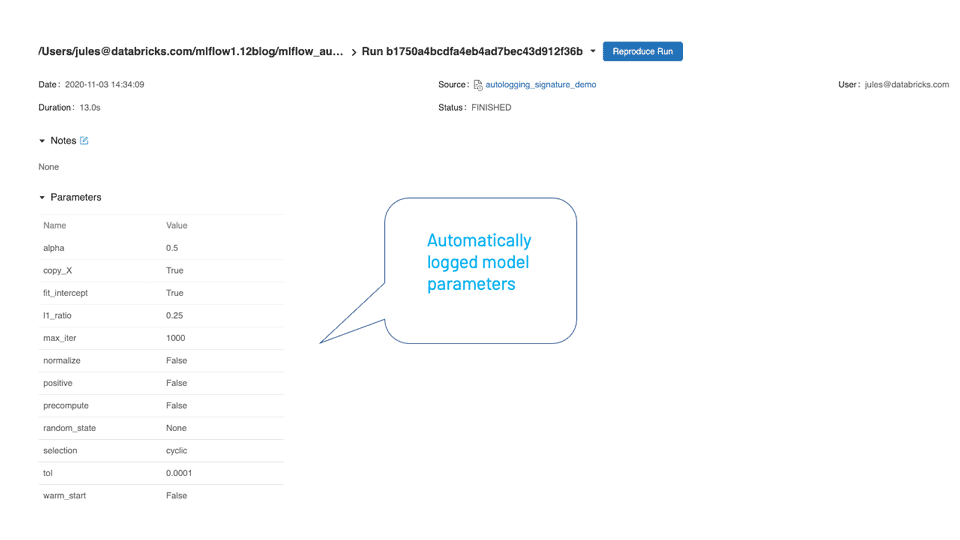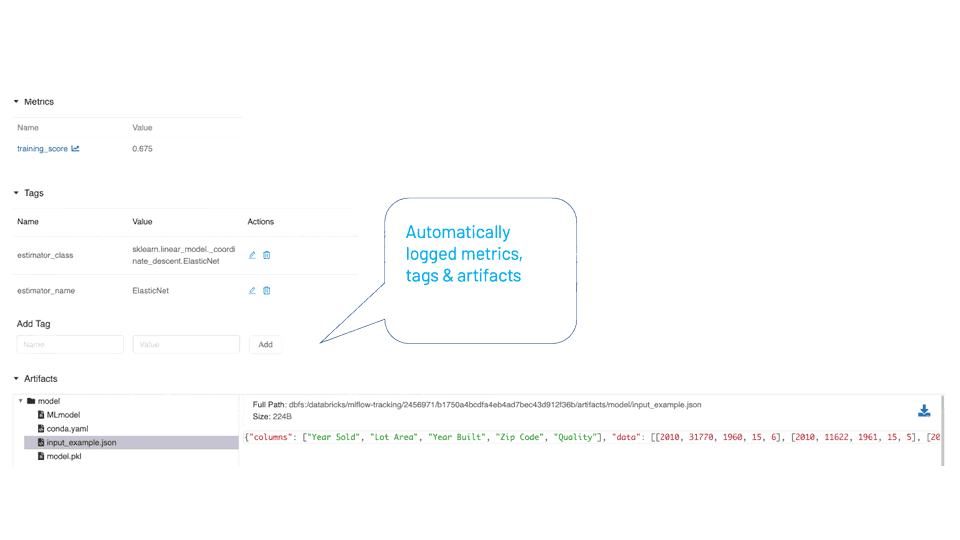
接下来是什么
BOB低频彩了解更多关于PyTorch集成的信息数据+人工智能欧洲峰会下周,主题演讲来自Facebook AI工程总监林乔和一届就上了使用PyTorch和MLflow的可复制AI来自Facebook的Geeta Chauhan。
请继续关注更多PyTorch和MLflow的详细博客。现在你可以:
- 读MLflow和PyTorch——尖端AI遇到MLOps的地方
- 签出PyTorch和MLFlowmlflow / / pytorch /例子
- 检查SHAP GitHubmlflow / /世鹏科技电子/例子
PIP install mlflow==1.12.0试一试吧。
社会信用
我们要感谢以下贡献者对MLflow 1.12版的更新、文档更改和贡献。我们特别要感谢Facebook AI和PyTorch工程团队对PyTorch扩展集成的贡献,以及MLflow社区的所有贡献者:
Andy Chow, Andrea Kress, Andrew Nitu, Ankit Mathur, Apurva Koti, Arjun DCunha, Avesh Singh, Axel Vivien, Corey Zumar, Fabian Höring, Geeta Chauhan, Harutaka Kawamura, Jean-Denis Lesage, Joseph Berry, Jules S. Damji, Juntai Zheng, Lorenz Walthert, Poruri Sai Rahul, Mark Andersen, Matei Zaharia, Martynov Maxim, Olivier Bondu, Sean Naren, Shrinath Suresh, Siddharth Murching, Sue Ann Hong, Tomas Nykodym, Yitao Li, zhiidong Qu, @abawchen, @cafeal, @bramrodenburg, @danielvdende, @edgan8, @emptalk,@ghisvail, @jgc128 @karthik-77, @kzm4269, @magnus-m, @sbrugman, @simonhessner, @shivp950, @willzhan-db