
通过抛弃数据中心来加速开发人员

由Scribd平台工程总监R Tyler Croy撰写的客座博客bob体育客户端下载
人们往往不会兴奋关于数据平台。bob体育客户端下载它经常被认为很像道路基础设施:没有人会考虑从A点到B点对他们有多重要,除非情况非常糟糕。想象一下,当我开始听到用户说:“哇,这太棒了”,或“我等不及我的整个团队采用它了”,或“我们真的很兴奋!”这种热情并没有降低迁移项目的挑战性,但肯定会让它变得更愉快。
在Scribd在美国,我们有一个“传统的数据平台”已经有一段时间了:Hadoopbob体育客户端下载混合了HDFS和少量的Hive。随着时间的推移,业务的需求已经发生了变化,我们现在需要更多的机器学习,更多的实时数据处理,以及对团队协作提供新数据产品的更多支持;我们需要比“传统数据平台”更好的东西。bob体育客户端下载我们的新数据平台结合了气流bob体育客户端下载、Databricks、Delta Lake和AWS Glue Catalog,这是一套强大的工具,已经显著提高了我们的开发速度和协作能力。从“旧的”到“新的”的过渡中充斥着成功和挫折,因为我们重新平台化并摆脱了复杂性和技术债务。bob体育客户端下载
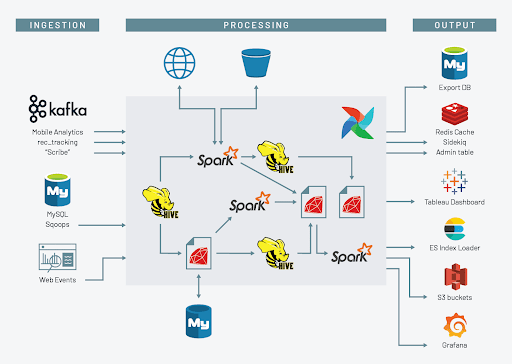
遗留数据平台不仅在我们部署的技术bob体育客户端下载上是传统的,而且还部署在固定的数据中心基础设施上。数据中心中的一组静态机器在批处理工作负载高峰期间快速地处理数据,然后在空闲时浪费金钱和能源。随着公司和我们需求的增长,数据平台的“高峰”变得越来越明显,对开发人员来说也更加痛苦。bob体育客户端下载有些人会在出去吃午饭之前,或者在一天结束的时候抛出问题或工作,希望他们能在回来时得到结果。在我到达公司后不久,我注意到一个特别严重的反模式:一些机器学习工程师会准备他们的数据集,将它们转储到个人AWS S3桶中,启动具有gpu能力的实例,训练他们的模型,然后在月底向他们的经理提交报销请求。
如果开发者的恐怖故事还不够,操作上的事情可以说更糟!许多传统的数据平台技术很难与Chef等自动化工bob体育客户端下载具相结合,因此我们的遗留数据平台缺乏适当的管理,而我们的其他生产基础设施则享受着这种管理。每次我们向环境中添加更多的机器时,根据请求的不同,这个过程将需要一两天的时间。因此,我们只在真正需要节点时,或者当驱动器和系统故障需要它时,才会添加节点。
我们传统的数据平台既浪费了开发人员的时间,也bob体育客户端下载浪费了基础设施工程师的时间。我一想到,如果所有这些有才华的人都致力于推进我们业务目标的项目,我们会取得怎样的成就,就会不寒而栗。
现代化我们的数据基础设施:评估选项
到2019年年中,Scribd聘请了一个“核心平台”团队,建立了一个“实时数据平bob体育客户端下载台”,以及一个由数据科学家和机器学习工程师组成的全新团队。投资于遗留数据平台的各方一致同意,我们必须“走向云端”。bob体育客户端下载再加上全公司范围内迁移到AWS的计划,我们的潜在选择清单相对较短。我们需要一个数据平台,它能很好地在bob体育客户端下载AWS上运行,依赖于S3,能够很好地运行我们的查询和Spark作业,能够为开发人员提供一些自助式服务,并且能够支持我们甚至还没有想到的新的机器学习工作负载。
我看到的选项可以分为两类:
- “看起来像一个传统的数据平台,但有S3,而且在云中!bob体育客户端下载”(不是很有说服力).
- 砖
因为我们知道我们的存储选项将涉及AWS S3一些我们已经开始研究我们庞大的数据仓库和工作负载如何与S3互操作。对于数据平台的使用bob体育客户端下载,S3是一个很好的工具,但它并不像它的名字所暗示的那么简单。S3的最终一致性特性可能会导致通过类似表格的接口(例如Hive)访问Parquet文件的许多问题。有些问题是可以解决的S3Guard但是附加的架构复杂性让我们有点厌倦。大约在这个时候,我们很幸运地注意到开源三角洲湖砖。三角洲湖的初步评估让我们大吃一惊;我们找到了存储层。
Delta Lake实际上最终成为了Databricks的门户,这并不是我们最初的计算平台评估的一部分。bob体育客户端下载随着我们对Databricks的研究越来越深入,我们发现了两个杀手级特性:
- 砖的笔记本对于开发人员和分析师来说,这是一个杀手级的功能,他们迄今为止必须通过共享查询来进行复制和粘贴色调.
- 的在Databricks中优化Spark运行时,这有助于更快地执行查询和作业,帮助我们尽快为开发人员提供结果。
将Spark工作负载迁移到云端:计算成本和收益
在AWS中,时间直接等同于金钱。在AWS中越早关闭机器,所花的钱就越少。在Databricks销售团队的帮助下,我能够为现有的Spark工作负载提出一个成本模型,前提是我们要直接将它们分叉到AWS上,而不需要进行重大更改。他们声称对大多数传统Spark工作负载进行了30-50%的优化。“保守地说,我认为是30%,”他们说。出于好奇,我重构了我的成本模型,以考虑Databricks的价格和潜在的Spark作业优化。在调整数字之后,我发现以17%的优化率,Databricks将大大降低AWS的基础设施成本,甚至可以支付Databricks平台本身的成本。bob体育客户端下载
在我们最初的评估之后,我已经被Databricks提供的特性和开发人员速度的提高所说服。当我在我的模型中计算数字时,我知道我买不起不采用Databricks!
在生产中
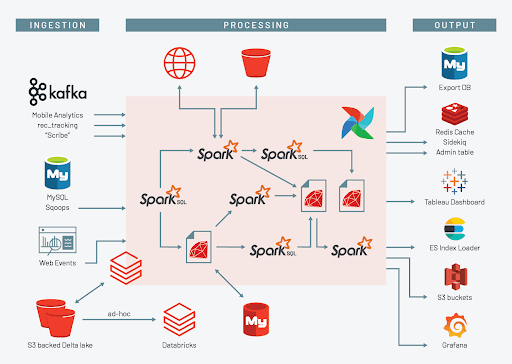
从我们基于数据中心的数据平台到Databricks的道路很长,我们仍在前进。bob体育客户端下载到今天为止,我们已经将整个数据仓库回填到Delta Lake中,这一迁移方便地解决了令人震惊的问题小文件问题在HDFS中。我们有一点自定义工具,它可以在我们开始转移一些更重量级的批处理任务时,保持数据从数据中心到Delta Lake的同步。尽管批处理任务迁移还有很长的路要走,但我们已经有了直接部署在Databricks之上的新项目:
- 曾经由Hue和Hive提供服务的临时内部用户查询正在被强大的功能所取代三角洲缓存启用集群。那些以前大部分时间都在顺化度过的人,已经通过共享笔记本电脑兴奋地与同事合作了。
- 新的Spark Streaming/Delta Lake项目已经在生产中。以前的工作量不可能的已经开发和部署了。对于一些流入Kafka的数据流,我们部署了Spark Streaming应用程序,将数据直接带入Delta Lake,在那里,作业和用户可以在数据创建的几分钟内查询数据。对于其中一些工作负载,用户以前必须等待24小时的批处理周期才能完成,但现在他们可以在2-3分钟内从Delta Lake获得新的生产数据。
当许多人看到这一点时,他们的想法立即转向“我可以将哪些数据转换为流以获得更实时的洞察?”突然,在团队路线图中出现了多个项目,其中包括“为X生成数据流”或“处理来自Y的数据流”。
对我来说,对于一个交付数据基础设施和工具的团队来说,成功在于你的用户既乐于使用基础设施来回答他们的问题,也在于他们开始构想用平台来解决全新的问题。bob体育客户端下载一言以蔽之,我已经对我们的结果感到满意了!
然而,一切都不像我想的那么美好:我们的管理政策仍然落后于不同团队在采用Databricks时所拥有的繁荣。我们已经为开发人员提供了很棒的工具来解决他们的问题,但是我们还没有适当的政策来防止这些用户启动过大或价格过高的集群。这样做的能力存在于平台中,但是当考虑到一些EC2浪费的成本与人们的时间相比时,bob体育客户端下载我们现在错误地选择了尽快将集群送到人们手中。
下次做得更好
将一个bob体育客户端下载庞大的数据基础设施重新平台化并不容易。迄今为止,我们最大的痛点都是自己造成的。我们在Hive和基于Hive的查询上进行了大量的投资,并提供了各种自定义udf,这些udf都需要迁移到Spark和Spark SQL中。我们编写了一些工具来帮助我们自动将Hive查询和模板转换为Spark SQL,它成功地自动转换了~80%的Hive工作负载。另外的20%我们必须手动转换,这是一项令人沮丧的工作。
迁移过程还发现了比我自豪地承认的更多的技术债务。大量Spark工作负载仍然依赖于Spark 1(!),这些任务不使用Hive的表接口,而是直接与HDFS对话(!),并且测试原始开发人员忽略编写任何测试的大型批处理任务(!)。
就我个人而言,我期待着有一天,第一个加入的新员工永远不必看到遗留数据平台。bob体育客户端下载他们不会高兴地意识到,曾经有一段时间,你不得不复制和粘贴查询片段到聊天中,等待明天的新数据,或者在完成工作时浪费几个小时。
在即将到来的会议上,我们将听到R. Tyler Croy谈论Scribd向流媒体云数据平台的转变bob体育客户端下载SPARK + AI峰会.免费注册在这里.
Scribd还在招聘有才华的远程工程师,以帮助改变世界的阅读方式BOB低频彩tech.scribd.com