
声誉风险:通过构建风险分析引擎提高业务能力和培养快乐客户


2020年10月26日 在工程的博客
为什么声誉风险很重要?
说到“风险管理”这个术语,金融服务机构(FSI)已经看到了巴塞尔标准关于资本要求的指导和框架。但是,这些指南都没有提到声誉风险,多年来,组织缺乏一个明确的方法来管理和衡量声誉风险等非财务风险。鉴于最近的话题已经转向了环境、社会和治理(ESG)的重要性,企业必须弥合声誉与现实的差距,并确保流程到位,以适应利益相关者和客户不断变化的信念和期望。
对于FSI来说,声誉可以说是其最重要的资产。
对于金融机构来说,声誉可以说是其最重要的资产。例如,高盛著名的商业原则“我们的资产是我们的员工、资本和声誉。如果其中任何一项曾经被削弱,最后一项是最难恢复的。”例如,在商业银行中,根据消费者投诉和反馈采取行动的品牌能够比竞争对手更好地管理法律、商业和声誉风险。美国银行家出版这篇文章它重申了非金融风险,如声誉风险,是金融机构在快速变化的环境中解决的关键因素。
赢得客户信任的过程通常涉及通过多个不同渠道利用大量数据,以挖掘与可能对品牌声誉产生不利影响的问题相关的见解。尽管数据在培养更快乐的客户方面很重要,但大多数组织都难以构建一个平台,以解决与数据隐私、规模和模型治理相关的基本挑战,这些挑战在金融服务行业中很常见。bob体育客户端下载
在这篇博客文章中,我们将展示如何利用Databricks的统一数据分析平台的力量来解决这些挑战,解锁洞察力,并启动补救行动。bob体育客户端下载我们会讲到三角洲湖它是一个开源存储层,为数bob下载地址据湖带来可靠性和性能,并轻松地遵守GDPR和CCPA法规,无论是结构化数据还是非结构化数据。机器学习运行时而且管理MLflow也是Databricks统一分析平台的一部分,我们在这篇博bob体育亚洲版客中介绍了这个平台,bob体育客户端下载它使数据科学家和业务分析师能够利用流行的开源机器学习和治理框架来构建和部署最先进的机器学习模型。bob下载地址这种声誉风险的方法使金融服务机构能够衡量品牌认知,并将多个利益相关者聚集在一起,协同工作,以提高客户满意度和信任度。
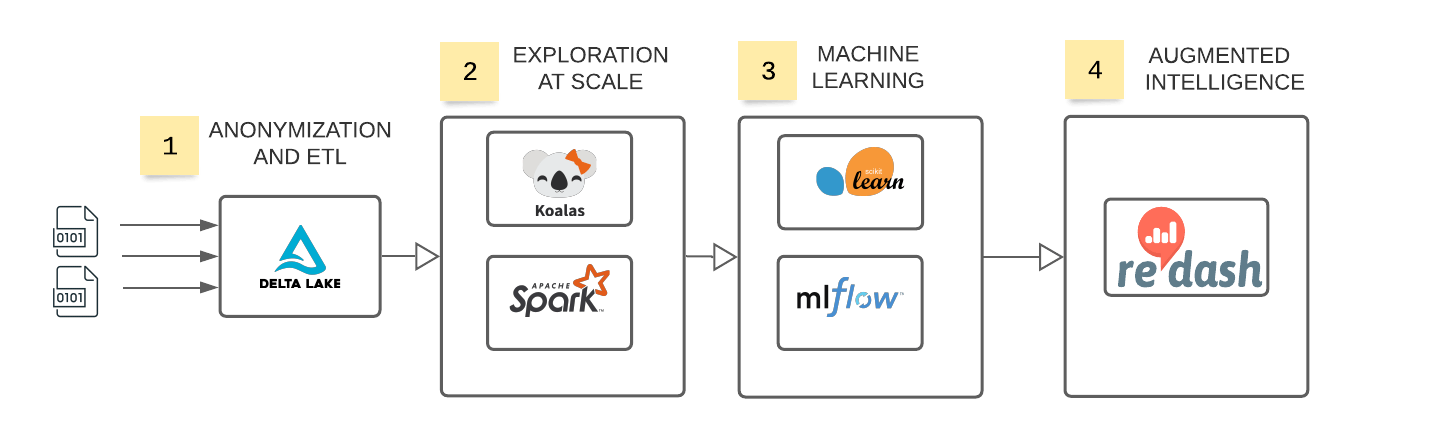
用于评估声誉风险的统一风险架构。
这篇博客文章引用了笔记本,其中涵盖了必须解决的多个数据工程和数据科学挑战,以有效地实现声誉风险管理实践的现代化:
- 使用Delta Lake实时接收匿名客户投诉
- 利用考拉探索大规模的客户反馈
- 利用人工智能和开源来实现积极的风bob下载地址险管理
- 使用SQL和商业智能(BI) /机器学习(ML)报告,将AI民主化到风险和倡导团队
利用云存储
与传统数据仓库相比,对象存储对于希望以更低的成本存储大量数据的组织来说是一个福音。但是,这带来了操作开销。当大量数据快速到达时,管理这些数据就成为一个巨大的挑战,因为经常损坏和不可靠的数据点会导致不一致,在以后的时间点很难纠正。
这一直是许多金融服务机构的主要痛点,他们已经开始了人工智能之旅,开发解决方案,以实现更快的洞察,并从正在收集的数据中获得更多信息。管理声誉风险需要组织付出巨大努力来衡量客户满意度和品牌认知。采用数据+人工智能方法来维护客户信任,需要能够支持以安全方式存储大量客户数据的基础设施,确保没有个人身份信息(PII)被利用,并完全符合PCI-DSS法规。虽然保护和存储数据只是一个开始,但对数百万个投诉进行大规模探索,并建立提供规范性见解的模型,是成功实施的关键。
作为一个统一的数据分析平台,Databricks不仅允许bob体育客户端下载摄取和处理大量数据,还允许用户大规模应用人工智能来揭示关于声誉和客户认知的见解。在这篇文章中,我们将从消费者金融保护局(CFPB),并建立数据管道,以更好地探索消费者使用Delta Lake和Koalas API的产品反馈。开源库将用于构建和部署机器学习模型,以便对各种产品和服务的客户投诉严重程度进行分类和衡量。通过统一批处理和流式处理,可以对投诉进行分类,并实时重新路由到适当的倡导团队,从而更好地管理投诉,提高客户满意度。
建立黄金数据标准
由于Databricks已经利用了云供应商提供的所有安全工具,Apache SparkTM和Delta Lake提供了额外的增强功能,如数据隔离和模式强制,以及时维护和保护数据质量。我们将使用Spark通过一个模式读入投诉数据,并将其持久化到Delta Lake。在此过程中,我们还提供了一个路径,将可能由于模式不匹配、数据损坏或语法错误而导致的坏记录保存到一个单独的位置,以便稍后对其一致性进行调查。
Df = spark.read.option (“头”,“真正的”).option (“分隔符”,",").option (“引用”,”“”).option(“逃离”、“”“).option (“badRecordsPath”,“/ tmp / complaints_invalid”). schema(模式). csv (“/ tmp / complaints.csv”)众所周知,像PII这样的敏感数据是一个主要的威胁,并增加了任何企业的攻击面。Pseudonymization,以及ACID事务功能和基于时间的数据保留强制,帮助我们在使用Delta Lake进行特定的基于列的操作时维护数据遵从性。然而,对于非结构化数据来说,这是一个真正的挑战,因为每个投诉都可能是音频通话、网络聊天、电子邮件的记录,并包含客户的名字和姓氏等个人信息,更不用说消费者被遗忘的权利(例如GDPR合规性)。在下面的例子中,我们演示了组织如何利用自然语言处理(NLP)技术来匿名化高度非结构化的记录,同时保留其语义价值(即替换名字的提及应该保留消费者投诉的潜在含义)。
使用像spaCy这样的开源库,组织可以提取特定的实体,例如客户和代理名称,还可以提取社会安全号码(SSN)、帐号和其他PII(例如下面示例中的名称)。

Databricks的声誉风险框架如何使用Spacy突出显示实体的示例。
在下面的代码中,我们将展示如何启用基于自然语言处理技术的简单匿名化策略用户定义函数(UDF)。
defanonymize_record(原来,nlp):Doc = nlp(原文)为X在doc.ents:如果(X.label_ = =“人”):替换(X.text,“John Doe”)返回原始@pandas_udf (“字符串”)def匿名化(csi:迭代器(pd。系列)) ->迭代器[pd.]系列:只加载一次空间模型spacy.cli.download (“en_core_web_sm”)NLP = space .load(“en_core_web_sm”)#提取组织的一批内容为cs在csi:收益率cs。地图(λX: anonymize_record(X, nlp)通过NLP理解每个单词(例如名称)的语义值,组织可以很容易地从非结构化数据中混淆敏感信息,如下例所示。

通过Databricks的声誉风险评估方法,可以应用更高级的实体识别模型来混淆来自非结构化数据集的敏感信息。
这种方法可以很好地扩展,可以实时处理多个数据流,也可以进行批处理,以持续更新和维护目标Delta表中最新信息的状态,供数据科学家和业务分析人员使用以进行进一步分析。
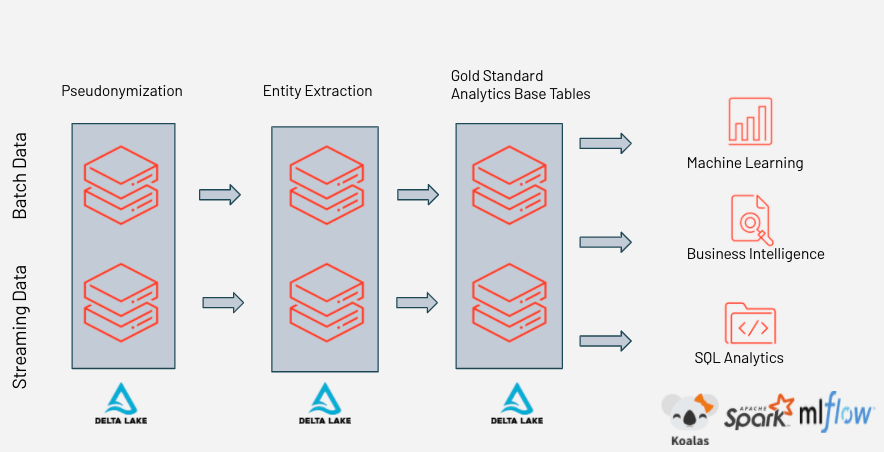
Databricks实时提高数据控制和质量,使数据工程师、数据科学家和业务分析师能够在统一的数据分析平台上协作。bob体育客户端下载
这种实用的数据科学方法表明,组织需要打破传统数据科学活动和日常数据操作之间的孤岛,将所有角色置于同一个数据和分析平台中。bob体育客户端下载
衡量品牌认知和客户情绪
有了更好的声誉管理系统,金融服务机构可以通过跟踪和隔离客户对机构提供的某些产品和服务的反馈来建立卓越的客户体验。这不仅有助于发现问题领域,还有助于内部团队更加积极主动,帮助陷入困境的客户。为了更好地理解数据,数据科学家传统上对大型数据集进行采样,以生成更小的数据集,以便使用他们熟悉的工具进行更深入的研究(有时在笔记本电脑上),例如熊猫dataframe和Matplotlib可视化。为了最大限度地减少跨平台数据移动(从而最大限度地减少与移动数据相关的风险),并最大限bob体育客户端下载度地提高大规模探索性数据分析的效率和有效性,考拉可以使用数据科学家最熟悉的语法(类似Pandas)来探索所有数据。
在下面的示例中,我们将使用简单的类似panda的语法探索jp摩根大通的所有抱怨,同时仍然使用底层的分布式Spark引擎。
进口databricks.koalas作为ksKDF = spark.read.table(“complaints.complaints_anonymized”) .to_koalas ()Jp_kdf = kdf[kdf]“公司”) = =摩根大通公司。]jp_kdf [“产品”] .value_counts () .plot (“酒吧”)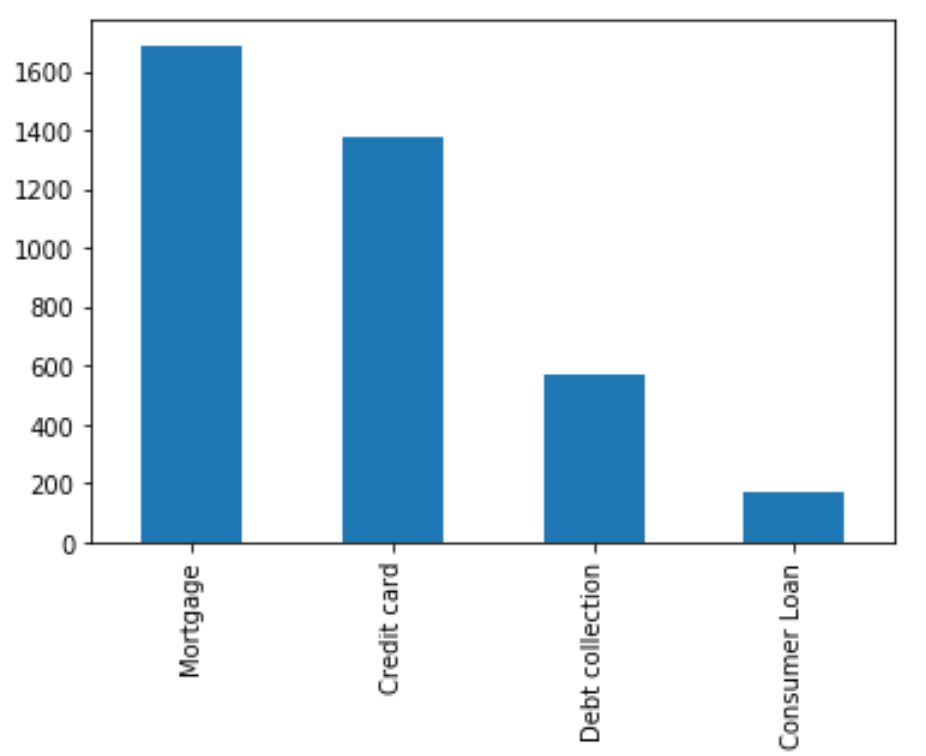
使用Koalas API在多个产品中可视化投诉数量的样本图表
为了进一步分析,我们可以对客户投诉进行术语频率分析,以确定客户在特定FSI的所有产品中报告的主要问题。我们一眼就能看出与受害者身份盗窃和不公平追债有关的问题。
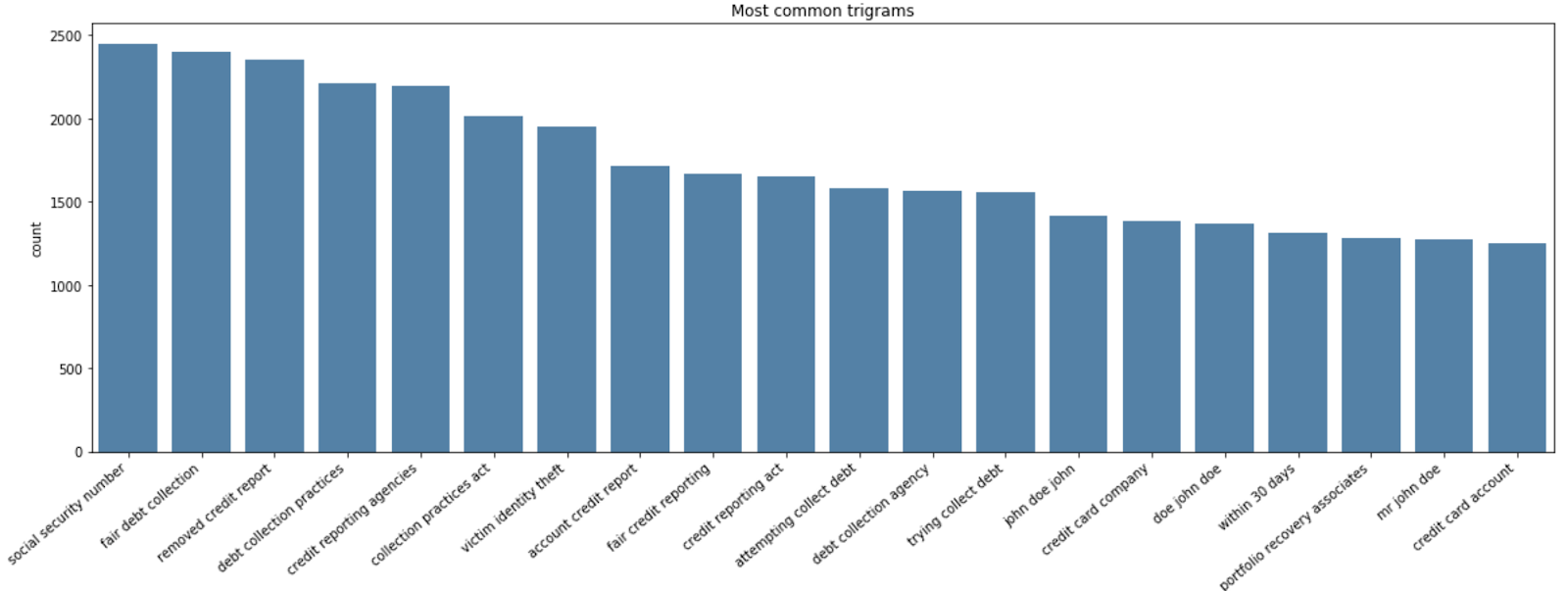
样本词频分析图表可视化消费者投诉中提到的最具描述性的n-gram,通过Databricks方法进行声誉风险分析。
我们可以使用词汇云进一步挖掘消费贷款和信用卡等单个产品,以更好地了解客户在抱怨什么。
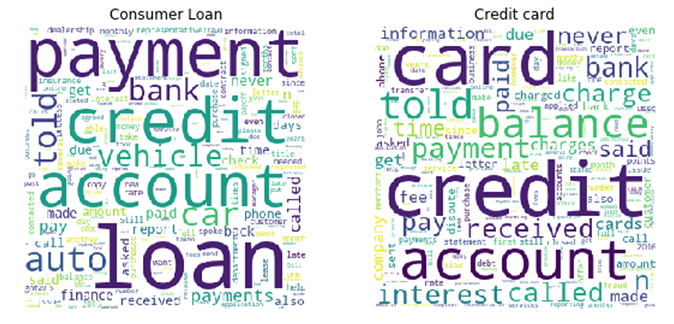
通过词云可视化来理解消费者投诉,通过Databricks方法进行声誉风险分析。
虽然探索性数据分析对于商业智能(BI)和反应性分析非常有用,但实时理解、预测和分类直接客户反馈、公共评论和其他社交媒体互动非常重要,以建立信任,实现有效的客户服务,并衡量个人产品性能。虽然许多解决方案使我们能够收集和存储数据,但在构建声誉管理系统时,必须能够无缝地分析和处理数据,以便在统一的平台中实现关键见解。bob体育客户端下载
为了验证我们的消费者数据的预测潜力,从而确认我们的数据集非常适合ML,我们可以通过使用来识别投诉之间的相似性t-分布式随机邻居嵌入(t-SNE)如下例所示。尽管一些消费者投诉在可能的类别上可能有重叠(安全贷款和无抵押贷款的关键字都相似),但我们可以观察到不同的集群,这表明机器可以很容易地学习模式。
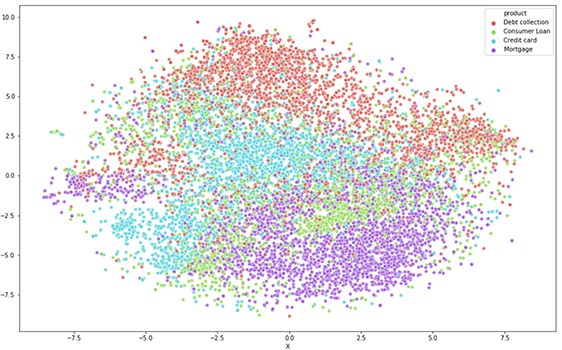
通过t-SNE可视化验证消费者投诉的预测潜力。
上面的图表再次证实了一种模式,使我们能够对投诉进行分类。潜在的重叠也表明,一些投诉很容易被最终用户或代理错误分类,导致投诉管理系统不佳,客户体验较差。
机器学习和增强智能
Databricks的ML运行时包提供了对可靠和高性能的开源框架的访问,包括scikit-learn、XGboost、Tensorflow、Jon Snow Labs NLP等,帮助数据科学家更好地专注于通过数据交付价值,而不是花费时间和精力管理基础设施、包和依赖项。
在本例中,我们构建了一个简单的scikit-learn管道,将投诉分为我们在t-SNE图中看到的四大类产品,并通过对以前有争议的索赔进行训练来预测投诉的严重程度。Delta Lake为您的数据提供可靠性和性能,MLFlow为您的见解提供效率和透明度。每个ML实验都将被跟踪,超参数将自动记录在一个公共的地方,从而产生高质量的工件,可以信任并执行。
进口mlflow进口mlflow.sklearn与mlflow.start_run (run_name =“complaint_classifier”):#训练管道,自动记录所有参数管道。fit (X_train y_train)y_pred = pipeline.predict(X_test)Accuracy = accuracy_score(y_pred, y_test)#将管道和指标记录到mlflowmlflow.sklearn.log_model(管道,“管道”)mlflow.log_metric (“准确性”、准确性通过将所有实验记录在一个地方,数据科学家可以很容易地找到最佳模型拟合,使操作团队能够检索已批准的模型(作为其工作的一部分)风险管理模型过程),并将这些见解呈现给最终用户或下游过程,将模型生命周期过程从几个月缩短到几周。
#加载模型作为火花UDFModel_udf = mlflow. pyfuncs .spark_udf(spark,“模型:/投诉/生产”)#加载模型作为一个SQL函数火花.udf.注册(“分类”, model_udf)#分类投诉在真正的时间火花.readStream.表格(“complaints_fsi.complaints_anonymized”).withColumn(“产品”model_udf (“投诉”)虽然我们现在可以应用ML实时自动分类和重新路由新的投诉,但在SQL代码中利用UDF的可能性使业务分析人员能够在查询数据以实现可视化的同时直接与我们的模型交互。
选择received_date,分类(投诉)作为产品,数(1)作为总计从complaints.complaints_anonymized集团通过received_date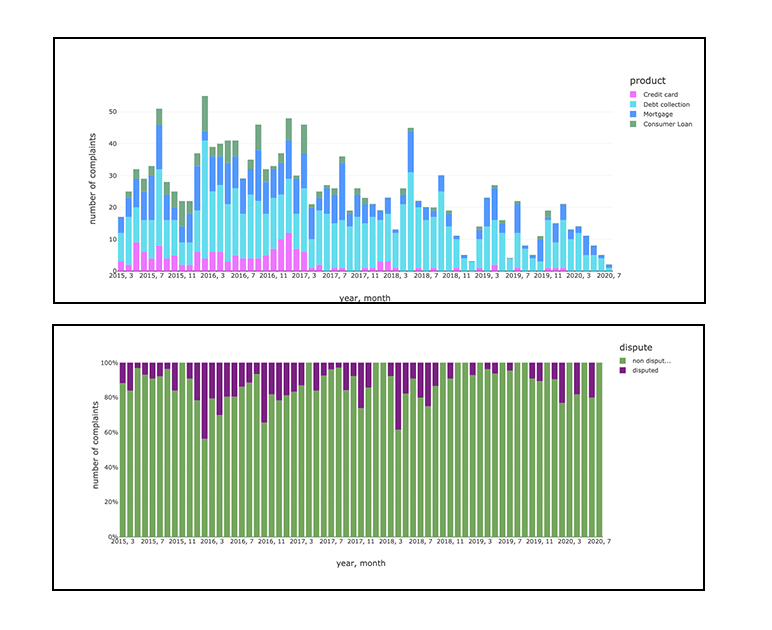
声誉风险评估的数据方法,通过人工智能增强BI,为声誉风险管理提供更描述性的方法来分析投诉和纠纷。
这可以使我们产生进一步的可操作的见解使用Databricks的笔记本可视化或SQL分析这是一个易于使用的基于web的可视化和仪表板工具,在数据库里,使用户能够探索,查询,可视化和共享数据。使用简单的SQL语法,我们可以很容易地查看给定位置一段时间内不同产品的投诉。如果在流上实现,这可以为倡导团队提供快速的见解,以采取行动并响应客户。例如,我们从客户那里看到的典型投诉包括身份盗窃和数据安全,这可能对品牌声誉产生巨大影响,并导致监管机构处以巨额罚款。这类事件可以通过建立本文所述的管道来轻松管理,这有助于企业管理声誉风险,将其作为企业战略的一部分,以满足客户的需求和不断变化的数字环境。
将声誉风险纳入公司治理战略
在这篇博客中,我们展示了企业如何利用Databricks的统一分析平台来构建一个风险引擎,该引擎可以安全实时地分析客户反馈,以便及早评估声誉风险bob体育亚洲版。bob体育客户端下载虽然该博客强调了来自CFPB的数据,但这种方法可以应用于其他数据来源,如社交媒体、直接客户反馈和其他非结构化来源。这使得数据团队能够在构建声誉风险平台方面进行协作和快速迭代,该平台可以随着数据量的增长而扩展,同时利用市场上最好的开源人工智能工具。bob体育客户端下载
试试Databricks上的以下笔记本,利用人工智能的力量来降低声誉风险,并与我们联系,了解更多关于我们如何在类似的用例中帮助fsi的信息。BOB低频彩