
为什么以云为中心的数据湖是EDW的未来



2020年11月3日 在产品
在这两篇博客中的第一篇中,我们想谈谈为什么一个组织可能想要在他们的数据分析管道中考虑lakehouse架构(基于Delta Lake),而不是从本地或云中提升和转移他们的企业数据仓库(EDW)的标准模式。我们将在接下来的一篇博文中详细介绍如何进行这样的转变。
企业数据仓库
企业数据仓库在组织中经受住了时间的考验。他们提供了巨大的商业价值。企业需要数据驱动,并希望从数据中收集见解,而edw已被证明是做到这一点的得力助手。
然而,随着时间的推移,在EDW体系结构中发现了几个问题。从广义上讲,这些问题可以归结为大数据的四个特征,通常被称为“4v”,即容量、速度、多样性和准确性,这是遗留架构的问题。以下原因进一步说明了基于EDW架构的局限性:
- 遗留的、不可扩展的体系结构:随着时间的推移,架构师和工程师已经熟练掌握了性能数据库技术,并将数据仓库作为完整的数据策略。迫于现有工具的创新压力,数据库已被用于解决更复杂的解决方案,而这并不是它最初的意图。这导致反模式从本地扩散到云中。通常,当迁移这些工作负载时,云计算成本会飙升——从基础设施到管理和实现所需的资源,再到获得价值所需的时间。这让所有人都质疑这种“云”战略。
- 数据种类:只管理结构化数据的好日子已经过去了。如今,数据管理策略必须考虑半结构化文本、JSON和XML文档,以及音频、视频和二进制文件等非结构化数据。在决定云技术时,必须考虑能够处理所有类型数据的平台,而不仅仅是提供每月报告的结构化数据。bob体育客户端下载
- 数据速度:数据仓库提供了一种范式转换,我们可以让ETL处理在一夜之间发生,我们的业务聚合将在这里进行计算,业务合作伙伴将在早上第一件事获得他们的新数据。bob体育外网下载企业的要求和需求是迅速和不断增加的。在这样的场景中,遵从每日负载将成为一种执行风险。有一个随时更新的数据存储用于分析、人工智能和决策是非常必要的。
- 数据科学:起初,在过去孤立的数据生态系统中,组织是二等公民,现在他们发现,他们需要为数据科学家铺平道路,让他们做他们最擅长的事情。数据科学家需要访问尽可能多的数据。训练模型的一个重要部分是从原始数据中选择最具预测性的字段,这些字段并不总是出现在数据仓库中。如果不首先分析数据,数据科学家将无法确定将哪些数据包含在仓库中。
- 数据的扩散:考虑到今天业务操作的变化速度,我们需要对数据模型进行更多的更改,而更改数据仓库的成本可能会很高。另外,数据集市、提取表和桌面数据库的使用破坏了现代企业中的数据生态系统,导致了业务视图的破裂。此外,该模型需要6个月或更长时间的容量规划。在云计算中,这一设计原则意味着巨大的成本。
- 每栏成本:在传统的EDW世界中,在模式中生成一个新列所需的协调和规划是非常重要的。这会影响两件事——成本和价值的损失时间(即当列不可用时做出的决定)。组织应该考虑云数据湖的灵活性,它可以显著降低成本(和时间),从而更快地获得预期的结果。
- ETL vs ELT:在on-prem的世界里,你要么花钱让ETL服务器在一天的大部分时间里闲置;或者你必须小心地根据数据仓库中的BI工作负载来调度你的ELT工作。在云中,您可以选择—遵循相同的趋势(即在数据仓库中执行ELT和BI)或切换到ETL。在云中使用ETL时,您只需要在转换运行时为基础设施付费。而且,执行这些转换的代价应该低得多。这种工作负载的分割还允许高效的计算,以支持高吞吐量和流数据。总的来说,云中的ETL可以为组织提供巨大的成本和性能优势。

图1:EDW世界中的典型流程及其局限性
因此,实际上,由于这些挑战,EDW社区的需求变得更加清晰:
- 必须摄取所有数据,即结构化,半结构化和非结构化
- 必须以所有速度摄取所有数据,即每月、每周、每天、每小时,甚至每秒钟(即流),同时演进模式并防止昂贵、耗时的修改
- 必须摄取所有数据,这里我们指的是整个数据卷
- 必须可靠地摄取所有这些数据-上游失败的作业不应该破坏下游的数据
- 仅仅为BI提供这些数据是不够的。该组织希望利用所有这些数据来在竞争中获得优势并具有预测性,不仅要问"发生了什么"还要问"将会发生什么"
- 必须智能地分割计算,以实现最优成本的结果,而不是为“以防万一”的情况而过度配置。
- 是否同时消除了数据副本、复制问题、版本问题以及可能的治理问题
简单地说,架构必须支持所有速度、种类和数据量,以最佳成本实现商业智能和生产级数据科学。
现在,如果我们开始谈论云数据湖架构,它为组织带来的一件主要事情是极其便宜的存储。当你想到Azure Blob或Azure Data Lake Gen2以及AWS S3时,你可以花几美元存储TB级的数据。这使组织免于受制于磁盘存储成本是其数倍的分析设备。但是,这只有在组织利用计算与存储分离的优势时才会发生。我们的意思是,数据必须与计算基础设施分开保存。从名义上讲,在AWS上,您的数据将驻留在S3(或Azure上的ADLS Gen2/Blob)上,而您的计算将在需要时自动启动。
考虑到这一点,让我们来看看现代云数据湖体系结构
- 您的所有数据源都可以落在首选云上的这些廉价对象存储中,无论它是结构化、非结构化还是半结构化
- 现在,您可以在存储层的原始数据之上构建一个精心策划的数据湖
- 并且,在这个精心策划的数据湖之上,您可以构建探索性数据科学、生产ML以及SQL/BI
对于这个精心策划的数据湖,我们希望关注组织在构建这一层时必须考虑的问题,以避免过去数据湖的陷阱。其中有一种强烈的“垃圾进垃圾出”的观念。在过去的数据湖中,这种特性的一个关键原因是数据的可靠性。数据可能会使用错误的模式,可能会被损坏,等等,然后它就会被摄取到数据湖中。直到后来,当这些数据被查询时,问题才真正出现。所以可靠性是需要考虑的主要要求。
当然,另一个重要的因素是性能。我们可以使用很多技巧来使数据可靠,但是如果一个简单的查询需要很长时间才能返回,那就不好了。
另一个重要的问题是,作为一个组织,您可能会开始考虑在管理级别上的数据。你可能有一个原始层,一个细化层和一个BI层。通常,原始层是传入的数据,细化层是强加模式强制和可靠性检查的要求,BI层有干净的数据和聚合,可以为执行人员构建仪表板。我们还需要考虑以一种简单的方式在这些层之间移动的流程。
此外,我们还希望保持计算和存储的分离——我们这样做的原因是,在云计算中,成本会给组织带来沉重的负担。你想把它存储在对象存储中给你一个廉价的持久层。只在您需要的时间内将您的计算机与数据连接起来,然后将其关闭。例如,启动一个非常大的集群,对您的数据执行ETL几分钟,并在流程完成后关闭它。在查询方面,您可以将几十年前的所有数据保存在S3上,并在只需要查询最近几年的情况下调出一个小集群。这种灵活性是至关重要的。这实际上意味着我们所说的可靠性和性能必须是数据存储方式的固有属性.
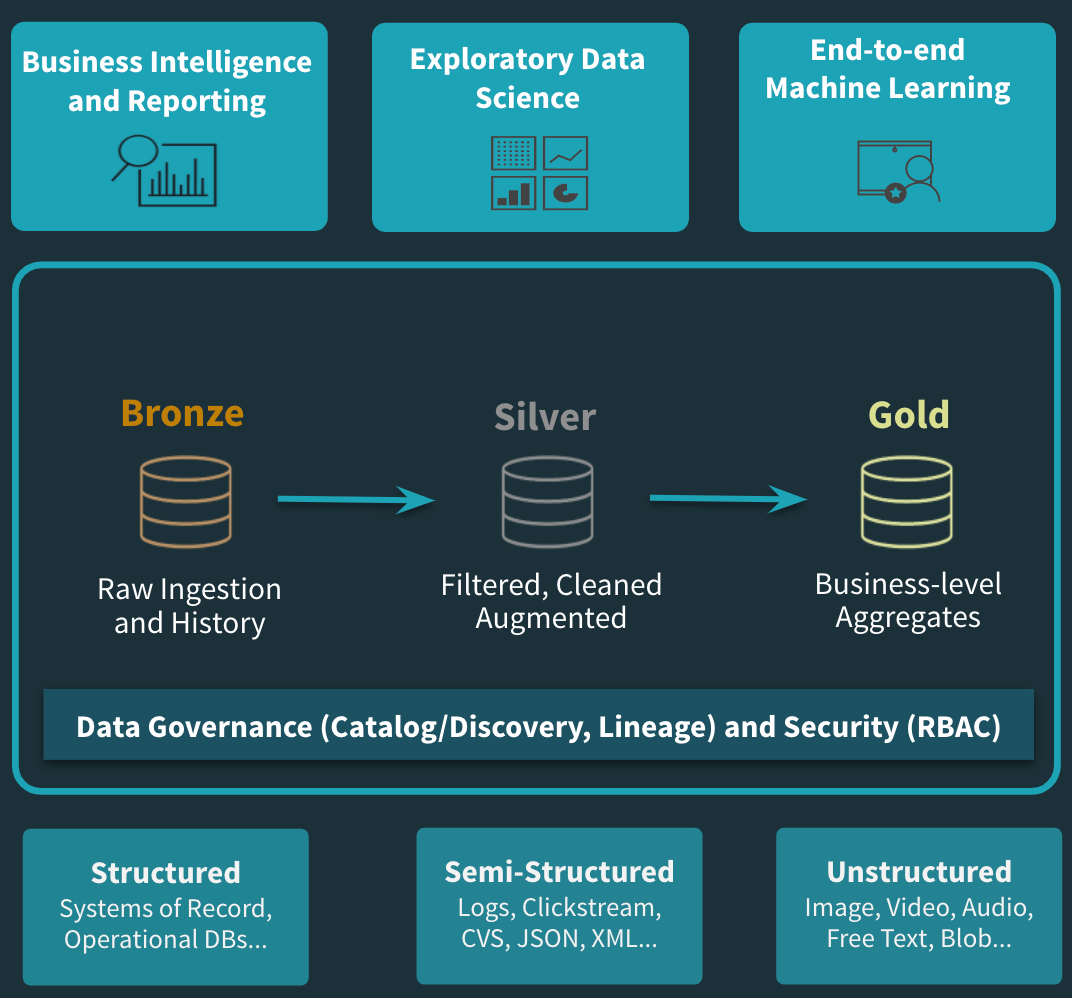
图3:云策划数据湖架构
因此,假设我们为这个经过管理的数据湖层提供了一种数据格式,它为我们提供了固有的可靠性和性能属性,并且数据完全处于组织的控制之下,那么现在需要一个允许您访问这种格式的查询引擎。我们认为这里的选择是Apache Spark,至少目前是这样。Apache Spark经过实战测试,支持ETL、流、SQL和ML工作负载。
因此,从Databricks的角度来看,这种数据格式就是Delta Lake。Delta Lake是由Linuxbob下载地址基金会维护的开源格式。你还会听到其他的名字——Apache Hudi和Iceberg。他们正试图解决数据湖所需的可靠性问题。然而,最大的不同是,在这一点上,三角洲湖的过程每月2.5艾字节.这是一种经过实战考验的数据格式,适用于财富500强企业的云数据湖,并在金融服务、广告技术、汽车和公共部门等所有垂直领域得到应用。
Delta Lake与Spark相结合,使您能够轻松地在数据湖管理阶段之间移动。事实上,您可以在原始层中增量地摄取传入的数据,并确保在ACID保证下看到它通过转换阶段一直移动到BI层。
我们Databricks意识到,这是许多组织正在寻求实现的愿景。因此,当你将Databricks视为统一数据分析平台时,你看到的是:bob体育客户端下载
- 一个开放的、统一的数据服务——我们是几个开源项目的最初创造者,包括Apache Spark、MLflow和Delta Lake。bob下载地址他们的能力深深融入到我们的产品中。
- 我们通过协作工作环境来满足数据科学家的需求。
- 事实上,我们通过端到端的ML工作流来训练、部署和管理模型,从而实现并加速了ML的生产过程。
- 在SQL/BI端,我们提供了一个本地SQL接口,使数据分析师能够使用熟悉的接口直接查询数据湖。我们还使用流行的无代码BI工具(如Tableau)优化了数据湖连接。
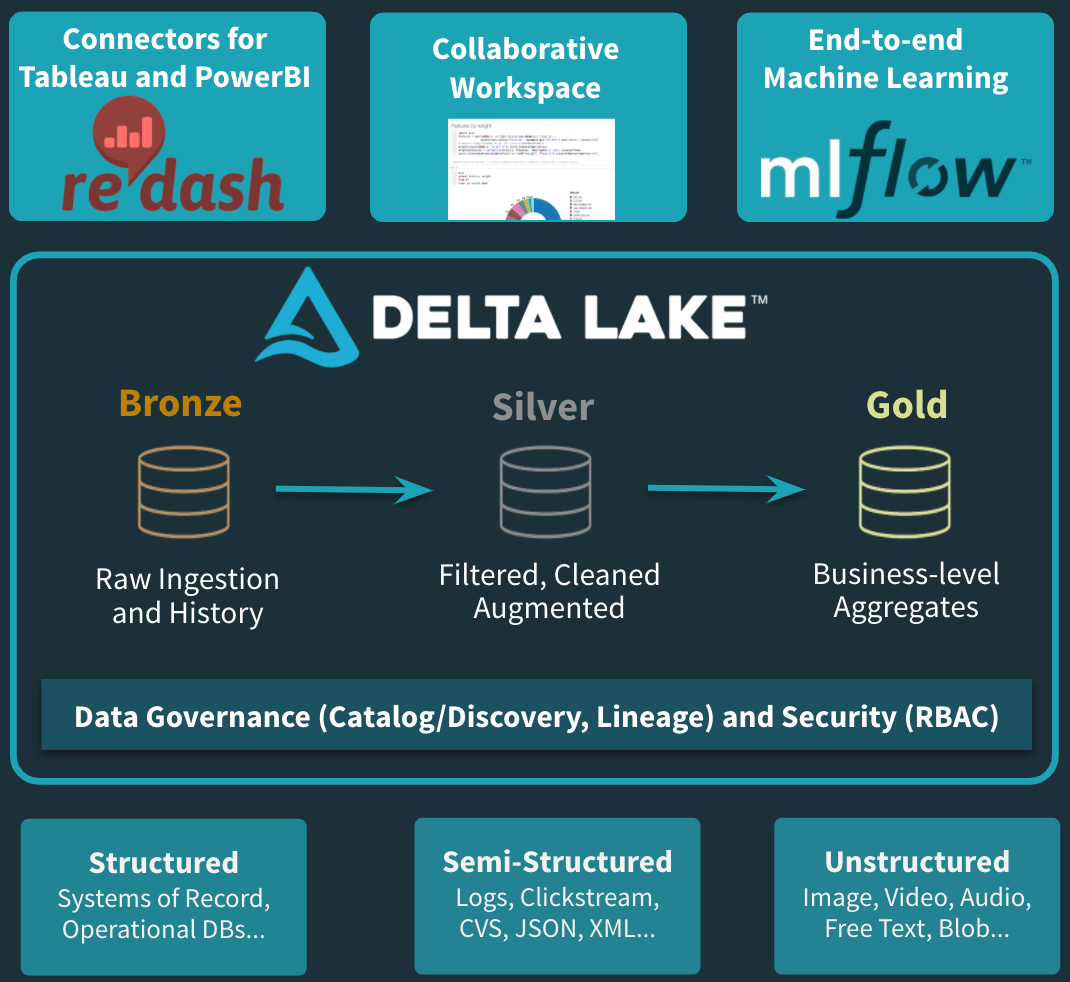
图5:以Databricks为中心的策划云数据湖解决方案
接下来是什么
我们将在这篇博客中继续讨论,当您希望在云中实现现代化时,为什么应该考虑使用数据湖。我们将重点介绍在您从传统数据仓库转向数据湖时需要考虑和了解的具体方面。