
砖和Informatica加速发展和智能数据管道成套数据治理


对组织的价值分析和机器学习是很好理解的。我们最近的CIO的调查显示,90%的机构投资分析,机器学习和人工智能。但我们也指出,最大的障碍是获得正确的数据在正确的位置和正确的格式。所以我们与Informatica使组织能够获得更多成功启用新方法发现,摄取和准备数据分析。
摄入数据直接进入三角洲湖
从混合数据源获取大量数据到一个数据湖在某种程度上这是可靠和high-performant是很困难的。数据集往往是倾倒在非托管数据湖泊,没有想到一个目的。数据是扔进湖泊没有一致的格式,从而无法读取和附加。数据也可以破坏的过程中写数据湖,写可以失败,留下部分数据集。
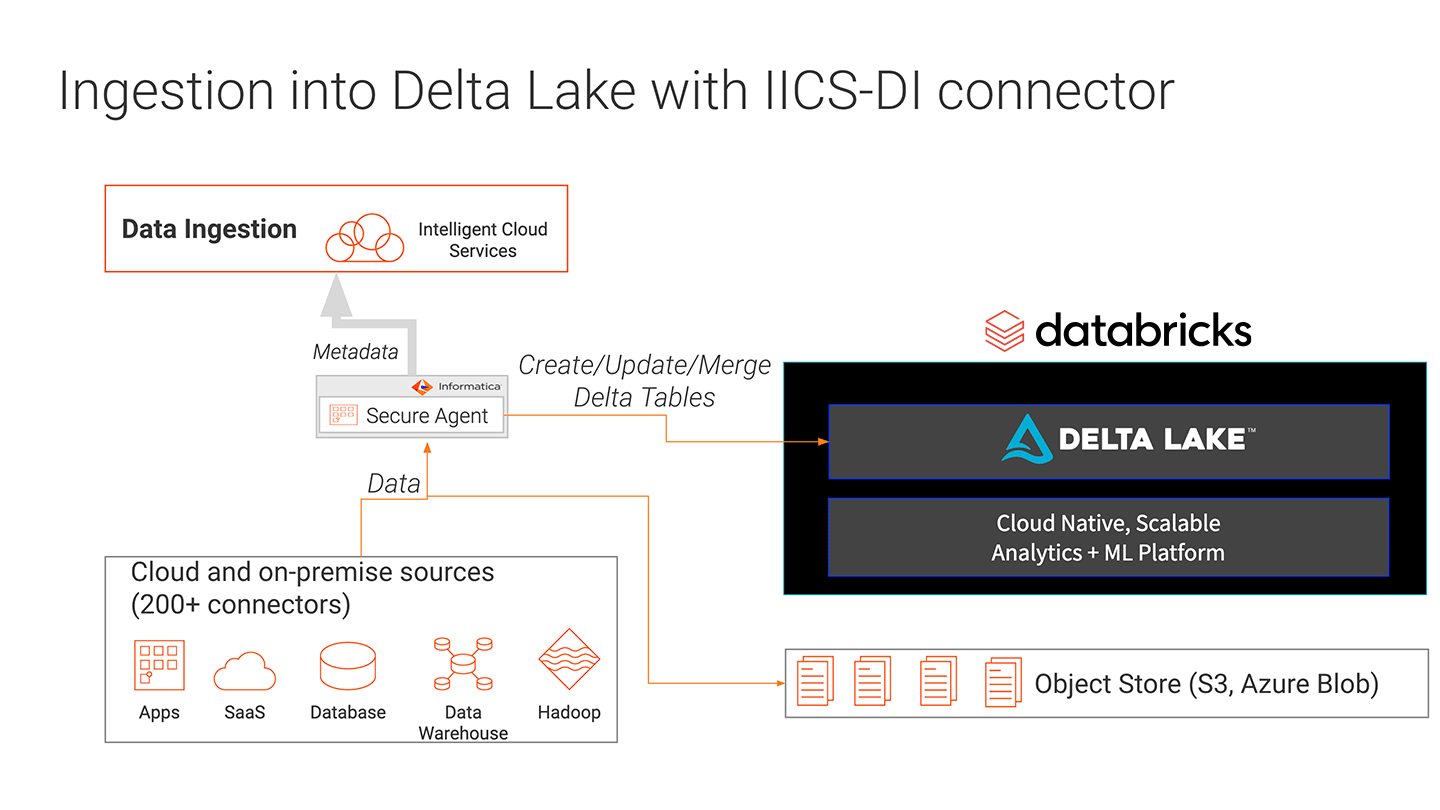
Informatica数据工程集成(一些)使摄入来自多个数据源的数据。通过将一些与三角洲湖,摄入可以发生与三角洲湖的好处。ACID事务确保写完成,或退出,如果他们失败了,没有留下工件。三角洲湖模式执行确保所需的数据类型是正确的和列,从而防止错误数据导致数据损坏。之间的集成Informatica一些和三角洲湖使工程师能够摄取数据到一个数据湖与高可靠性和性能。
准备
每个组织有限的资源格式的数据分析。确保数据集可用于毫升模型需要耗费时间来创建复杂的转换。没有足够的高度熟练的数据工程师可用代码先进的大规模数据ETL转换。此外,ETL代码很难排除或修改。
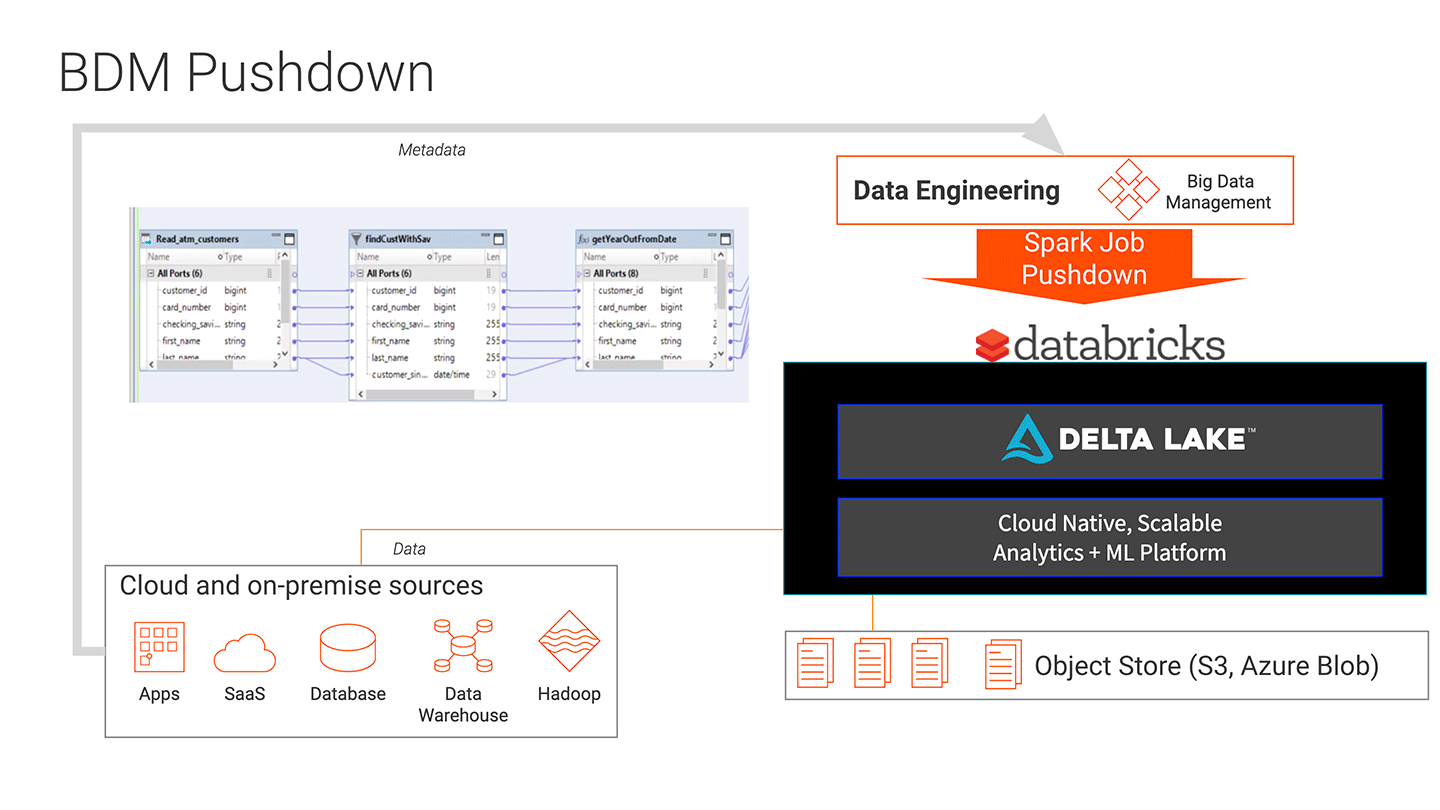
Informatica大数据管理的集成(BDM)和砖统一分析平台更易于创建大容量数据管道进行大规模数据。bob体育亚洲版bob体育客户端下载BDM的拖放界面,降低了酒吧团队创建数据转换的需要编写代码来创建数据管道。BDM的易于维护和修改管道可以利用的高容量可伸缩性砖,推动工作的进行处理。结果是更快和更低的成本开发大容量数据的机器学习项目的管道。管道创建和部署增加5倍,管道更容易维护和故障诊断。
发现
找到合适的机器学习的数据集是很困难的。数据科学家浪费宝贵的时间寻找合适的数据集的模型来帮助解决关键问题。他们不能确定哪些数据是完整和正确格式化,并正确地验证了使用正确的数据集。
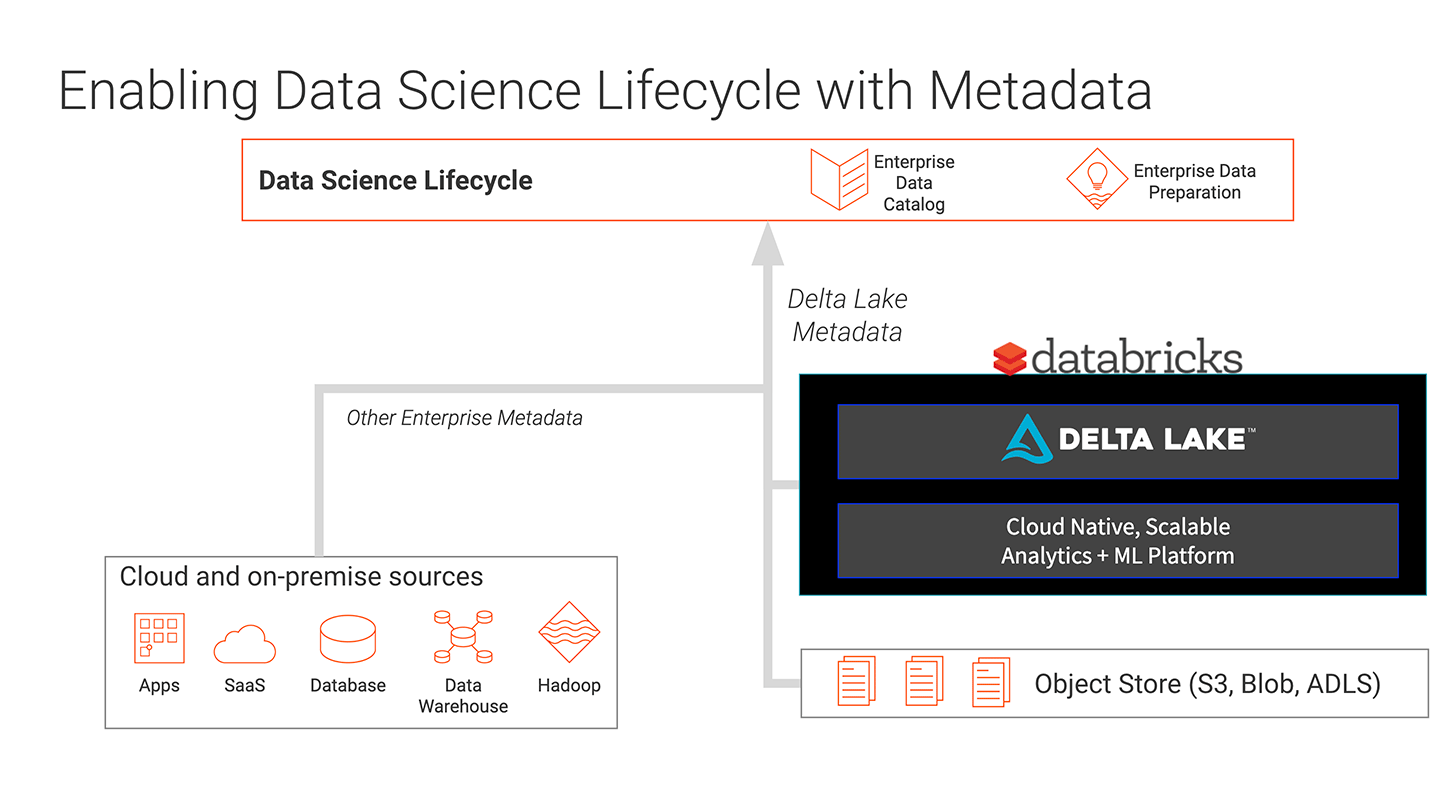
Informatica企业数据的集成目录(EDC)砖统一的分析平台,数据科学家现在可以找到正确的数据用于创建模型和执行分析。bob体育亚洲版bob体育客户端下载Informatica克莱尔引擎使用人工智能和机器学习来自动发现数据和数据科学家做出明智的建议。数据科学家可以发现、验证,提供他们的快速分析模型,大大降低了时间的价值。砖可以运行毫升模型在无限的规模,使高影响力的见解。在三角洲湖和EDC现在可以跟踪数据,这使得企业数据目录的一部分。
血统
跟踪数据处理分析的血统已经几乎不可能。数据工程师和科学家不能提供任何的证明血统显示的数据是从哪里来的。当数据处理创建模型,确定哪个版本的一个数据集,模型,甚至分析框架和库使用已经变得如此复杂,已经超出了我们的能力手动跟踪。
的集成Informatica EDC,三角洲湖和MLflow砖内部运行,数据科学家可以核实数据从源的血统,跟踪数据的确切的版本在三角洲湖,并跟踪和繁殖模型、框架和库用于处理数据分析。这种能力来追踪数据科学决策一路回源为组织提供了一个强大的方法能够审计和繁殖所需的结果证明合规。
我们是兴奋这些集成和影响他们对组织成功,使他们能够自动化数据管道,这些管道提供更好的见解。有关更多信息,注册这个网络研讨会https://www.informatica.com/about-us/webinars/reg/keys-to-building-end-to-end-intelligent-data-pipelines-for-ai-and-ml-projects_358895.html。